标签:没有 this expec 技术 建议 通过 ensure cti 下标
在java中,集合这一数据结构应用广泛,应用最多的莫过于List接口下面的ArrayList和LinkedList;
我们先说List,
1 public interface List<E> extends Collection<E> { 2 //返回list集合中元素的数量,若数量大于Integer.MAX_VALUE,则返回Integer.MAX_VALUE 3 int size(); 4 5 //判读集合内是否没有元素,若没有元素返回true 6 boolean isEmpty(); 7 8 //判断集合内是否包含指定的元素o 9 boolean contains(Object o); 10 11 //以适当的序列,返回该集合元素中的一个迭代器 12 Iterator<E> iterator(); 13 14 //返回一个数组,该数组包含该集合中所有的元素(以从first到last的顺序) 15 Object[] toArray(); 16 17 //把集合中的元素放到数组a中,并返回 18 <T> T[] toArray(T[] a); 19 20 21 //向集合末尾中添加一个元素 22 boolean add(E e); 23 24 //从集合中删除第一个出现的元素o 25 boolean remove(Object o); 26 27 28 //判断集合中是否包含 指定集合c中的所有元素 29 boolean containsAll(Collection<?> c); 30 31 //将指定集合c中的所有元素都追加到 集合的末尾 32 boolean addAll(Collection<? extends E> c); 33 34 //将指定集合c中的所有元素都插入到 集合中,插入的开始位置为index 35 boolean addAll(int index, Collection<? extends E> c); 36 37 //将指定集合c中的所有元素从本集合中删除 38 boolean removeAll(Collection<?> c); 39 40 //本集合和 集合c的交集 41 boolean retainAll(Collection<?> c); 42 43 //清除集合中的元素 44 void clear(); 45 46 //比较指定对象o和本集合是否相等,只有指定对象为list,size大小和本集合size一样,且每个元素equal一样的情况下,才返回true 47 boolean equals(Object o); 48 49 50 int hashCode(); 51 52 //返回指定位置index的元素 53 E get(int index); 54 55 //将元素element设置到集合的index位置(替换) 56 E set(int index, E element); 57 58 //将元素element插入到集合的index位置 59 void add(int index, E element); 60 61 //移除指定位置index的元素 62 E remove(int index); 63 64 //返回指定对象o在本集合中的第一个索引位置 65 int indexOf(Object o); 66 67 //返回指定对象o在本集合中的最后一个索引位置 68 int lastIndexOf(Object o); 69 70 //返回一个ListIterator的迭代器 71 ListIterator<E> listIterator(); 72 73 //从指定位置index开始返回一个ListInterator迭代器 74 ListIterator<E> listIterator(int index); 75 76 //返回从位置fromIndex开始到位置toIndex结束的子集合 77 List<E> subList(int fromIndex, int toIndex); 78 }
下面我们看一看ArrayList,ArrayList是基于数组的方式来实现数据的增加、删除、修改、搜索的。
ArrayList内部维护者两个变量:
//该数组缓存者集合中的元素,集合的容量就是该数组的长度,elementData用transient修饰,说明在序列化时,数组elementData不在序列化范围内。 private transient Object[] elementData; //集合的大小 (集合中元素的数量) private int size;
我们再看一看ArrayList的构造器:
/** *构造一个指定容量initialCapacity的空的集合, *super() 是调用AbstractList的默认构造器方法,该方法是一个空的方法, *然后判断传入的参数initialCapacity不能小于0,否则就直接抛出非法参数异常; *最后直接创建了一个长度为initialCapacity的数组对象,并将该对象赋值给当前实例的elementData属性,用以存放集合中的元素。 */ public ArrayList(int initialCapacity) { super(); if (initialCapacity < 0) throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity); this.elementData = new Object[initialCapacity]; } /** *构造一个默认的容量为10的空的集合,我们平时最经常使用的List<T> list = new ArrayList<T>();是默认创建了容量为10的集合。 */ public ArrayList() { this(10); }
/**
*构造一个包含了指定集合c中的所有元素的集合,该集合中元素的顺序是以集合c的迭代器返回元素的顺序。
*/ public ArrayList(Collection<? extends E> c) { elementData = c.toArray(); size = elementData.length; // c.toArray might (incorrectly) not return Object[] if (elementData.getClass() != Object[].class) elementData = Arrays.copyOf(elementData, size, Object[].class); }
从上面的源码中我们看到,先将c.toArray()方法的返回值赋值给elementData,将elementData.length赋值给size, 然后进行了一个判断 if(elementData.getClass() != Object[].class),若为真,则调用Arrays.copyOf()方法创建一个新Object[]数组,将原来elementData中的元素copy到新建的Object[]数组中,最后将新建的数组赋值给elementData。
我们看一下Arrays.copyOf()方法的源码:
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) { T[] copy = ((Object)newType == (Object)Object[].class) ? (T[]) new Object[newLength] : (T[]) Array.newInstance(newType.getComponentType(), newLength); System.arraycopy(original, 0, copy, 0, Math.min(original.length, newLength)); return copy; }
如果newType类型为Object[].class的话,则直接创建一个长度为newLength的Object数组,否则使用Array.newInstance(Class<?> componentType, int length)方法创建一个元素类型为newType.getComponentType() (该方法返回数组中元素的类型)类型的,长度为newLength的数组,这是一个native方法,然后使用System.arraycopy() 这个native方法将original数组中的元素copy到新创建的数组中,并返回该数组。
我们注意 c.toArray might (incorrectly) not return Object[],按理说一个c.toArray()返回的是一个Object[]类型,其getClass()返回的也一定是Object[].class,那为什么还要进行逐个判断呢? 可真实情况真的是这样吗?我们看下面的示例:
//定义一个父类Animal public class Aniaml { } //定义Animal的子类Person public class Person extends Aniaml{ private int id; private String name; private Date birthday; public Person(int id, String name, Date birthday) { this.id = id; this.name = name; this.birthday = birthday; } public static void main(String[] args) { test1(); test2(); test3(); } public static void test1(){ Person[] persons = {new Person(100,"lewis",new Date()),new Person(100,"lewis",new Date())}; //class [Lcom.lewis.guava.Person; Person的数组类型 System.out.println(persons.getClass()); Aniaml[] aniamls = persons; //class [Lcom.lewis.guava.Person; Person的数组类型 System.out.println(aniamls.getClass()); //class com.lewis.guava.Person Person类型 System.out.println(aniamls[0].getClass()); //java.lang.ArrayStoreException animals[]数组中实际存储的是Peron类型,当运行时放入非Person类型时会报错ArrayStoreException aniamls[0] = new Aniaml(); } public static void test2(){ List<String> list = Arrays.asList("abc"); //class java.util.Arrays$ArrayList 由此可见该类型不是ArrayList类型 System.out.println(list.getClass()); Object[] objects = list.toArray(); //class [Ljava.lang.String; 返回的是String数组类型 System.out.println(objects.getClass()); //java.lang.ArrayStoreException: java.lang.Object 当我们将一个Object放入String数组时报错ArrayStoreException objects[0] = new Object(); } public static void test3(){ List<String> dataList = new ArrayList<String>(); dataList.add(""); dataList.add("hehe"); //class java.util.ArrayList System.out.println(dataList.getClass()); Object[] objects1 = dataList.toArray(); //class [Ljava.lang.Object; System.out.println(objects1.getClass()); objects1[0]="adf"; objects1[0]=123; objects1[0]=new Object(); } }
我们由上面test2()方法可知,一个List,调用list.toArray()返回的Object数组的真实类型不一定是Object数组([Ljava.lang.Object;),当我们调用 Object[] objArray = collection.toArray(), objArray并不一定能够存放Object对象,所以上面的源码中对这种情况进行了判断。
我们接着看ArrayList中的方法:
add(E),当我们添加数据的时候,会遇到的一个问题就是:当里面的数组满了,没有可用的容量的怎么办?
/** *插入对象,首先将size+1,产生一个minCapacity的变量,调用ensureCapacity(minCapacity)方法保证数组在插入一个元素时有可用的容量,然后将元素e放到数组elementData的size位置,最后将size+1 */ public boolean add(E e) { ensureCapacity(size + 1); // Increments modCount!! elementData[size++] = e; return true; } /** *必要时数组的扩容 (如果想调整ArrayList的容量增长策略,可以继承ArrayList,override ensureCapacity()方法即可),
首先将modCount+1,modeCount表示修改数组结构的次数(维护在父类AbstractList中),如果入参minCapacity大于目前数组elementData的容量,则将容量扩展到 (oldCapacity * 3)/2 + 1,
若此时容量仍然小于 minCapacity,则直接将minCapacity设置为最新的容量,
最后使用Arrays.copyof()方法将原来elementData中元素copy到新的数组中,并将新数组赋值给elementData. */ public void ensureCapacity(int minCapacity) { modCount++; int oldCapacity = elementData.length; if (minCapacity > oldCapacity) { Object oldData[] = elementData; int newCapacity = (oldCapacity * 3)/2 + 1; if (newCapacity < minCapacity) newCapacity = minCapacity; // minCapacity is usually close to size, so this is a win: elementData = Arrays.copyOf(elementData, newCapacity); } }
/** *在指定下标Index处插入元素element,首先判断下标index的参数是否有效(不能小于0,不能大于size),否则抛出IndexOutOfBoundsException异常,然后调用ensureCapacity(size+1)要确保数组中有足够的容量来插入数据,
*然后调用System.arraycopy()方法, 从index下标开始,将elementData数组元素copy到 从index+1开始的地方,copy的长度为size-index,这样index下标处的位置就空了出来,然后将元素element放到下标为index处的位置,最后将size++.
*我们看到使用这个方法相比add(E),多了一步数组元素的复制的代价。 */ public void add(int index, E element) { if (index > size || index < 0) throw new IndexOutOfBoundsException( "Index: "+index+", Size: "+size); ensureCapacity(size+1); // Increments modCount!! System.arraycopy(elementData, index, elementData, index + 1, size - index); elementData[index] = element; size++; }
/** *将元素element设值到下标为index处,返回原来index处的旧值。 */ public E set(int index, E element) { RangeCheck(index);
//获取index下标的旧值 E oldValue = (E) elementData[index];
//设值新的元素element到index处 elementData[index] = element; return oldValue; } //边界检查,index越界的话,抛出异常IndexOutOfBoundsException private void RangeCheck(int index) { if (index >= size) throw new IndexOutOfBoundsException( "Index: "+index+", Size: "+size); }
/** *将指定集合c中的元素按照其迭代器返回的顺序追加到本集合中,只要将任何一个元素插入到集合中都会返回true */ public boolean addAll(Collection<? extends E> c) { Object[] a = c.toArray(); int numNew = a.length; //确保(size+a.length)有足够的容量去插入新元素 ensureCapacity(size + numNew); // Increments modCount //将数组a的内容追加到elementData数组的最后 System.arraycopy(a, 0, elementData, size, numNew); size += numNew;
//只要插入的元素个数>0就返回true return numNew != 0; }
我们再看删除的方法
/** *删除指定元素o,分为两种情况,若指定元素o为null,则遍历当前的elementData数组,如果某一个下标index上面的值为null(==),则调用方法fastRemove(int)快速删除该元素,然后返回true
*若指定元素o不为0,则遍历elementData数组,若某一个下标index处的元素和指定元素o 进行equals 为true的话,则调用fastRemove(int)快速删除该元素,然后返回true
*由下面的源码可知,只能删除第一个匹配的元素。 */ public boolean remove(Object o) { if (o == null) { for (int index = 0; index < size; index++) if (elementData[index] == null) { fastRemove(index); return true; } } else { for (int index = 0; index < size; index++) if (o.equals(elementData[index])) { fastRemove(index); return true; } } return false; } /** *快速删除指定下标index的元素,不做边界检查(该方法时private的) */ private void fastRemove(int index) { modCount++; int numMoved = size - index - 1; if (numMoved > 0)
//里面进行了数组元素的移动,将index后面的元素往前复制一位 System.arraycopy(elementData, index+1, elementData, index, numMoved);
//将数组elementData中最后一个位置置为null,以便释放已用,让gc 回收 elementData[--size] = null; // Let gc do its work }
/** *删除指定下标index处的元素,该方法相比remove(Object o)方法,多了一个边界检查,但是少了元素的查找过程,因此性能更好一些。 */ public E remove(int index) {
//对入参index做边界检查 RangeCheck(index); modCount++;
//取出index位置的元素 E oldValue = (E) elementData[index]; int numMoved = size - index - 1; if (numMoved > 0)
//进行数组元素的移动 System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // Let gc do its work //返回原来index位置的旧元素 return oldValue; }
元素的搜索:
/** *获取指定下标index处的元素,先进行边界检查,然后直接返回elementData数组中对应位置index处的元素。 */ public E get(int index) { RangeCheck(index); return (E) elementData[index]; }
/** *判断集合中是否包含指定元素o,调用indexOf(Object o)方法实现 */ public boolean contains(Object o) { return indexOf(o) >= 0; } /** *返回指定元素o在数组elementData首次出现的下标,这里也是分为两种情况:
*1.指定元素o为null 2.指定元素o不为null,在查询元素的过程中,o为null,使用 == 比较,o不为null,使用equals比较,若找到了该元素,则返回其在数组elementData中的下标index,若找不到这返回-1. */ public int indexOf(Object o) { if (o == null) { for (int i = 0; i < size; i++) if (elementData[i]==null) return i; } else { for (int i = 0; i < size; i++) if (o.equals(elementData[i])) return i; } return -1; }
与indexOf(Object o)方法类似的是 lastIndexOf(Object o)方法,不同的是 后者返回的是最后一次出现指定元素o的位置下标。
public int lastIndexOf(Object o) { if (o == null) { for (int i = size-1; i >= 0; i--) if (elementData[i]==null) return i; } else { for (int i = size-1; i >= 0; i--) if (o.equals(elementData[i])) return i; } return -1; }
我们再看一下ArrayList的迭代器方法如何实现的:
/** *该方法是有ArrayList的父类AbstractList持有的,返回的是一个Itr对象 */ public Iterator<E> iterator() { return new Itr(); }
我们看看Itr是个什么鬼:
/** *Itr 实现了Iterator接口,是AbstractList中的一个内部类。 */ private class Itr implements Iterator<E> { //当前迭代器指向的数组中元素的下一个元素的位置 int cursor = 0; int lastRet = -1; int expectedModCount = modCount; //每次调用hasNext方法时,判断当前指向的数组中的位置和数组大小是否相等,若不等则返回true(说明还有值),若相等则返回false(说明已经迭代到了数组的末尾了,没有元素了) public boolean hasNext() { return cursor != size(); } //调用next方法是,先调用checkForComodification()方法,判断是否有其他线程对集合大小做出了有影响的动作;
//然后调用get方法获取相应位置的元素,若获取不到,则抛出IndexOutOfBoundsException异常,在捕获到该异常后,调用checkForComodification()方法,
//检测modcount若== expectedModCount(没有其他线程对集合大小做出了有影响的操作),则抛出NoSuchElementException,若modcount != expectedModCount,则抛出ConcurrentModificationException
public E next() { checkForComodification(); try { E next = get(cursor); lastRet = cursor++; return next; } catch (IndexOutOfBoundsException e) { checkForComodification(); throw new NoSuchElementException(); } } public void remove() { if (lastRet == -1) throw new IllegalStateException(); checkForComodification(); try { AbstractList.this.remove(lastRet); if (lastRet < cursor) cursor--; lastRet = -1; expectedModCount = modCount; } catch (IndexOutOfBoundsException e) { throw new ConcurrentModificationException(); } } //若modCount和期望的expectedModCount不相等,说明在迭代过程中,有其他的线程对集合大小产生了影响的动作(新增、删除),此时抛出异常ConcurrentModificationException final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); } }
我们在看一个方法trimToSize
/** *将elementData数组的容量 缩小为该集合实际包含的元素数量 */ public void trimToSize() { modCount++; int oldCapacity = elementData.length; if (size < oldCapacity) { elementData = Arrays.copyOf(elementData, size); } }
使用ArrayList的注意事项:
1.ArrayList是基于数组的方式实现的,可以通过下标索引直接查找到指定位置的元素,因此查找效率高,但每次插入或删除元素,就要大量地移动元素,插入删除元素的效率低。
2.ArrayList在插入元素时,可能会进行数组的扩容,但是在删除元素时却不会减小数组的容量,如果希望减小数组的容量,可使用trimToSize方法,在查找元素要遍历数组时,对非 null元素使用equals方法,对null元素使用==。
3.扩充容量的方法ensureCapacity。ArrayList在每次增加元素(可能是1个,也可能是一组)时,都要调用该方法来确保足够的容量。当 容量不足以容纳当前的元素个数时,就设置 新的容量为旧的容量的1.5倍加1,如果设置后的新容量还不够,则直接新容量设置为传入的参数(也就是所需的容 量),而后用Arrays.copyof()方法将元素拷贝到新的数组。从中 可以看出,当容量不够时,每次增加元素,都要将原来的元 素拷贝到一个新的数组中,非常之耗时,也因此建议在事先能确定元素数量的情况下,才使用ArrayList,否则建议使用 LinkedList
4.ArrayList不是线程安全的。
接着我们看下LinkedList,LinkedList是基于双向链表的方式来实现的,双向链表就是集合中的每个元素都知道其前面的一个元素的位置和它后的一个元素位置。
在LinkedList中,使用一个内部类Entry来表示集合中的节点,元素的值赋值给element属性,节点的next属性指向下一个节点,节点的previous属性指向前一个节点。
private static class Entry<E> {
//element存放数据 E element;
//next属性指向当前节点的下一个节点 Entry<E> next;
//previous属性指向当前节点的上一个节点 Entry<E> previous; Entry(E element, Entry<E> next, Entry<E> previous) { this.element = element; this.next = next; this.previous = previous; } }
/** *维护了一个header节点,header节点的element属性为null,previouse属性为null,next属性为null,并且header节点是不存储数据的 */ private transient Entry<E> header = new Entry<E>(null, null, null); //size表示集合包含的元素个数 private transient int size = 0; /** * 构造一个空的集合,将header节点的next属性、previous属性都指向header节点,这样形成了一个双向链表的闭环 */ public LinkedList() { header.next = header.previous = header; }
新增操作
/** *追加指定的元素e到集合尾部,其效果和方法 addLast(E e)是一致的,都是调用addBefore(e,header)方法。 */ public boolean add(E e) { addBefore(e, header); return true; } /** *将数据e 插入到元素entry前面(private级别,LinkedList内部调用,意味着不能直接在自己的应用程序中调用此方法,但是可以利用反射API来间接的调用(好想没必要这样做)) */ private Entry<E> addBefore(E e, Entry<E> entry) { //创建一个新节点newEntry,newEntry.element属性设置为e,newEntry.next属性设置为entry,newEntry.previous属性设置为entry.previous Entry<E> newEntry = new Entry<E>(e, entry, entry.previous); ///将newEntry.previous节点的next属性指向newEntry本身 newEntry.previous.next = newEntry; //将newEntry.next节点的previous属性指向newEntry本身 newEntry.next.previous = newEntry; //将集合大小size + 1 size++; //集合大小影响次数modCount + 1 modCount++; //返回新创建的节点 return newEntry; }
下面我们看一下新增一个节点,在集合中的直接视图情况:
假设我们一开始创建一个LinkedList时,只有一个header节点(不存储数据的),如下图所示:
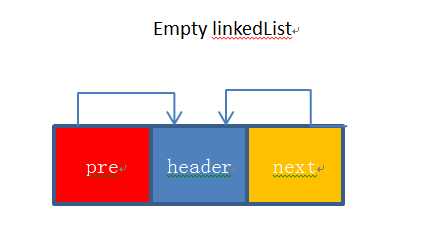
有一个元素A1插入到了header的前面。
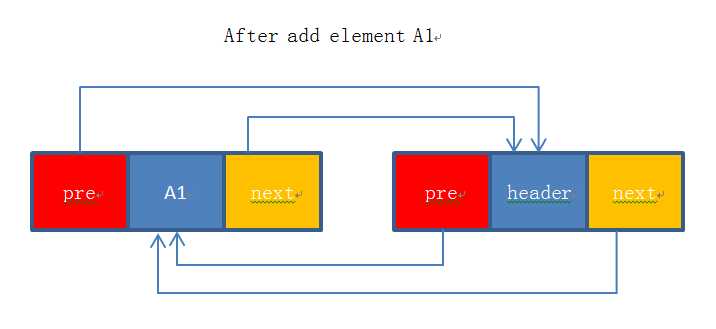
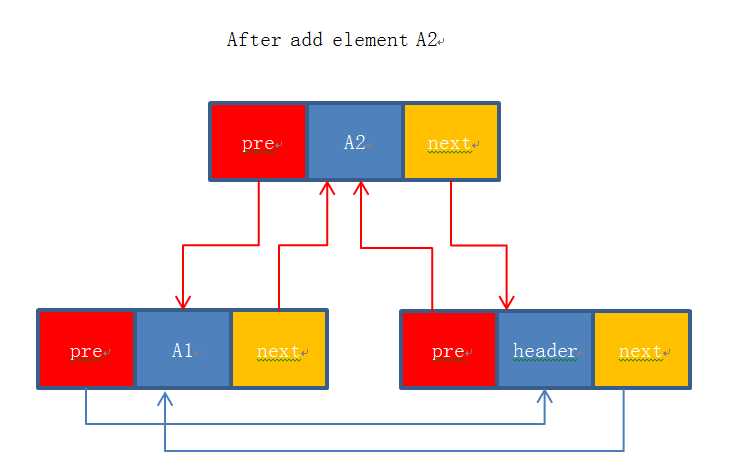
现在要插入一个元素A2,在执行完下面代码后,
Entry<E> newEntry = new Entry<E>(A2, header, header.previous); //将newEntry的next属性指向header节点,newEntry.previous属性指向header.previous指向的节点(A1);
newEntry.previous.next = newEntry; //将newEntry.previous节点(A1)的next属性指向newEntry,即将A1.previous属性指向A2。
newEntry.next.previous = newEntry;//将newEntry.next节点(header)的previous属性指向newEntry,即将header.previous属性指向A2.
图形变成了下面的样子:
我们看一下LinkedList的一个带参的构造函数:
/** *以指定集合c的迭代器返回的节点顺序,构造一个包含指定集合c中所有元素的集合 */ public LinkedList(Collection<? extends E> c) { //这里this()调用了LinkedList的无参构造器,使header.next=header.previous=header,即此时仅有一个header节点 this(); //调用addAll(c)方法 addAll(c); } /** *将指定集合c中所有的元素,按照其迭代器返回的顺序全部追加到集合的结尾。 */ public boolean addAll(Collection<? extends E> c) { return addAll(size, c); } /** *将指定集合c中所有的元素,按照其迭代器返回的顺序,从指定的位置index开始全部插入到集合中。 */ public boolean addAll(int index, Collection<? extends E> c) { //对参数index做边界检查,无效抛出IndexOutOfBoundsException if (index < 0 || index > size) throw new IndexOutOfBoundsException("Index: "+index+ ", Size: "+size); //将集合c 转换为数组 Object[] a = c.toArray(); //获取数组的长度 int numNew = a.length; //若数组的长度为0,说明数组是空的,没有可以插入的元素,则直接返回false if (numNew==0) return false; //程序走到这,说明有可以插入的数据了,集合大小肯定会改变,因此modCount+1 modCount++; //如果入参index==size,则将header节点设置为后继节点successor,否则调用entry(int)方法求出位置index的节点,并将该节点设置为后继节点successor. Entry<E> successor = (index==size ? header : entry(index)); //获取后继节点successor的前驱节点predecessor Entry<E> predecessor = successor.previous; //循环数组中的元素,进入数据的插入 for (int i=0; i<numNew; i++) { //创建一个新节点e,将数组a的第i个元素a[i]作为新节点e的element属性,successor作为e的next节点,predescessor作为e的previous节点 Entry<E> e = new Entry<E>((E)a[i], successor, predecessor); //将predecessor的next属性指向新节点e predecessor.next = e; //由于还要进行后续的插入,因此将新节点e设置为前驱节点predecessor,以便继续循环 predecessor = e; } //在循环数组中的元素插入完成后,将sucessor.previous属性指向predecessor节点,此时已经完成了双向链表的闭环了。 successor.previous = predecessor; //将集合大小size 增加numNew个 size += numNew; return true; } /** *返回指定位置index的节点 */ private Entry<E> entry(int index) { //对参数index做边界检查,无效抛出IndexOutOfBoundsException if (index < 0 || index >= size) throw new IndexOutOfBoundsException("Index: "+index+ ", Size: "+size); //将头结点header设置为e Entry<E> e = header; //如果入参index小于数组大小size的一半,即index< size/2的话,则从前往后查找(从下标为0开始,到index),否则从后往前查找(从下标为size开始,到index+1) if (index < (size >> 1)) { for (int i = 0; i <= index; i++) //从前往后遍历 e = e.next; } else { for (int i = size; i > index; i--) //从后往前遍历 e = e.previous; } //找到后返回 return e; }
其他的添加操作:
/** *追加指定元素e到集合的结尾,效果和调用add(E e)方法是一样的(都是调用方法addBefore(e,header)),只是该方法没返回值 */ public void addLast(E e) { addBefore(e, header); } /** *将指定元素e插入到集合的开始位置,调用方法addBefore(e,header.next)实现 */ public void addFirst(E e) { //这里插入在header.next节点的前面,因此可以认为是集合的开始位置 addBefore(e, header.next); } /** *在指定位置index处插入指定的元素e */ public void add(int index, E element) { //若index== size,即要追加到集合的结尾处,即插入到header之前;否则调用entry(int)方法获取index处的节点,插入到该节点之前 addBefore(element, (index==size ? header : entry(index))); } /** *将元素element设值到位置为index处(即将原index处的值替换为element),并返回原来index处的值 */ public E set(int index, E element) { Entry<E> e = entry(index); E oldVal = e.element; e.element = element; return oldVal; } /** *追加元素e到集合结尾 */ public boolean offer(E e) { return add(e); } /** *将元素e插入集合的开始位置,调用addFirst(E e)方法实现 */ public boolean offerFirst(E e) { addFirst(e); return true; } /** *将元素e插入集合的结束位置,调用addLast(E e)方法实现 */ public boolean offerLast(E e) { addLast(e); return true; } /** *将元素e推入(push)进入栈 (LinkedList也可以当做栈使用) */ public void push(E e) { addFirst(e); }
删除操作:
/** *删除指定元素在集合中的第一个出现的节点(下标index最小的) */ public boolean remove(Object o) { //分为两种情况:1.入参o 为null,使用== 比较 2.入参o不为null,使用equals比较 //若o == null if (o==null) { //从前往后开始遍历(从header节点的下一个节点开始) for (Entry<E> e = header.next; e != header; e = e.next) { //使用 == 比较 if (e.element==null) { //找到第一个为null的节点,调用方法remove(Entry e)删除该节点 remove(e); //返回true,表示删除成功 return true; } } } else { //从前往后开始遍历(从header节点的下一个节点开始) for (Entry<E> e = header.next; e != header; e = e.next) { //使用 equals 比较 if (o.equals(e.element)) { //找到第一个equals为true的节点,调用方法remove(Entry e)删除该节点 remove(e); //返回true,表示删除成功 return true; } } } //返回false,表示没有找到要删除的元素o return false; } /** *删除指定的节点e(该方法是私有的,供LinkedList内部调用,不对外提供),与ArrayList的删除操作而言,LinkedList的删除操作不需要进行数组的移动,而是仅仅改变下被删除元素的前后两元素的指向而已,因此LinkedList删除操作效率更高。 */ private E remove(Entry<E> e) { //判断节点是否是头结点header,我们知道header节点不存储数据,若入参e被发现实header节点,则抛出NoSuchElementException异常。 if (e == header) throw new NoSuchElementException(); //获取节点e的存储的数据result E result = e.element; //将节点e的前一个节点的next属性直接指向e的下一个节点(断开e.previous.next=e这个链条) e.previous.next = e.next; //将节点e的下一个节点的previous属性直接指向e的前一个节点(断开e.next.previous=e这个链条) e.next.previous = e.previous; //将e的next属性和previous属性都设置为null(断开e对前一个节点和后一个节点的指向的链条) e.next = e.previous = null; //将e的本身存储的数据元素element置为null e.element = null; //size 大小减一 size--; //由于remove操作影响了集合的结构(大小),因此modCount+1 modCount++; //返回被删除节点的存储数据result return result; }
清除集合中的所有节点clear()方法:
/** *清除集合中所有的节点 */ public void clear() { //获取header节点的下一个节点e Entry<E> e = header.next; //只要遍历一遍集合即可 while (e != header) { //e节点的下一个节点next Entry<E> next = e.next; //将节点e的next属性和previous属性都设置为null(不指向任何节点) e.next = e.previous = null; //将节点e的存储数据元素置为null e.element = null; //将next节点设置为当前循环的节点e e = next; } //循环删除了集合中的所有有数据的元素后,只保留header节点(不存储数据),并组成一个闭环 header.next = header.previous = header; //由于清理了所有的元素,此时size 设置为0 size = 0; //此操作涉及到了集合结构大小的改变,因此modCount + 1 modCount++; }
查找元素在集合中的下标indexOf()方法和lastIndexOf()
/** *返回元素o在集合中首次出现的位置下标 */ public int indexOf(Object o) { //维护一个位置索引index用了记录变量了多少个元素,从0开始 int index = 0; //若o == null,则使用 == 比较,从前往后 if (o==null) { for (Entry e = header.next; e != header; e = e.next) { if (e.element==null) //找到了第一个为null的,则返回其下标index return index; //在当前循环中没有找到,则将下标index+1 index++; } } else { //若o不为 null,则使用 equals 比较,从前往后 for (Entry e = header.next; e != header; e = e.next) { if (o.equals(e.element)) //找到了第一个equals为truel的,则返回其下标index return index; //在当前循环中没有找到,则将下标index+1 index++; } } //遍历完整个链表没有找到的话,返回-1 return -1; } /** *返回元素o在集合中最后出现的位置下标 */ public int lastIndexOf(Object o) { //维护一个位置索引index用了记录变量了多少个元素,从最大size开始 int index = size; //若o == null,则使用 == 比较,从后往前 if (o==null) { for (Entry e = header.previous; e != header; e = e.previous) { //先将index-1 index--; if (e.element==null) //找到了第一个遇见为null的,则返回其下标index return index; } } else { //若o != null,则使用 equals 比较,从后往前 for (Entry e = header.previous; e != header; e = e.previous) { //先将index-1 index--; if (o.equals(e.element)) //找到了第一个遇见equals为truel的,则返回其下标index return index; } } //在遍历集合一遍之后,没有找到元素的,返回-1 return -1; }
判断集合是否包含某个元素:
/** *判断集合是否包含指定元素o,调用indexOf(Object o)来实现的 */ public boolean contains(Object o) { return indexOf(o) != -1; }
/** *获取指定位置index的元素,调用entry(int )来实现,entry(int)这个方法上面已讲过 */ public E get(int index) { return entry(index).element; }
将集合转换为数组:
/** *按照集合中从前往后的顺序,返回一个包含集合中所有元素的数组 */ public Object[] toArray() { //创建一个同集合大小一样的Object数组result Object[] result = new Object[size]; //维护一个下标索引i,用以表示数组 元素的下标 int i = 0; //从前往后遍历链表 for (Entry<E> e = header.next; e != header; e = e.next) //将遍历节点e的存储数据放到数组result中的第i个位置,然后i+1 result[i++] = e.element; //返回result数组 return result; } /** *给一个数组a,返回一个数组(数组元素按照集合从前往后的顺序排列),该数组包含了集合中的所有元素 */ public <T> T[] toArray(T[] a) { //若数组a的长度不足以装入所有的集合元素,则使用Array.newInstance()这一方法创建一个size大小,元素类型为数组a的元素类型的数组,并将该数组赋值给a if (a.length < size) a = (T[])java.lang.reflect.Array.newInstance( a.getClass().getComponentType(), size); int i = 0; Object[] result = a; //从前往后遍历链表,依次将集合中的元素放入数组a中 for (Entry<E> e = header.next; e != header; e = e.next)
//将遍历节点e的存储数据放到数组result中的第i个位置,然后i+1 result[i++] = e.element; //若数组a的长度超过了size,则将数组a中size下标置为null if (a.length > size) a[size] = null; //返回数组a return a; }
LinkedList的迭代器:
/** *返回一个list的迭代器,直接new了一个内部类ListItr来实现的 */ public ListIterator<E> listIterator(int index) { return new ListItr(index); } /** *ListItr是LinkedList的私有内部类,实现了ListIterator接口 */ private class ListItr implements ListIterator<E> { //将header设置为最近一次返回的节点 private Entry<E> lastReturned = header; //下一次要返回的节点 private Entry<E> next; //下次要返回节点的下标 private int nextIndex; //将目前修改集合结构大小的记录数赋值给expectedModCount ,用于比较在一个线程遍历集合时,是否有其他的线程在同步修改该集合结构 private int expectedModCount = modCount; //入参为int的构造函数 ListItr(int index) { //对入参进行边界检查,如无效则抛出IndexOutOfBoundsException if (index < 0 || index > size) throw new IndexOutOfBoundsException("Index: "+index+ ", Size: "+size); //若index < size/2,则从前往后遍历nextIndex从0到index-1 if (index < (size >> 1)) { //将header节点的next属性赋值给next,即下一次要返回的节点 next = header.next; //获取指定位置的节点 for (nextIndex=0; nextIndex<index; nextIndex++) next = next.next; } else { //若index >= size/2,则从后往前遍历nextIndex从size到index next = header; //获取指定位置的节点 for (nextIndex=size; nextIndex>index; nextIndex--) next = next.previous; } } //根据nextIndex是否等于size来判断是否还有没有遍历的节点 public boolean hasNext() { return nextIndex != size; } //获取下一个元素 public E next() { //检查本集合在遍历的过程中,是否有其他线程对本集合的结构大小做了修改 checkForComodification(); //nextIndex == size,说明链表已经被遍历了一遍,不存在没有被遍历的节点了 if (nextIndex == size) throw new NoSuchElementException(); //将next节点设置为最近一次返回的节点 lastReturned = next; //将next节点往后移动一位 next = next.next; //将nextIndex+1 nextIndex++; //返回最近一次返回节点的数据元素 return lastReturned.element; } //从后往前遍历的过程中,判断是否还有未被遍历的元素 public boolean hasPrevious() { return nextIndex != 0; } //获取上一个元素 public E previous() { //若nextIndex==0,说明在从后往前遍历(下边从size 到 0)过程中,已经遍历到头了,不存在没有被遍历的节点了,则抛出NoSuchElementException if (nextIndex == 0) throw new NoSuchElementException(); //将next往前移动一位,并将next节点赋值给最近返回的节点lastReturned lastReturned = next = next.previous; //将nextIndex-1 nextIndex--; //检查本集合在遍历的过程中,是否有其他线程对本集合的结构大小做了修改 checkForComodification(); //返回最近一次返回节点的数据元素 return lastReturned.element; } public int nextIndex() { return nextIndex; } public int previousIndex() { return nextIndex-1; } //移除当前迭代器持有的节点 public void remove() { checkForComodification(); Entry<E> lastNext = lastReturned.next; try { LinkedList.this.remove(lastReturned); } catch (NoSuchElementException e) { throw new IllegalStateException(); } if (next==lastReturned) next = lastNext; else nextIndex--; lastReturned = header; expectedModCount++; } //将当前迭代器持有的元素 替换为元素e public void set(E e) { if (lastReturned == header) throw new IllegalStateException(); checkForComodification(); lastReturned.element = e; } //在当前节点后面插入元素e public void add(E e) { checkForComodification(); lastReturned = header; addBefore(e, next); nextIndex++; expectedModCount++; } //检查本集合在遍历的过程中,是否有其他线程对本集合的结构大小做了修改,如果别的线程对集合做出了修改,则抛出ConcurrentModificationException final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); } } /** *接口ListIterator,继承了迭代器接口Iterator */ public interface ListIterator<E> extends Iterator<E> { //在遍历集合时(按照从前往后的顺序),是否还存在没有遍历的元素 boolean hasNext(); //返回下一个元素 E next(); //在遍历集合时(按照从后往前的顺序),是否还存在没有遍历的元素 boolean hasPrevious(); //返回上一个元素 E previous(); //返回下一个元素的位置下标 int nextIndex(); //返回上一个元素的位置下标 int previousIndex(); //删除正在遍历的元素 void remove(); //将正在遍历的元素替换为 元素e void set(E e); //插入元素e void add(E e); }
使用LinkedList的注意事项:
1.LinkedList是基于双向链表实现的。
2.LinkedList在插入元素时,必须创建Entry对象,并修改相应元素的前后元素的引用;在查找元素时,必须遍历链表;在删除元素时,遍历链表找到要删除的元素,修改被删除元素的前后元素的引用;
3.LinkedList不是线程安全的。
我们再看一看ArrayList的构造器:
标签:没有 this expec 技术 建议 通过 ensure cti 下标
原文地址:https://www.cnblogs.com/zhaosq/p/10019843.html