标签:soft 参数 str 就是 use pytho python3 抓取 建立
爬虫的定义
什么是爬虫?
爬虫(又被称为网页蜘蛛,网络机器人)就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。
原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。
爬虫的分类和爬虫的流程
爬虫的分类
根据被爬网站的数量不同,我们把爬虫分为
- 通用爬虫:通常指搜索引擎的爬虫
- 聚焦爬虫:针对特定网站的爬虫
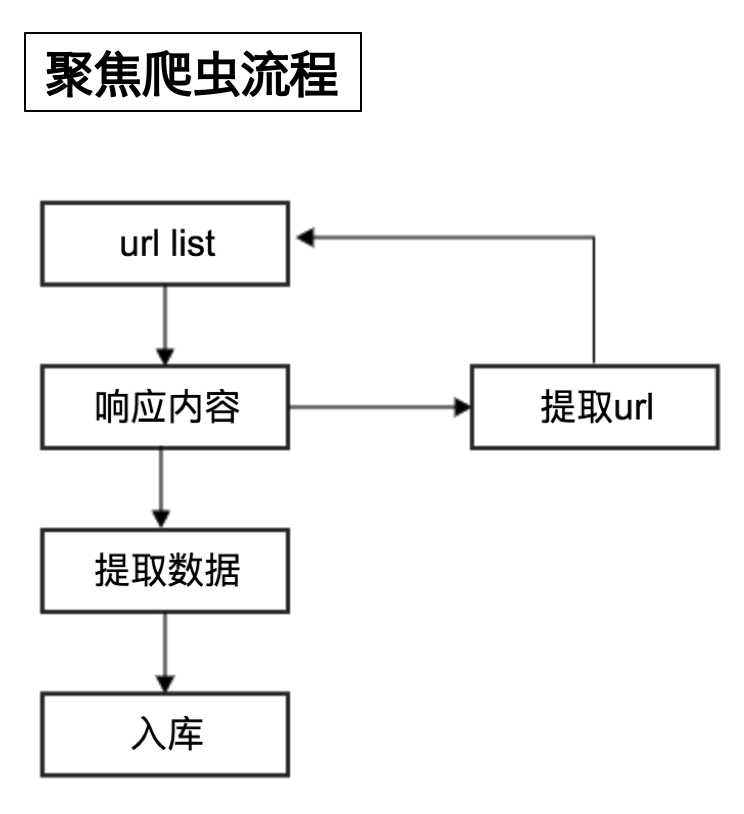
聚焦爬虫的工作流程如下
urllist --> 响应的内容 --> 提取数据 -->入库
robots协议
robots协议
网站通过robots协议告诉搜索引擎哪些页面可以被抓取,哪些页面不能被抓取,但它仅仅是道德层面上的约束
?
HTTPS和HTTP的复习
http和https的概念
HTTP
HTTPS
https比http更安全,但性能更低
浏览器发送http请求的过程
当我们在本地输入www.baidu.com的时候,浏览器会先尝试从本地的host文件中获取到对应的ip地址,如果不能,会通过DNS服务器获取www.baidu.com对应的ip。
下一步就是使用tcp协议,建立tcp连接。然后使用HTTP协议请求网页的内容,收到服务器的回应,得到一串HTML形式的文本,浏览器把它渲染并显示到屏幕上。
浏览器会自动请求js,css等内容,js会修改页面内容。最后浏览器渲染出来的内容在elements中,其中包括css,js,图片,url地址对应响应的内容等。
但是在爬虫中,爬虫只会请求url地址,拿到url地址响应的内容
渲染出来的页面和爬虫请求的页面不一样
所以在爬虫中,需要以url地址对应的响应来提取内容
url的形式
url的形式:scheme://host[:port#]/path/…/[?query-string][#anchor]
- scheme:协议
- host:服务器的ip地址或者域名
- port:端口号
- path:请求资源的路径
- query_string:参数,发送给http服务器的数据
- anchor:锚 (跳转到网页的指定的锚点位置)
http重点的 请求头
user-agent:告诉对方服务器是什么客户端正在请求资源,爬虫中模拟浏览器非常重要的一个手段
python2和python3中的字符串
- ascii 一个字节表示一个字符
- unicode 两个字节表示一个字符
- utf-8 变长的编码,可以是1,2,3,4个字节
python2
- 字节类型,str类型,通过decode()转为unicode类型
- unicode类型:unicode,通过encode()转为str字节类型
python3
- str:unicode,通过encode()转为bytes类型
- bytes:字节类型,通过decode()转为str类型
爬虫入门
标签:soft 参数 str 就是 use pytho python3 抓取 建立
原文地址:https://www.cnblogs.com/Lclog/p/10050694.html