标签:令行 启动 不同 code 9.png 任务 tps amp lock
docker run -i -t -p 50070:50070 -p 9000:9000 -p 8088:8088 -p 8040:8040 -p 8042:8042 -p 49707:49707 -p 50010:50010 -p 50075:50075 -p 50090:50090 sequenceiq/hadoop-docker:2.6.0 /etc/bootstrap.sh -bash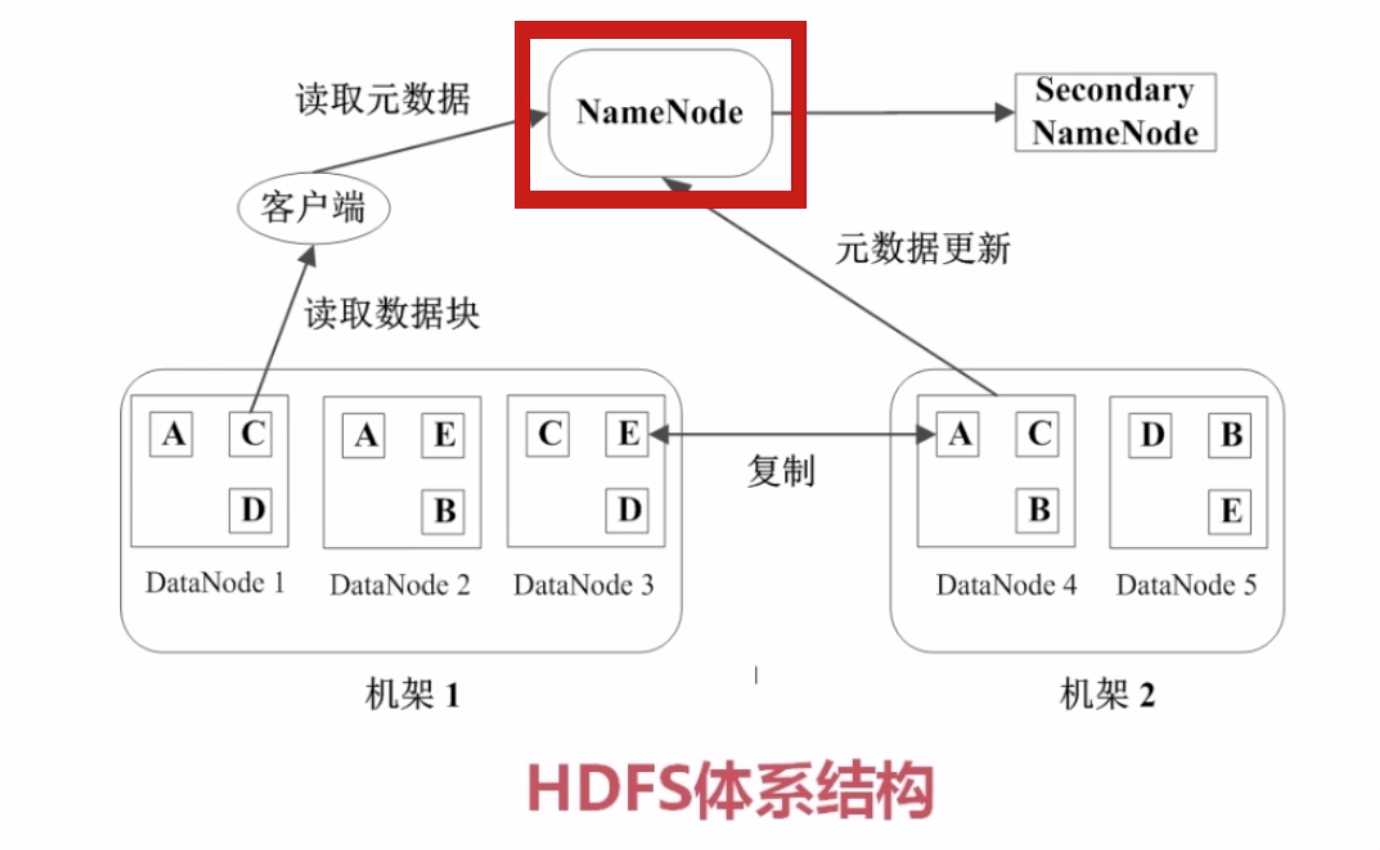
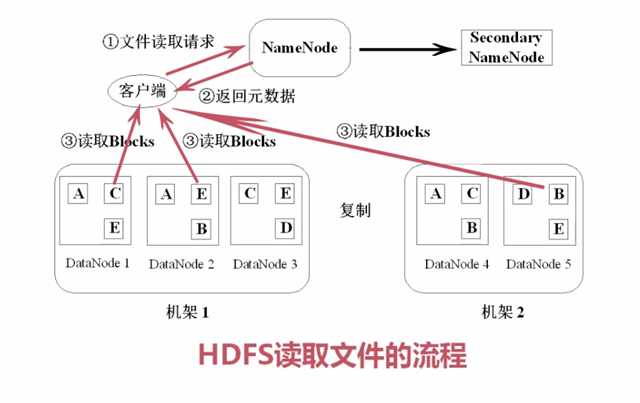
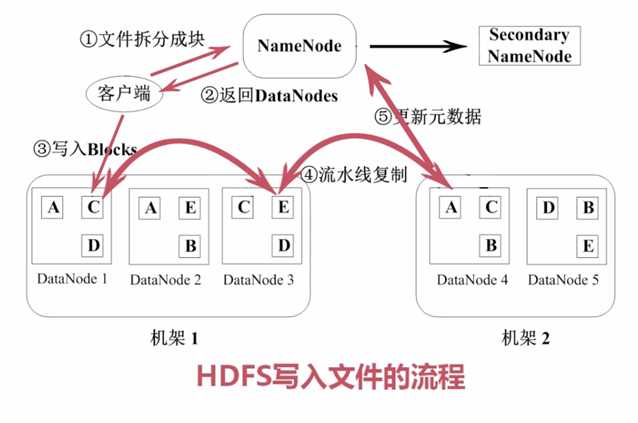
数据块副本
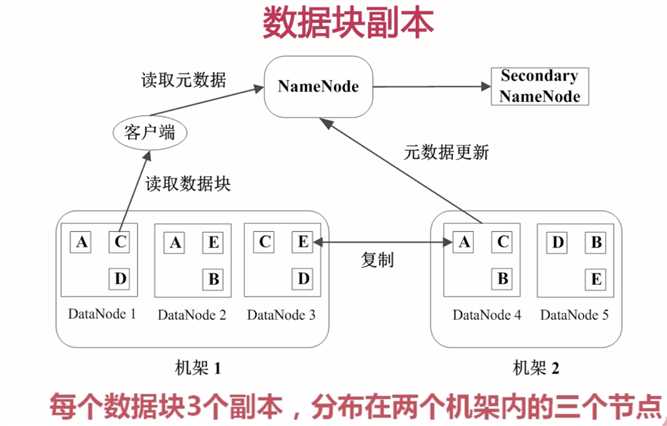
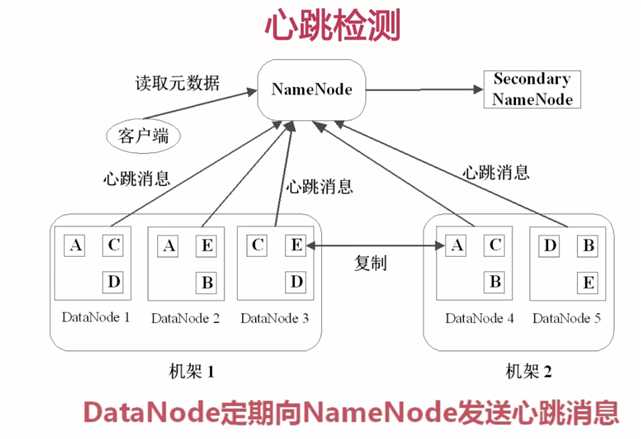
心跳检测
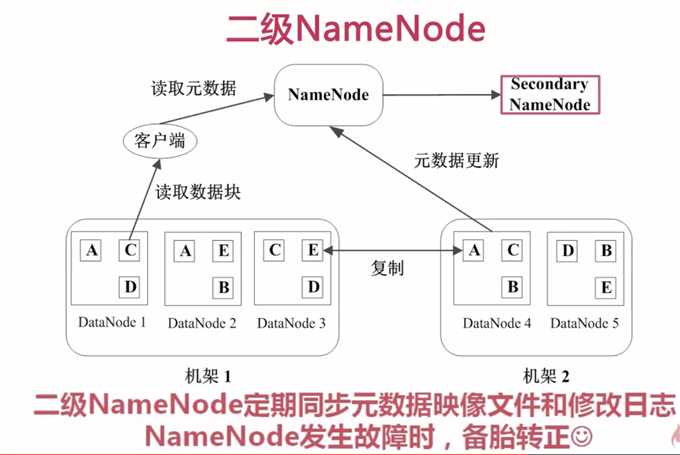
二级NameNode
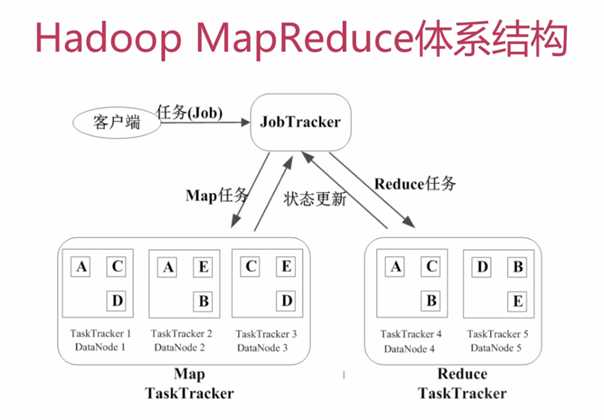
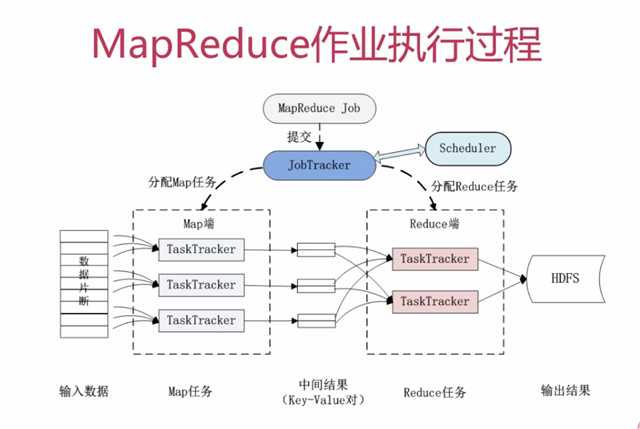
由于我是docker安装,具体例子可以参考如下
docker安装的容器里,自带了例子,位置是/usr/local/hadoop-2.6.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar
标签:令行 启动 不同 code 9.png 任务 tps amp lock
原文地址:https://www.cnblogs.com/sky-chen/p/10054373.html
{kind=link}