标签:blog http io os ar sp 数据 div 2014
参考周涛的几篇二部图的文章做的实验文章列表:
1,2007PRE Bipartite network projection and personal recommendation.pdf (网络结构)
2,2010PNAS-Solving the apparent diversity-accuracy dilemma of recommender systems.pdf (物质扩散和热传导)
Heats和Pros的简单融合算法
3,2009NJP Accurate and diverse recommendations via eliminating redundant correlations.pdf (多步物质扩散)
2008EPL Effect of initial configuration on network-based Recommendation.pdf (初始资源分配)
这两篇是对Pros算法的改进,提高很明显,分别提高9%,(我的试验试验中正确率从16%多到17.8%),20%(试验中从17.8%到 20.5%左 右,细调一下参数可以到21%以上)
此外。这一系列文章中提出一些新的判别指标,不同于与往常评估的precision,recall,popular,cover(覆盖率)(参见推荐系统实战)
这里采用的判别指标有:
rangking score:其实就是第一个推荐正确的物品出现的位置,比如出现在30th,而共有1500个未收集物品,则rat=0.02%,这个值越小代表 结果越好
novelty=mean(log2(u/ka)),u是用户总数,ka是select物品a的用户数,其实是流行度pop的倒数取log,这个值越大越好。
diversity:这个我认为非常有创造性的一个指标,作者将其分为内在相似度(intra-similarity)和外在差异度(inter-diversity)
1,intra: 同一用户不同物品之间的相似度,理应小点好,Il=1/(l*(l-1))*Σi+jSij,l是推荐列表的长度,I=1/m*Σ1~m I, m是用户数
Sij由CF得到,Sij=(k(oi)*k(oj))-1/2*Σ1~m ( ail*ajl)
2, inter:Hij=1-qij(N)/N=1-Q/L,Q是用户i,j推荐列表中相同的物品数目
S=1/(m*(m-1))ΣHij,显然inter-diversity越大越好
I与S之间没有直接的关系。
数据集用的Movielens-100K,指标是用的传统的precision,还有recall,pop等,就不上图了
下面是实验结果:
1,资源初始分配参数beta-precision
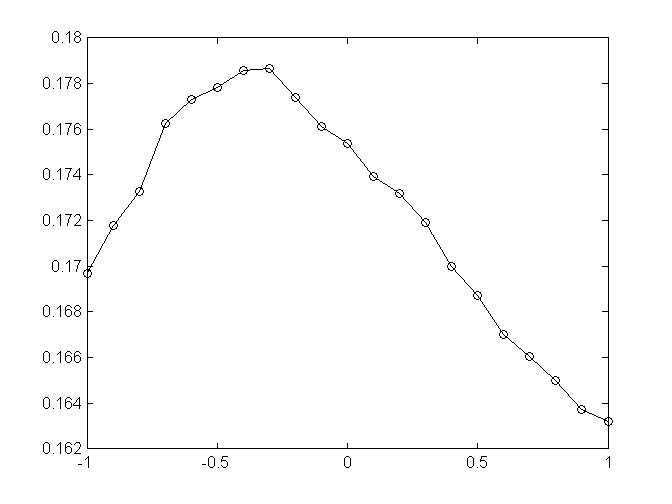
2,beta=-0.3时,w+alpha*w^2,做多步扩散,消除冗余信息,alpha-precision
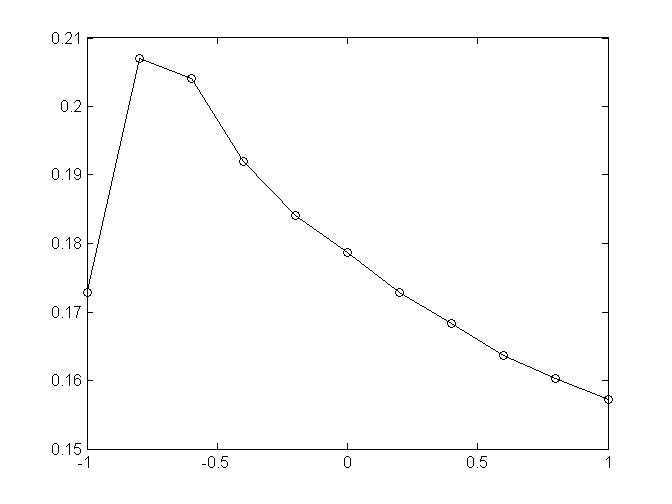
3,alpha=-0.75,beta-precision
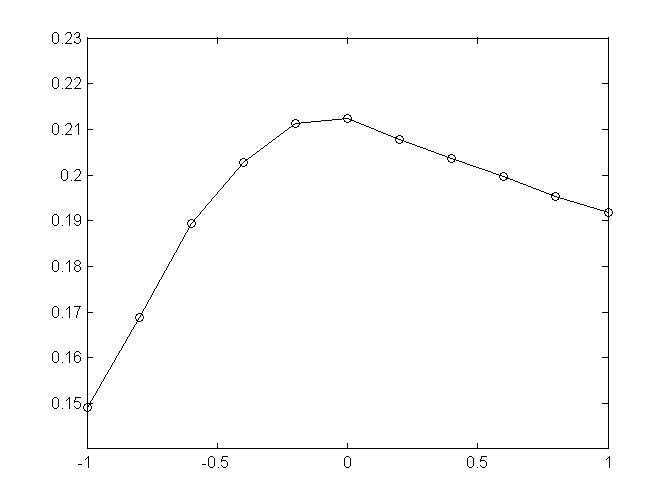
从结果图来看,先确定alpha再确定beta结果会好点,暂时不清楚有没有更好的方法来同时调节这俩参数,来使结果最优,论文中beta=-0.8,alpha=-0.75,但是由于这里指标用的和它不同,所以参数会有些许差别,21%的结果已经优于user-KNN算法取领域为50的结果20.08%,内存上俩着占用差不多,时间上这个方法只需要3~5s,而KNN-50要80s左右。
标签:blog http io os ar sp 数据 div 2014
原文地址:http://www.cnblogs.com/fkissx/p/4022862.html