标签:除了 java wap lock 运维 limits swap uri listening
ElasticSearch:简称es ,分布式全文搜索引擎,使用java语言开发,面向文档型数据库,一条数据就是一个文档,数据用json序列化后存储。
默认端口:9200
借助redis来理解
redis以key/values方式存储数据,abc=123 通过key(abc)即可取出值(123)
es 使用索引-类型-数据-数据中的某个字段 格式来存储数据。
es安装
服务器ip:192.168.100.2
软件包elasticsearch 6.5:
链接:https://pan.baidu.com/s/14aXMtEldzBT2R8hW2gWEEQ 提取码:dk7x
下载完毕后,解压tar包:
[root@host1 [00:35:22]/usr/src]#tar xf elasticsearch-6.5.1.tar.gz
解压后,解压的目录可以直接使用,将解压后的目录移动到一个指定位置,并命名
[root@host1 [00:36:08]/usr/src]#mv elasticsearch-6.5.1 /usr/local/elasticsearch
在PATH变量中添加es的bin目录,让系统可以找到es的可执行文件,方便执行命令
[root@host1 [00:37:10]/usr/src]#cat /etc/profile |tail -3 |head -1 export PATH=$PATH:/usr/local/elasticsearch/bin:/usr/bin/:/usr/local/node/bin/
编辑es配置文件,配置监听端口,地址等信息
[root@host1 [00:39:52]/usr/local/elasticsearch/config]#vim /usr/local/elasticsearch/config/elasticsearch.yml
cluster.name: test 集群名称,配置es集群时设置,集群名称相同,网络相同的情况下,多台可同时对外服务
node.name: linux-node1 本机名称,定义一个你喜欢名称
path.data: /usr/local/elasticsearch/data es存储数据的目录,此目录不存在,需要手动创建
path.logs: /usr/local/elasticsearch/logs 存储log的目录,同上,需要手动创建
bootstrap.memory_lock: false 内存锁定机制,让es只在内存中缓存数据,不在swap分区中操作,突然的使用swap分区会极大的影响速度 Centos6不支持这个机制,所以要设置false
bootstrap.system_call_filter: false 上面参数的辅助参数
network.host: 0.0.0.0 监听的地址
http.port: 9200 监听端口,默认9200
进行主配置文件定义后,还要进行下方的配置,否则es会启动失败
1.创建一个普通用户启动es,es不支持root用户启动。
[root@host1 [00:40:39]/usr/local/elasticsearch/config]#useradd admin
2.编辑limit文件,写入下方内容
[admin@host1 [00:57:57]/usr/local/elasticsearch/config]$ulimit -u 4096 用户最大可开启进程,临时生效 需要在你创建的启动es的用户空间执行
[root@host1 [00:46:36]/usr/local/elasticsearch/config]#cat /etc/security/limits.conf |grep ^* * soft nofile 65536 * hard nofile 131072 * soft nproc 2048 * hard nproc 4096
3.用户最pending signals数量
[root@host1 [00:48:13]/usr/local/elasticsearch/config]#cat /etc/security/limits.d/90-nproc.conf |grep ^* * soft nproc 14794
4.单个JVM能开启的最大线程数设置
[root@host1 [00:49:12]/usr/local/elasticsearch/config]#sysctl -w vm.max_map_count=262144 临时生效 vm.max_map_count = 262144 [root@host1 [00:52:27]/usr/local/elasticsearch/config]#echo "vm.max_map_count=262144" >> /etc/sysctl.conf 写入文件永久生效 [root@host1 [00:52:38]/usr/local/elasticsearch/config]#sysctl -p vm.max_map_count = 262144
5.将es的目录所属主,组,更改为你创建的用户
[admin@host1 [01:00:52]/usr/local/elasticsearch/config]$chown -R admin:admin /usr/local/elasticsearch/
配置完毕后,启动es,需要使用,你创建的普通用户,
#命令作用是将所有运行中出现的结果输出到文件:/usr/local/elasticsearch/logs/run.log 中,并放在后台执行,不影响前台操作
[admin@host1 [01:04:22]/usr/local/elasticsearch/config]$elasticsearch &> /usr/local/elasticsearch/logs/run.log &
在浏览器中访问你的服务器的ip地址加上9200端口看结果,类似下面,那么恭喜,你的es安装成功了:

下面开始介绍es的简单操作
存储数据下方数据至es中
{
"name":"xiaoming"
"age":"22"
}
需要经过以下几个步骤
1.创建索引名称为index-test
1)索引库名称必须要全部小写,不能以下划线开头,也不能包含逗号
2)如果没有明确指定索引数据的ID,那么es会自动生成一个随机的ID,需要使用POST参数
[root@host1 [18:18:47]~]#curl -XPUT http://192.168.100.2:9200/index-test
返回结果:{"acknowledged":true,"shards_acknowledged":true,"index":"index-test"}
在某个类型中创建数据
#在index-test的索引中创建一个类型doc,在doc中创建一个数据,user_info存入,username=xiaoming 的对应关系
#-H指定头部,-X指定方法 -d指定参数,参数用双引号保卫,因为最终需要转换为json数据。
[root@host2 [01:22:22]~]#curl -H "Content-Type: application/json" -XPOST 192.168.100.2:9200/index-test/doc/user_info -d ‘{"user_name":"xiaoming"}‘
{"_index":"index-test","_type":"doc","_id":"user_info","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":3}[root@host2 [01:22:35]~]#
获取数据
#GET方法,获取对应的索引->类型->数据
[root@host2 [01:26:44]~]#curl -H "Content-Type: application/json" -XGET 192.168.100.2:9200/index-test/doc/user_info
{"_index":"index-test","_type":"doc","_id":"user_info","_version":1,"found":true,"_source":{"user_name":"xiaoming"}} _source字段使我们存储的数据。
使用这种方法存储操作数据,岂不是非常麻烦,接下来我们可以用独立的模块来连接es并执行操作,模块给我们提供了人性化的界面,比冰冷的代码更温暖。
elasticsearch-head
#前期版本的es是集成插件的,通过es本身提供功能即可添加某个插件,目前的es跟插件都是独立的,插件需要额外安装
简称head模块,主要功能:中文界面,图形化操作存储,更改,删除数据,界面可显示现有索引,并对索引大小进行检查等。
#使用head插件必须配合node使用,下载时请一并下载node软件包
head以及node软件包:
链接:https://pan.baidu.com/s/1HtTcvMD8p1wtRcHThk4sMA 提取码:i4oj
解压软件包
[root@host1 [02:09:22]/usr/src]#tar xf elasticsearch-head.tar.gz [root@host1 [02:12:19]/usr/src]#tar xf node-v8.12.0-linux-x64.tar.gz
配置node的,让系统能够正常执行它的命令,不配置下方步骤,将会报错:
[root@host1 [02:13:41]/usr/src/elasticsearch-head]#ln -s /usr/src/node-v8.12.0-linux-x64/bin/node /usr/bin/
进入解压后的head插件目录,使用node提供的npm进行进行运行,并将运行日志写到node目录下,放入后台执行,不影响前台操作
[root@host1 [02:20:09]/usr/src]#cd elasticsearch-head [root@host1 [02:20:15]/usr/src/elasticsearch-head]#/usr/src/node-v8.12.0-linux-x64/bin/npm run start &> /usr/src/node-v8.12.0-linux-x64/run.log &
默认监听本机9100端口,通过浏览器访问本机9100端口即可,成功后结果如下。
在红框出输入es的地址,选择连接后即可展示es的信息(我的es已经经过一定的配置了,所以会有下面的这么多索引,如果按照此文的进度,索引是不存在的,so,忽略即可。)
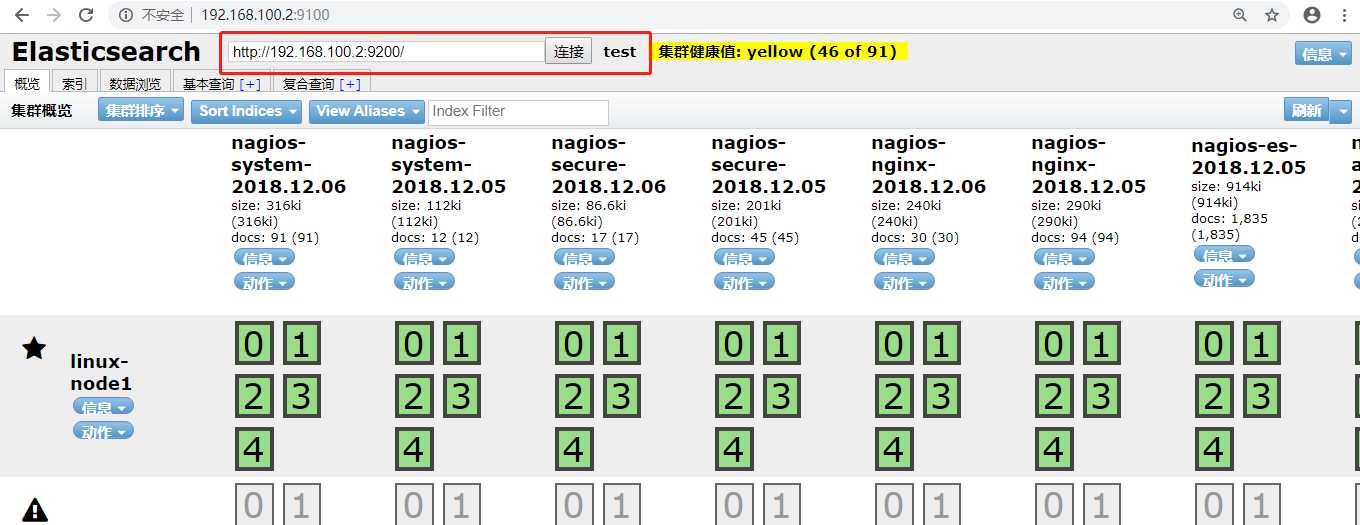
在此处可以查看索引中的全部数据,红框处标记了,之前创建过的user_name:xiaoming内容,在这个平台上可以看到,我们这数据量小,但是实际环境中日志量很定是很大的,那么,可以根据下图中黄色区域使用过滤功能进行查看,根据时间过滤,字段过滤等,对这个功能有兴趣的,可以自行了解下。
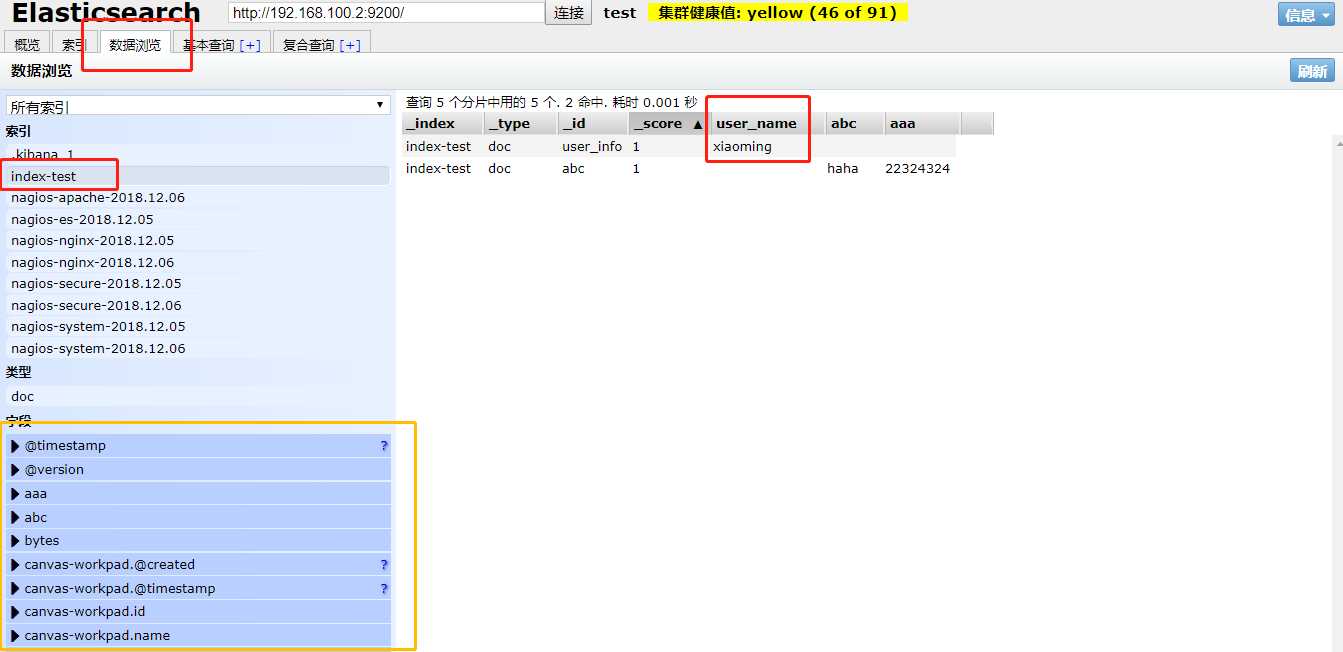
图形化的进行新建索引,删除索引等操作。
下图展示了如何创建一个名称为index-test2的索引
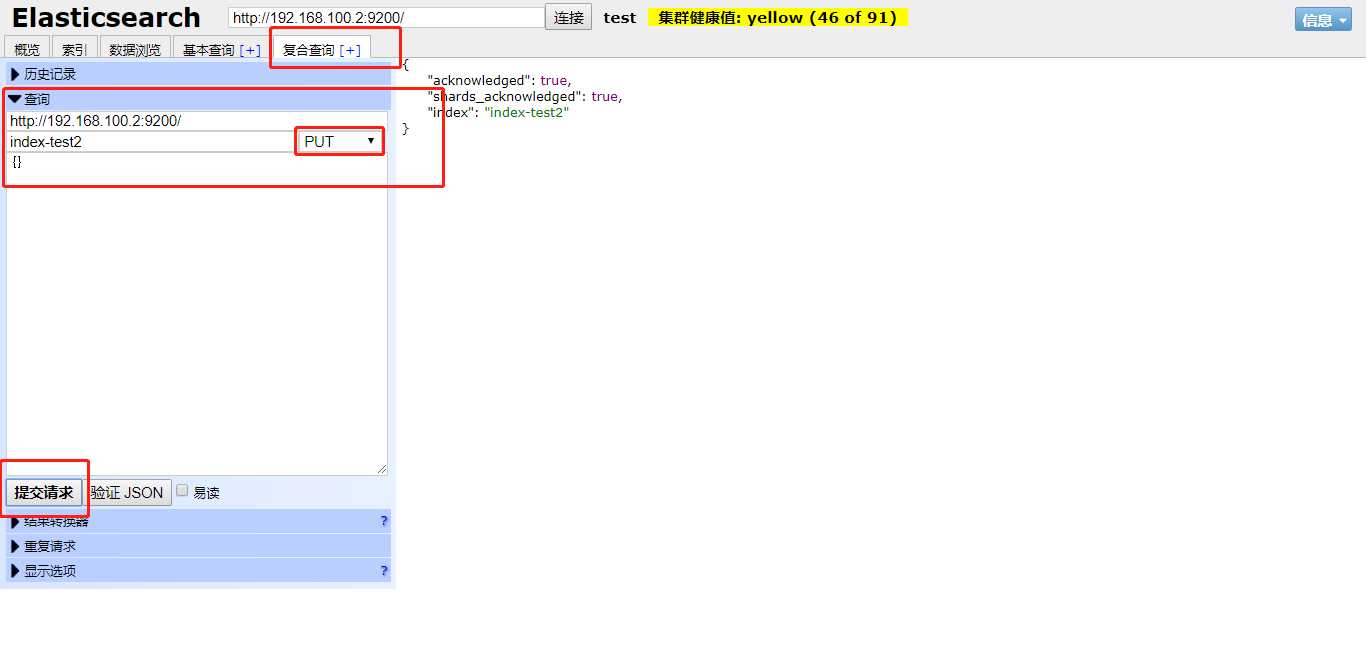
在test2中创建数据
下图演示了在索引test2中的doc类中创建数据,没有定义数据名称,默认会定义一个随机的字符串,如图中的_id字段。
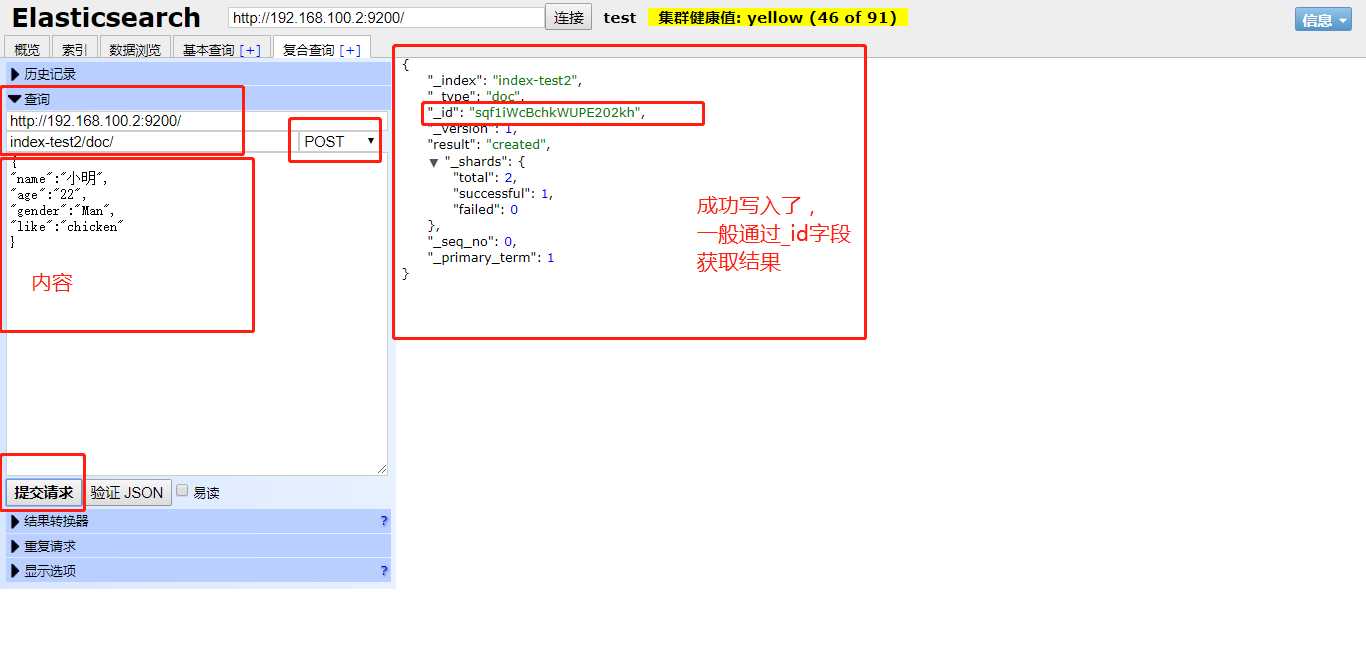
通过随机生成的id获取数据
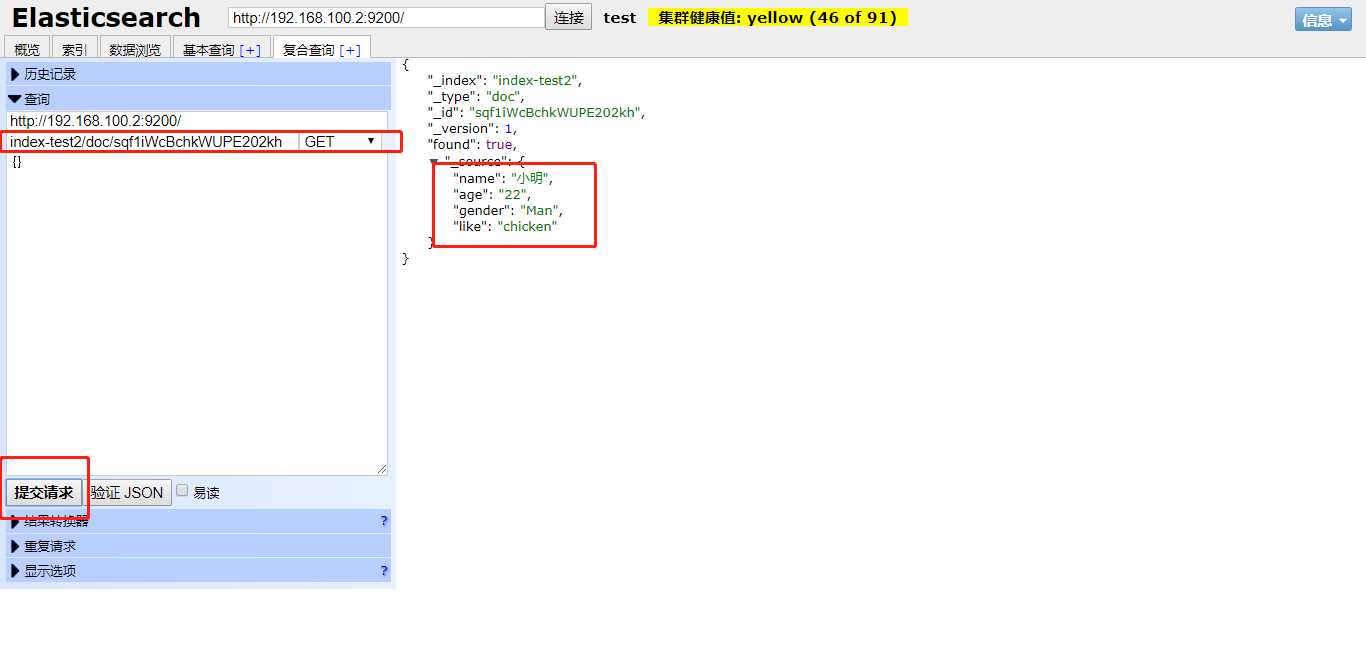
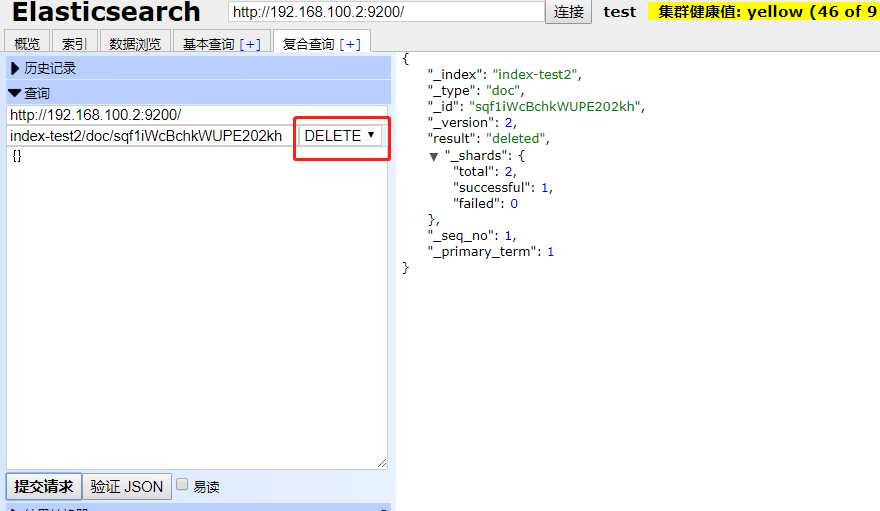
删除数据
bigdesk
一套用于监控es的插件,功能非常强大,展现出来的图很牛逼,但是有些值我至今没看懂~
另外,这插件几年没更新了,但是还能够监控现在新版本的es,在几年前的时间,这个插件可以说是很厉害了
下载:
链接:https://pan.baidu.com/s/1qLdFCYQBIb3nnajlq4fTZg 提取码:ohet
解压:
[root@host1 [02:48:25]/usr/src]#unzip bigdesk-master.zip
进入解压后的目录中的_site,并使用python的功能,创建一个web应用,默认端口8000,即可访问执行python命令的路径下的html文件
[root@host1 [02:48:25]/usr/src]#cd bigdesk-master/_site [root@host1 [02:50:14]/usr/src/bigdesk-master/_site]#python -m SimpleHTTPServer &>/dev/null &
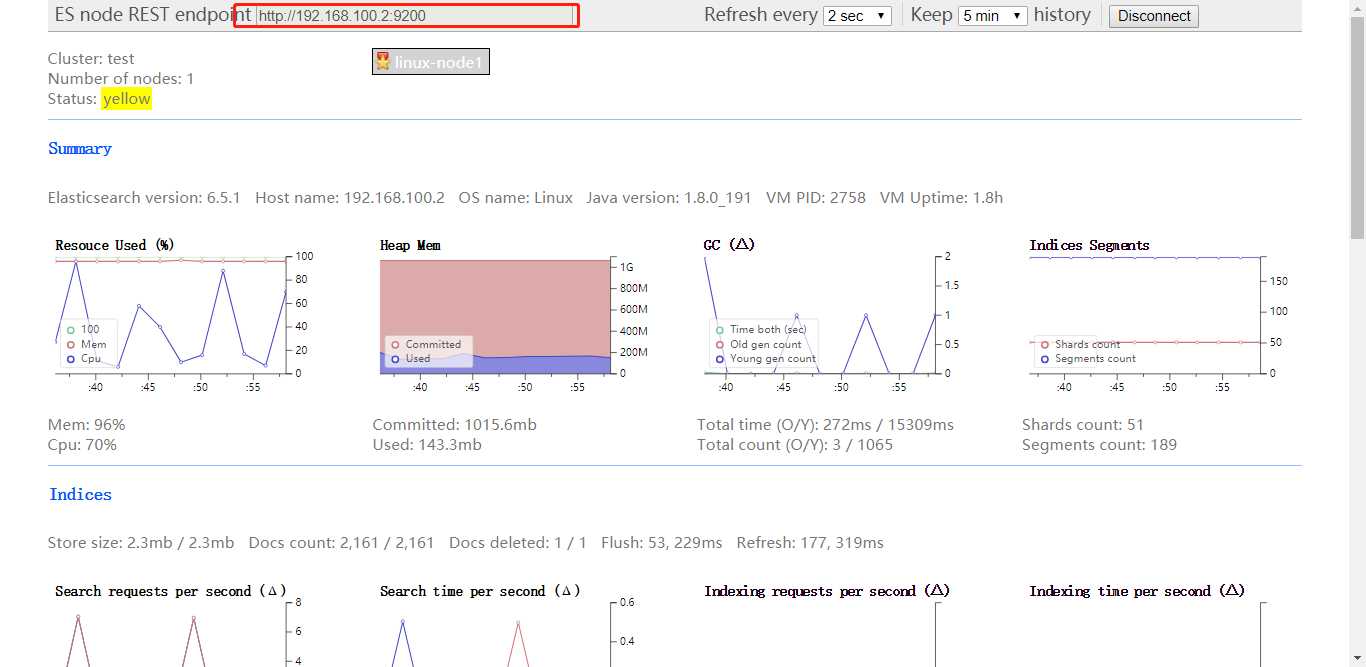
在浏览器中访问本机8000端口,成功后在红框内输入es地址,下方即可看到图标,es机器cpu,mem等等
cerebro
kopf的升级版本,更改了个名字,包含kopf的功能(监控工具,并包含head插件的部分功能,可图形化的进行新建索引等操作,有一个痛点,软件是英文版本),并含有其他功能,下图是作者github上的公告,大概意思就是kopf不在更新,升级为cerebro,并对cerebro进行维护。
下载:
链接:https://pan.baidu.com/s/1W1dDPN8Yc6mWQxL7_6KLEg 提取码:1fj7
解压:
[root@host1 [03:00:45]/usr/src]#tar xf cerebro-0.8.1.tgz
进入解压目录后执行程序即可,默认端口9000(我就不放后台执行了,爱怎么执行怎么把,重要的是把过程展现给你们)
[root@host1 [03:00:45]/usr/src]#cd cerebro-0.8.1 [root@host1 [03:01:12]/usr/src/cerebro-0.8.1]#./bin/cerebro [info] play.api.Play - Application started (Prod) [info] p.c.s.AkkaHttpServer - Listening for HTTP on /0:0:0:0:0:0:0:0:9000
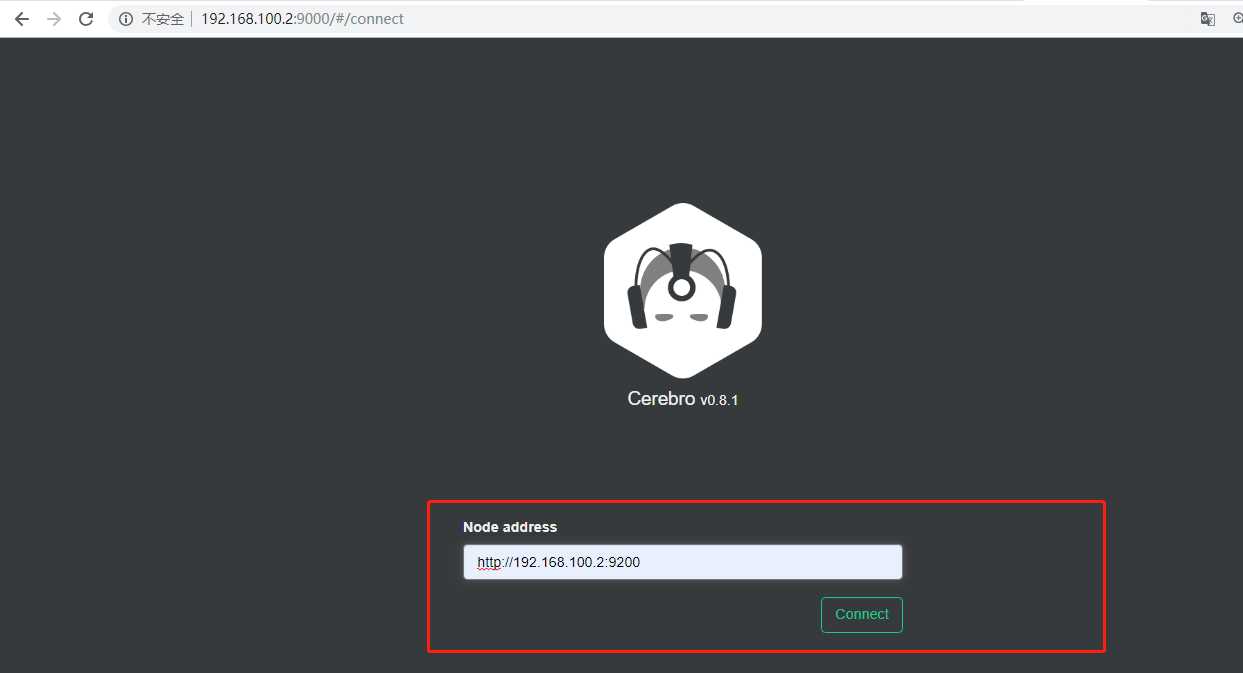
访问测试并输入es地址(界面很酷炫有木有)
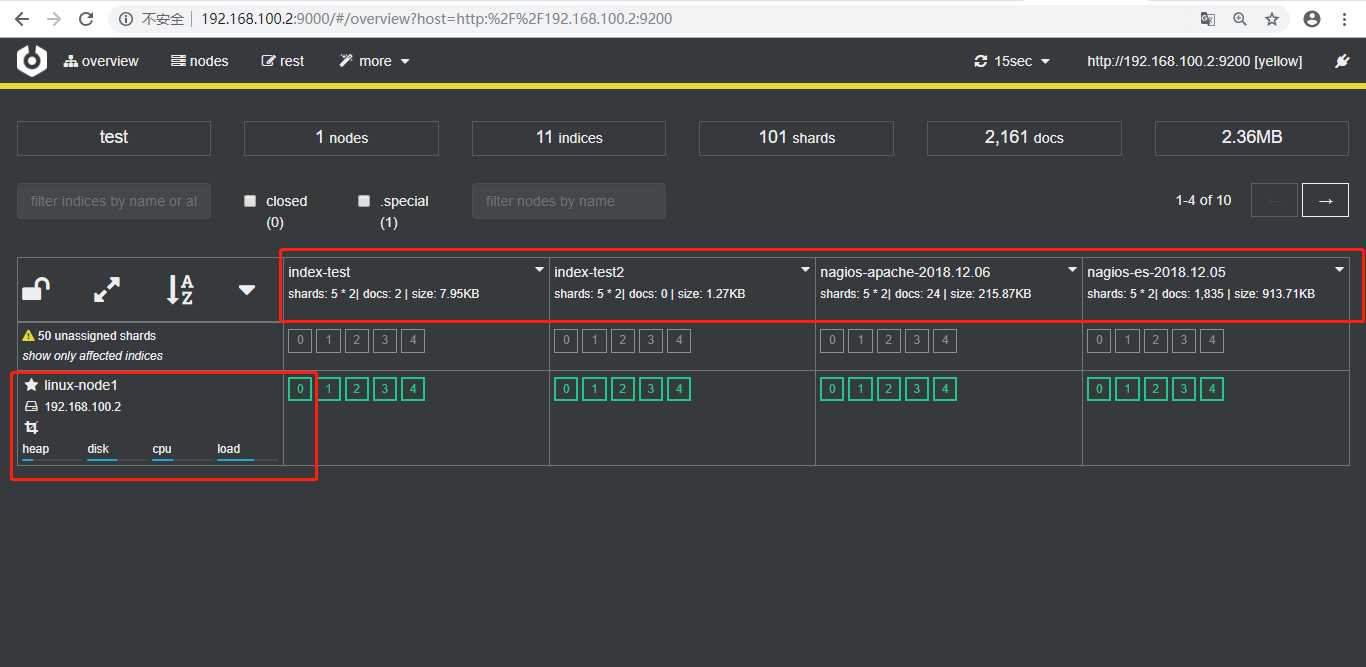
连接es后,跟head一样,主界面显示了索引信息,但是还增加了监控服务器的负载信息等。
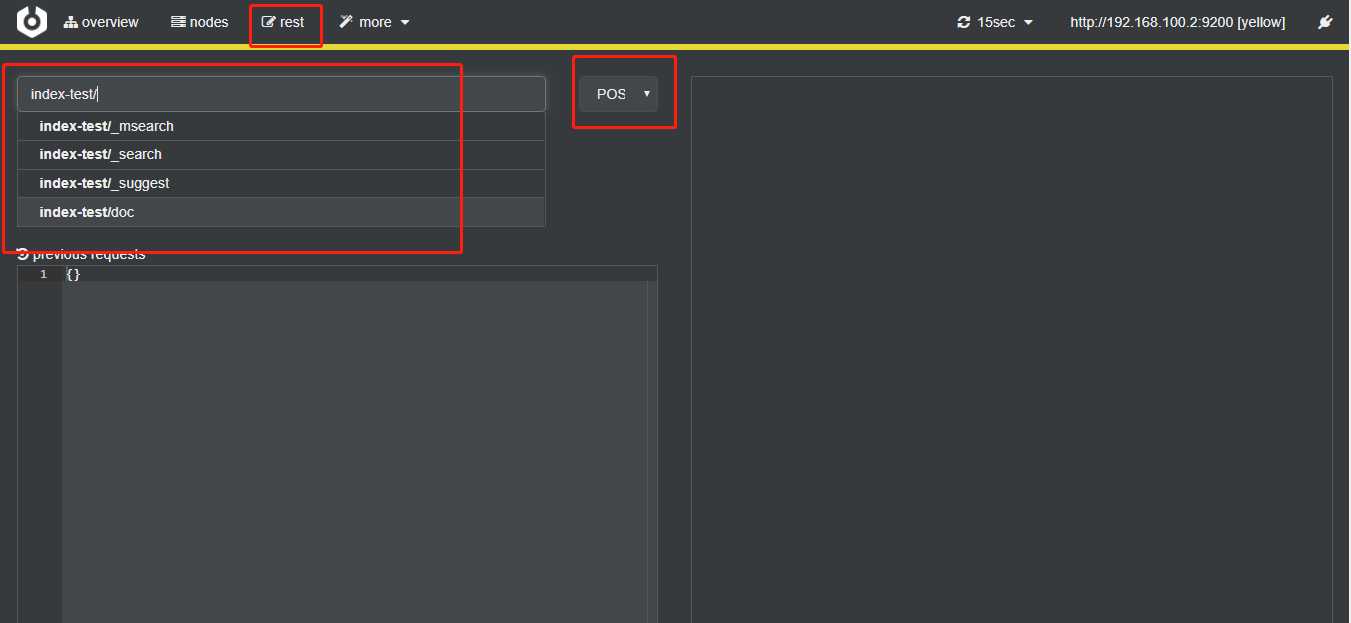
rset界面,可以实现head模块中的图形化执行操作数据的功能,并且增加了只能匹配功能,它帮你匹配你输入的选项后面可能是什么参数。
这是我最喜欢的插件,但是我一个运维能对es做啥更深的事儿呢,除了搭个es集群什么的,es最终是面向开发人员的应用的,所以还有很多插件还有很多功能,都没有接触,1是感觉没必要,2是真不会~。
ELK- esticsearch 讲解,安装,插件head,bigdesk ,kopf,cerebro(kopf升级版)安装
标签:除了 java wap lock 运维 limits swap uri listening
原文地址:https://www.cnblogs.com/xiaodai12138/p/10084465.html