标签:电子 制造 需要 工程师 例子 大致 ima 控制 介绍
本篇文章承接上文继续介绍DDR内存的硬件原理,包括如何寻址,时序和时延以及可以为提高内存的效能可以有哪些方法。
上次虽然解决了小张的问题,却引发了他对内存原理的兴趣。这不他又来找我了,说我还欠他一个解释。这次我们约在一个咖啡馆见面,这次内容有点深入,我带了些图片,小张也点了一大杯美式,计划大干一场。看着他认真的样子,我也决定毁人不倦,把他也带入IT工程师的不归路。。。
为了了解前几天说的几个延迟参数,不得不介绍下DIMM的寻址方式。也许你发现了上次介绍Rank和chip的关系时,有个Bank/Column/row我们没有讲到,它们和如何寻址密切相关。还记得上次的图片吗?
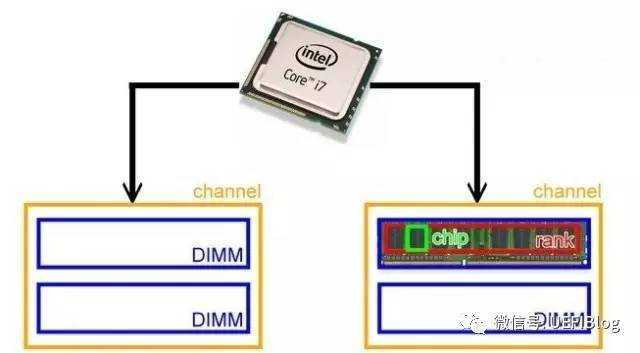
这次我们来看看rank和Chip里面有什么,如下图:
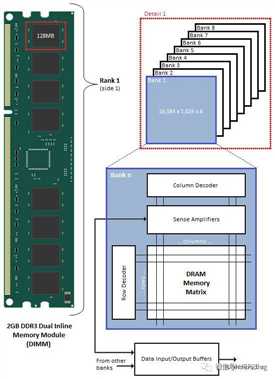
这是个DDR3一个Rank的示意图。2GB的内存共有16个chip,每个chip容量为128MB。我们把左边128MB Chip拆开来看,它是由8个Bank组成,每个Bank核心是个一个存储矩阵,就像一个大方格子阵。这个格子阵有很多列(Column)和很多行(Row),这样我们想存取某个格子,只需要告知是哪一行哪一列就行了,这也是为什么内存可以随机存取而硬盘等则是按块存取的原因。
XXXX,CAS#和RAS#只有一根信号线。实际上每个格子的存储宽度是内存颗粒(Chip)的位宽,在这里由8个Chip组成一个Rank,而CPU寻址宽度是64bit,所以64/8=8bit,即每个格子是1个字节。16384rows*1024columns*8bank=128MB。每一个格子都是由一个晶体管和一个电容组成。
对于DDR3,我们通常说它是8n-prefetch(这儿n是指每个rank的bank数目),因为DDR3,每个IC有8个bank,每个bank读取数据的最小单位是8bit,一个byte。每次数据读取request,都会读取8*8bit=64bitdata,而不管这些数据是否都是我们所需要的,比如我们只需要其中的某个byte,但读request会读取8个byte。
选择每个格子也不是简单的两组信号,是由一系列信号组成,以这个2GB DDR3为例:
1. 片选(Chip Select)信号,S0#和S1#,每个用于选择是哪个Rank。
2. Bank地址线,BA0-BA2, 2^3=8,可以选择8个Bank
3. 列选 (Column Address Select), CAS#,用于指示现在要选通列地址。
4. 行选(Row Address Select),RAS#用于指示现在要选通行地址。
5. 地址线,A0-A13,用于行和列的地址选择(可并不都用于地址,本处忽略)。
6. 数据线,DQ0-DQ63,用于提供全64bit的数据。
7. 命令,COMMAND,用于传输命令,如读或者写等等。
注意这里没有内存颗粒的选择信号线,只有Rank的选择信号。在Rank选择好后,8个内存颗粒一起被选中,共提供64bit的数据。
读取和写入数据也稍微复杂点,简单来说分为以下三步:
1. 行有效。RAS#低电平,CAS#高电平。意味着现在行地址有效,同时在A0-A13传送地址信号,即2^13个Row可以选择。
2. 列有效。RAS#高电平,CAS#低电平。意味着列地址有效,这时在A0-A13上传送的是列地址。没错,A0-A13是行列共用的,所以每个格子选择需要有1和2两步才能唯一确定。
3. 数据读出或写入。根据COMMAND进行读取或者写入。在选定好小方格后,就已经确定了具体的存储单元,剩下的事情就是数据通过数据I/O通道(DQ)输出到内存总线上了。
这里只介绍随机访问, Burst模式这里略过。下图是个简单的图示:
一气说了这么多,我不禁口干舌燥,停下来喝了一大口咖啡。小张以为我说完了,着急的问我:“我好像听懂了,不过那好几个数字还没讲呢。”。别着急啊,且听我慢慢道来。正因为访问一个数据需要大致三步,为了保证信号的完整性,步骤直接要有区隔,一起发出来会造成错乱,间隔太近也会为采样带来难度,容易引入噪音。所以时序非常重要,
下面是个背对背(back-to-back)读写的时序图:
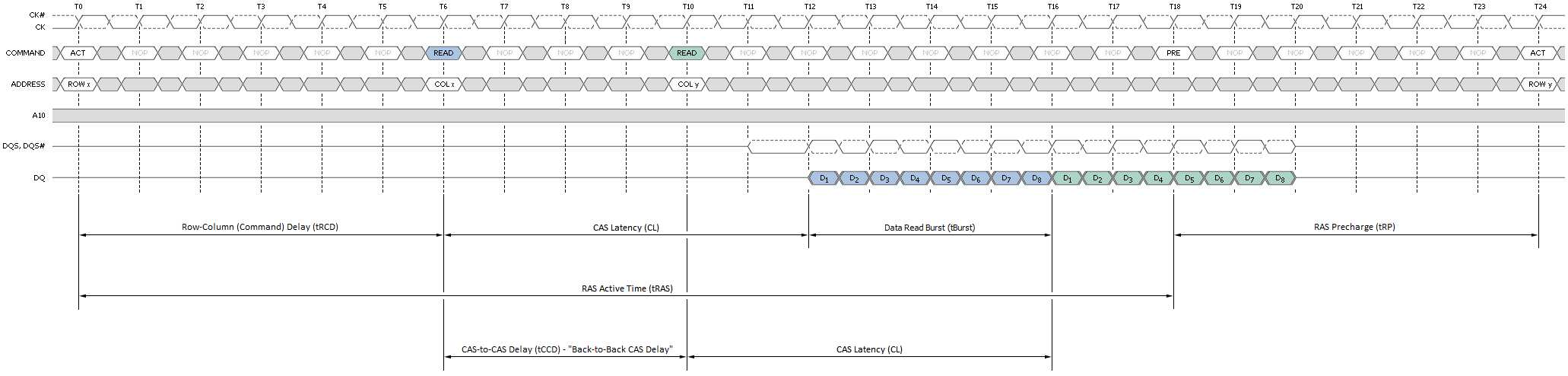
小张一看到这个图,不禁大叫:”太复杂了,看得我都犯密集恐惧症了,看不懂!“。没关系,我们拆开了一个个看。
1. CL: CAS Latency。CL是指CAS发出之后,仍要经过一定的时间才能有数据输出,从CAS与读取命令发出到第一笔数据输出的这段时间,被定义为CL(CAS Latency,CAS时延)。由于CL只在读取时出现,所以CL又被称为读取时延(RL,Read Latency)。也就是我们上面第3步读取时需要的时间。CL是延迟里面最重要的参数,有时会单独在内存标签上标出如CLx。它告诉我们多少个时钟周期后我们才能拿到数据,CL7的内存会延迟7个周期才能给我们数据,CL9的则要等9个。所以越小我们越能更快的拿到数据。注意这里的周期是真正的周期而不是标注的DDR3 1333MHz的周期,因为一个周期传输两次,真正的周期只是1/2,这里是666MHz。如下图,是CL7和CL9的例子:
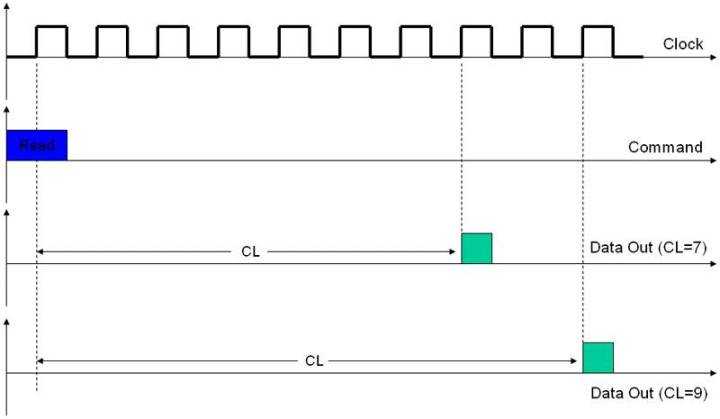
如果相同频率的内存,CL7可以比CL9有22%的效能提高。
2. tRCD:RAS到CAS时延。在发送列读写命令时必须要与行有效命令有一个间隔,这是根据芯片存储阵列电子元件响应时间所制定的延迟。即步骤1和2要间隔的时间。这个间隔当然也是越快越好了,下面是个tRCD=3的例子:
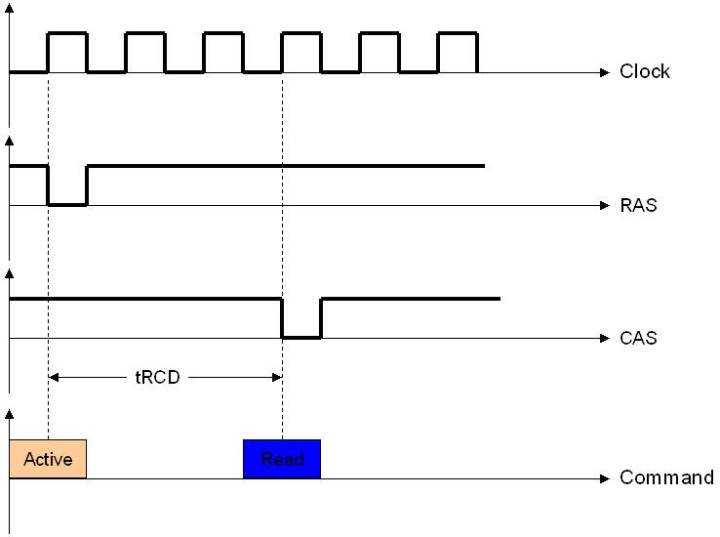
你也可以看出这个时间也是激活命令和读命令的间隔。
3. tRP: 预充电有效周期(Precharge command Period)。在上一次传输完成后到下一次行激活前有个预充电过程,要经过一段充电时间才能允许发送RAS。也就是步骤1的准备工作要做多久。下面是个例子:
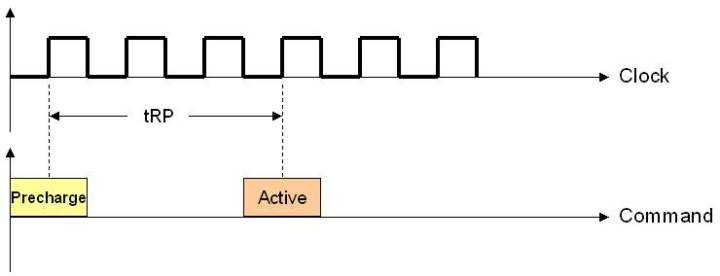
还有两个类似的时延tRAS和CMD,我看到小张都快睡着了就不讲了。总之,所有这些时延共同构成了整体时延,而时延是越小越好。
说了这么多,小张总算搞懂内存标签条上的4-4-4-8, 5-5-5-15, 所代表的 CL-tRCD-tRP-tRAS-CMD都是啥意思了。不过小张有点搞不懂,这些数据印在纸上消费者是看懂了(实际上似乎没多少人了解),可电脑又没长眼睛,它是怎么知道的呢?其实,每个DIMM在板子上都有块小的存储芯片(EEPROM),上面详细记录了包括这些的很多参数,还有生产厂家的代码等等,这也是BIOS为什么能知道我们插了哪种内存的原因。在小张的内存条上,我指给了他看:

实际上随着DDR的一步步进化,这些延迟的时钟周期个数也在步步提高,但由于频率的加快,实际上是在时间是在慢慢的减少的。
效能提高的其他手段
看时间还早,我和小张聊起了除了提高频率,还有什么办法能够提高内存存取速度。
1。多通道(Channel)
现代内存控制器都从北桥移入CPU内部,而且内存控制器都可以同时操作多个通道。典型的台式机和笔记本CPU很早就支持双通道,现在还加入了三通道。如果数据分布在插在不同的通道上的内存条上,内存控制器可以不管上面这些延迟啊时序啊,同时可以读取他们,速度可以翻倍甚至三倍!小张听了跳了起来:”我也要翻倍!”。别急,要启用多通道,首先要插对插槽。现在主板制造商为了让小白用户插对内存条,通常用颜色标识内存通道。注意同一个通道颜色不同!所以要把内存插在颜色相同的内存插槽里,才能让内存占据不同的通道。最好有主板手册检查一下,插好后进入BIOS里面看看现在内存状态是不是多通道模式。
2。Interleave
看着小张跃跃欲试的样子,我不禁给他泼了盆冷水。幻想美妙,现实残酷。多通道在很多时候用处并不明显!因为程序的局部性,一个程序并不会把数据放到各个地方,从而落入另一个DIMM里,往往程序和数据都在一个DIMM里,加上CPU的Cache本身就会把数据帮你预取出来,这个提高就个不明显了。除非你运行很多巨型任务才行。
“啊,我都是开一个游戏打,对我来说没啥用处啊,简直是鸡肋!”,小张说。也不尽然,还有种办法,就是让同一块内存分布到不同的通道中去,这种技术叫做Interleaving。这样无论Cache命中与否都可以同时存取,多通道的技术才能发挥更大的用处。“太好了,要怎么才能开启这个interleave呢?”,我不禁呵呵了,这个功能一般只有服务器CPU才有,你的i5要是有了,谁去买几千上万的服务器CPU呢?
3。Overclock
“你这不是废话吗,我要怎么样才能搭建个发烧机才配有的高速内存呢?”。其实小张可以购买发烧级的内存条。这些内存条DDR3标注达到2133以上!但是要注意,如果我们把这些内存插入一般主板,很有可能会运行在1333或者1600上面,因为这是DDR3规定的最高频率。好马配好鞍,要有个能支持超频内存的主板,在主板BIOS里面升压升频才能真正用好这些发烧内存条。
时间差不多了,我向小张保证下次还会介绍神秘的BIOS如何初始化内存,正要离去。小张拉住了我,说:“你上次挖的坑还没填呢!”“什么坑?”也许是我挖坑太多,记不住了。“就是上次你让我回去想的三个问题。第一个我知道了,DIMM有防呆口,几代DDR防呆口位置不同,插不进去,我在网上google过了,后面两个实在想不出来”。好吧,那我们长话短说,实际上两个问题可以一起回答,今天我们知道DDR每代的各种时延参数是上升的,所以如果两代一样的频率,实际上性能有可能还会下降!譬如DDR2 800在很多时候比DDR3 800的时延要小。我们可以认为每代的起点比前一代的低,有一段重合期,在频率上去后会弥补时延的时钟个数差异,比较时延是clock个数,而不是时间,clock快了,有可能时延会更小。而这段重合期,也为不同的商业策略留下了空间。
小张还是抓住我,他不知道从哪里查了些名词,什么预取个数每代增加,而内核频率不同于外部频率等等。我希望他能自己找找资料看看,也顺便挖了个新坑:
1. 为什么每代DDR要升级,不直接把频率向上提高就行了,为什么没有DDR2 3200的内存?
2. DDR的内存还是并行的数据,串行似乎可以更高速,比格更高,为什么不弄个串行访问的内存呢?
小张陷入了沉思,我也暗喜又骗到一顿咖啡下午茶。不过回去还要准备些材料才能继续混吃混喝,下次介绍完内存的BIOS部分,还有啥题目可以继续吸引小张呢?
标签:电子 制造 需要 工程师 例子 大致 ima 控制 介绍
原文地址:https://www.cnblogs.com/tcicy/p/10087457.html