标签:字母 java 出现 \n 检测方法 net 检索 script asc
1概念
正则表达式(英语:Regular Expression,在代码中常简写为regex)。
正则表达式是一个字符串,使用单个字符串来描述、用来定义匹配规则,匹配一系列符合某个句法规则的字符串。在开发中,正则表达式通常被用来检索、替换那些符合某个规则的文本。
正则表达式就是包含规则的字符串。
2匹配规则
Pattern类中规定了一系列匹配规则。正则表达式中明确区分大小写字母。
常用:
字符:x
含义:代表的是字符x
例如:匹配规则为 "a",那么需要匹配的字符串内容就是 ”a”
字符:\\
含义:代表的是反斜线字符‘\‘
例如:匹配规则为"\\" ,那么需要匹配的字符串内容就是 ”\”
字符:\t
含义:制表符
例如:匹配规则为"\t" ,那么对应的效果就是产生一个制表符的空间
字符:\n
含义:换行符
例如:匹配规则为"\n",那么对应的效果就是换行,光标在原有位置的下一行
字符:\r
含义:回车符
例如:匹配规则为"\r" ,那么对应的效果就是回车后的效果,光标来到下一行行首
字符类:[abc]([]代表一位)
含义:代表的是字符a、b 或 c
例如:匹配规则为"[abc]" ,那么需要匹配的内容就是字符a,或者字符b,或字符c的一个
字符类:[^abc]
含义:代表的是除了 a、b 或 c以外的任何字符(取反)
例如:匹配规则为"[^abc]",那么需要匹配的内容就是不是字符a,或者不是字符b,或不是字符c的任意一个字符
字符类:[a-zA-Z]
含义:代表的是a 到 z 或 A 到 Z,两头的字母包括在内
例如:匹配规则为"[a-zA-Z]",那么需要匹配的是一个大写或者小写字母
字符类:[0-9]
含义:代表的是 0到9数字,两头的数字包括在内
例如:匹配规则为"[0-9]",那么需要匹配的是一个数字
字符类:[a-zA-Z_0-9]
含义:代表的字母或者数字或者下划线(即单词字符)
例如:匹配规则为" [a-zA-Z_0-9] ",那么需要匹配的是一个字母或者是一个数字或一个下滑线
预定义字符类:.
含义:代表的是任何字符
例如:匹配规则为" . ",那么需要匹配的是一个任意字符。如果,就想使用 . 的话,使用匹配规则"\\."来实现(转义再转义)
预定义字符类:\d
含义:代表的是 0到9数字,两头的数字包括在内,相当于[0-9]
例如:匹配规则为"\d ",那么需要匹配的是一个数字
预定义字符类:\w
含义:代表的字母或者数字或者下划线(即单词字符),相当于[a-zA-Z_0-9]
例如:匹配规则为"\w ",,那么需要匹配的是一个字母或者是一个数字或一个下滑线
边界匹配器:^
含义:代表的是行的开头
例如:匹配规则为^[abc][0-9]$ ,那么需要匹配的内容从[abc]这个位置开始, 相当于左双引号
边界匹配器:$
含义:代表的是行的结尾
例如:匹配规则为^[abc][0-9]$ ,那么需要匹配的内容以[0-9]这个结束, 相当于右双引号
边界匹配器:\b
含义:代表的是单词边界
例如:匹配规则为"\b[abc]\b" ,那么代表的是字母a或b或c的左右两边需要的是非单词字符([a-zA-Z_0-9])
数量词:X?
含义:代表的是X出现一次或一次也没有
例如:匹配规则为"a?",那么需要匹配的内容是一个字符a,或者一个a都没有
数量词:X*
含义:代表的是X出现零次或多次
例如:匹配规则为"a*" ,那么需要匹配的内容是多个字符a,或者一个a都没有
数量词:X+
含义:代表的是X出现一次或多次
例如:匹配规则为"a+",那么需要匹配的内容是多个字符a,或者一个a
数量词:X{n}
含义:代表的是X出现恰好 n 次
例如:匹配规则为"a{5}",那么需要匹配的内容是5个字符a
数量词:X{n,}
含义:代表的是X出现至少 n 次
例如:匹配规则为"a{5, }",那么需要匹配的内容是最少有5个字符a
数量词:X{n,m}
含义:代表的是X出现至少 n 次,但是不超过 m 次
例如:匹配规则为"a{5,8}",那么需要匹配的内容是有5个字符a 到 8个字符a之间
使用括号:()
正则表达式中的小括号"()" 代表分组的意思。 如果再其后面出现\1则是代表与第一个小括号中要匹配的内容相同。\2则是代表与第二个小括号中要匹配的内容相同。
常用来判断叠词:
叠词表示为:regex = "(.)\\1+"
3常用方法

传入正则,返回布尔。
4示例
1)检验qq号
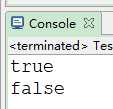
public class Test {
public static void main(String[] args) {
String regex="[1-9][0-9]{4,14}";
String qq="123456789";
String qq2="12";
System.out.println(qq.matches(regex));
System.out.println(qq2.matches(regex));
}
}
2)拆分
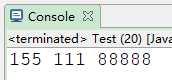
public class Test {
public static void main(String[] args) {
String tel="155-111-88888";
String r="-";
String[] strs=tel.split(r);
for(int i=0;i<strs.length;i++){
System.out.print(strs[i]+" ");
}
}
}
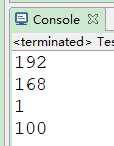
public class Test {
public static void main(String[] args) {
String regex="\\.";
String ip="192.168.1.100";
String[] str=ip.split(regex);
for(int i=0;i<str.length;i++){
System.out.println(str[i]);
}
}
}
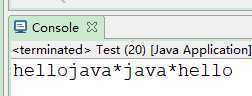
3)把数字换成*
public class Test {
public static void main(String[] args) {
String str="hellojava123java321hello";
String r2="[0-9]+"; //一次或多次
String str2=str.replaceAll(r2, "*");
System.out.println(str2);
}
}
4)验证手机号
public class Test {
public static void main(String[] args) {
String regex = "1[34578][0-9]{9}";
String tel = "18812345678";
System.out.println(tel.matches(regex));
}
}
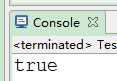
5)验证邮箱
public class Test {
public static void main(String[] args) {
String regex="[\\w]+@[a-zA-Z0-9]+(\\.[a-z]+)+";
//String regex2="\\w+@\\w+(\\.\\w+)+";
String mail="test@yeah.net";
System.out.println(mail.matches(regex));
}
}
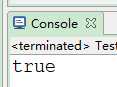
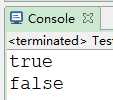
6)匹配中文
public class Test {
public static void main(String[] args) {
String regex="[\u4e00-\u9fa5]+";
String word="我爱你中国";
String str="love中国";
System.out.println(word.matches(regex));
System.out.println(str.matches(regex));
}
}
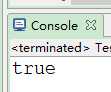
7)验证身份证号
public class Test {
public static void main(String[] args) {
String regex="(^[1-9]\\d{5}(18|19|([23]\\d))\\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\\d{3}[0-9Xx]$)|(^[1-9]\\d{5}\\d{2}((0[1-9])|(10|11|12))(([0-2][1-9])|10|20|30|31)\\d{2}$)";
String word="123456200012121111"; //随便写的
System.out.println(word.matches(regex));
}
}
5 js里的检测方法
在 JavaScript 中,正则表达式通常用于两个字符串方法 : search() 和 replace()。
search() 方法 用于检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串,并返回子串的起始位置。
replace() 方法 用于在字符串中用一些字符替换另一些字符,或替换一个与正则表达式匹配的子串。
标签:字母 java 出现 \n 检测方法 net 检索 script asc
原文地址:https://www.cnblogs.com/hzhjxx/p/10093975.html