标签:hello 去掉 眼睛 必知必会 存在 this 底部 man express
本文和python关系不大,前面几节是为了使用python中的正则,后面只关注正则本身。
re.match #从头开始匹配,返回None/Match对象
re.search #搜索整个字符串,返回None/Match对象
re.findall #搜索整个字符串,返回List
re.finditer #返回迭代器普通字符串匹配
import re
# 匹配纯文本
s1 = ‘hello, my name is Ben. Please visit my website at http://www.xxx.com/.‘
## 单个
single = re.search(r‘Ben‘, s1)
if single:
print(single.group())
## 多个
multiple = re.findall(r‘Ben|my‘, s1)
print(multiple)
结果
Ben
[‘my‘, ‘Ben‘, ‘my‘]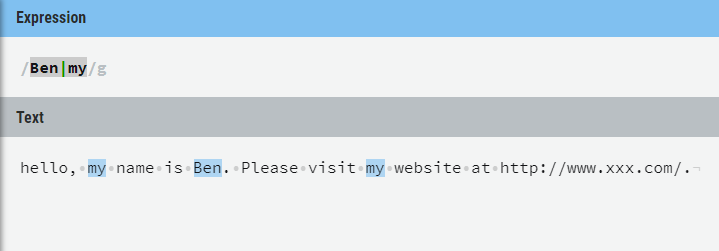
..字符可以匹配任何一个单个的字符(除换行符),
\转义元字符(特殊含义的字符)。
import re
# 匹配任意&特殊字符
s1 = ‘‘‘
$ git status # 查看状态
$ git diff # 查看变更内容
$ git add . # 跟踪所有改动过的文件
$ git add <file> # 跟踪指定的文件
$ git mv <old> <new> # 文件改名
$ git rm <file> # 删除文件
$ git rm --cached <file> # 停止跟踪文件但不删除
$ git commit -m "commit message" # 提交所有更新过的文件
$ git commit --amend # 修改最后一次提交
‘‘‘
result = re.findall(r‘add.\.‘, s1)
print(result)结果
[‘add .‘]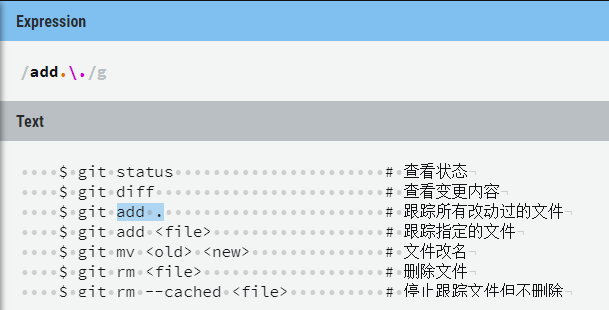
[]使用元字符[]来定义一个字符集合。字符集合的匹配结果是能够与该集合里的任意一个成员相匹配的文本。
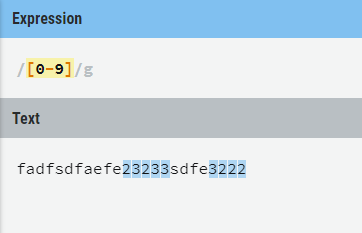
[Aa]匹配A a字符中的某一个。[0123456789]匹配个位数字,等价于[0-9],类似这种通过特殊元字符-连接ASCII码的字符集合区间范围可以方便表达字符范围,举例[A-Z]、多个字符区间[A-Z0-9a-z]。注:-作为元字符只能用在[]之间,其他地方表示普通字符。
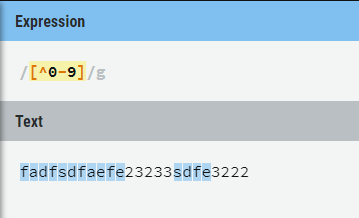
元字符^可以排除字符集合区间的字符,举例:[^0-9]不取数字。
import re
# 匹配一组字符
s1 = ‘‘‘
$ git status # 查看状态
$ git diff # 查看变更内容
$ git add . # 跟踪所有改动过的文件
$ git add <file> # 跟踪指定的文件
$ git mv <old> <new> # 文件改名
$ git rm <file> # 删除文件
$ git rm --cached <file> # 停止跟踪文件但不删除
$ git commit -m "commit message" # 提交所有更新过的文件
$ git commit --amend # 修改最后一次提交
‘‘‘
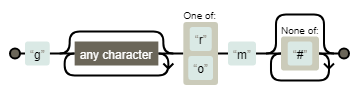
# 取带有rm或者om的git操作
result = re.findall(r‘g.*[ro]m[^#]*‘, s1)
for x in result:
print(x)结果
git rm <file>
git rm --cached <file>
git commit -m "commit message"
git commit --amend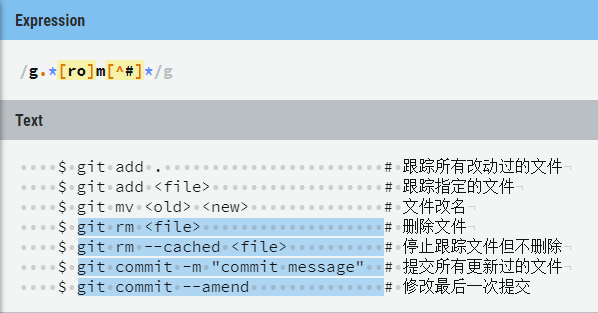
图形化
元字符是一些在正则表达式中有特殊含义的字符。
| 字符类别 | 说明 | 示例 |
|---|---|---|
| 特殊字符转义 | . [ (之类正则的元字符表示自身时需要进行转义 |
\.表示.字符 |
| 空白字符 | 匹配非打印空白字符 \b \f \n \r \t \v |
\n匹配换行符 |
| 数字(类) | \d匹配数字字符(等价于[0-9]),\D匹配非数字字符([^0-9]) |
1[34578]\d{9}匹配手机号码 |
| 字母和数字(类) | \w匹配数字字符下划线(等价于[a-zA-Z0-9_]),\W匹配非\w |
\w+匹配[ onion ]的结果:onion |
| 空白字符(类) | \s匹配任何一个空白字符(等价于[\f\n\r\t\v],不包含退格\d),\S匹配非空白字符 |
\S+匹配[ onion ]的结果:[、onion和] |
| 十六禁止 | 匹配十六进制(\x开头)或八进制(\0开头)数值 |
\x0A等价于\n |
| POSIX字符类 | 常用的字符集合,[:alnum:]匹配字母和数字 |
python中没找到用法 |
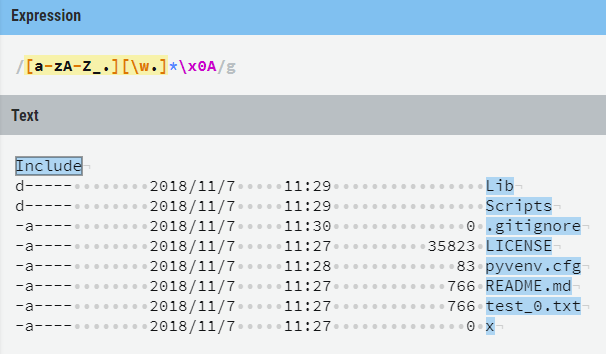
示例:取文件/目录名
import re
# 取文件/目录名
s1 = ‘‘‘
Include
d----- 2018/11/7 11:29 Lib
d----- 2018/11/7 11:29 Scripts
-a---- 2018/11/7 11:30 0 .gitignore
-a---- 2018/11/7 11:27 35823 LICENSE
-a---- 2018/11/7 11:28 83 pyvenv.cfg
-a---- 2018/11/7 11:27 766 README.md
-a---- 2018/11/7 11:27 766 test_0.txt
-a---- 2018/11/7 11:27 0 x
‘‘‘
result = re.findall(r‘([a-zA-Z_.][\w.]*)\x0A‘, s1)
print(result)结果
[‘Include‘, ‘Lib‘, ‘Scripts‘, ‘.gitignore‘, ‘LICENSE‘, ‘pyvenv.cfg‘, ‘README.md‘, ‘test_0.txt‘, ‘x‘]图形化
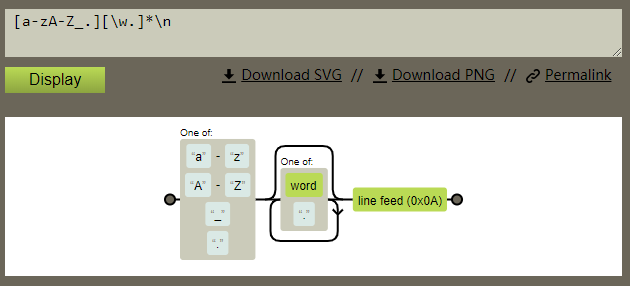
\n和\0xA等价,为line feed (0x0A)。
+*?{}匹配
| 元字符 | 说明 | 示例 |
|---|---|---|
+ |
匹配字符或字符集合的一次或多次重复出现 >=1 |
不 |
* |
零次或多次重复出现 >=0 |
偏不 |
? |
零次或一次出现 0|1 |
https?:\/\/[\w\/.]+匹配http或https开头的URL地址 |
注:\/转义/不必须,但有的正则解析可能会用到/,就像预留关键词。regexr网站会报PARSE ERROR:Unescaped forward slash. This may cause issues if copying/pasting this expression into code. 表明不建议直接用/,养成良好习惯是和有必要的。
匹配重复次数
| 元字符 | 说明 | 示例 |
|---|---|---|
{n} |
设定精确的匹配次数n |
a{3}匹配 abaabbaaabbb中的aaa |
{n,m} |
设置匹配次数区间 | a{0,3}匹配 abaabbaaabbb中的a、 aa 和 aaa |
{n,} |
匹配至少几次 | a{2,}匹配 abaabbaaabbb中的 aa 和 aaa |
贪婪|懒惰 匹配
Cyclops 收到三份礼物,各自装在盒子里,分别是苹果、香蕉和条子。可是由于巨人眼睛不好,需要你帮他区分开这三个礼物,好方便食用。
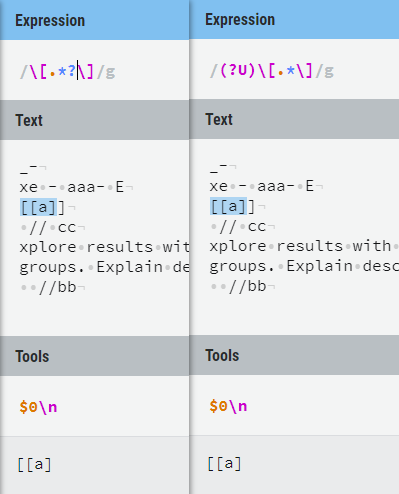
描述: 字符串[apple][banana][cop],计划匹配其中的三项。
你睡眼朦胧想用左右边界卡出来各个盒子,便使用\[.*\]模式,但是结果出来字符串本身[apple][banana][cop](贪婪模式)。Cyclops 直接吃掉了所有的东西,坏了,条子还在里边。
你使用\[.*?\]模式,匹配出来单个物品 [apple] [banana] [cop](懒惰模式)。Cyclops 懒懒的一个个吃, 但还是吃掉了条子,因为独眼巨人喜食人。
匹配特定位置:
\b单词边界,区间为[\w,\W),\B作用相反:匹配不是单词边界范围。
^ $字符串边界,分别匹配字符串开头和结束。
使用^.*$只可匹配出仅有一行数据的文本。要匹配多行,需要使用(?m)修饰符可启用多行模式匹配多行数据(?m)^.*$。
其他支持的修饰符还有:i-不区分大小写, s-dotall (单行), m-多行, x 自由间距, J-允许重复的名称, U-不贪婪
upported modifiers are: i - case insensitive, s - dotall, m - multiline, x - free spacing, J - allow duplicate names, U - ungreedy.
直观一点就上图看看:
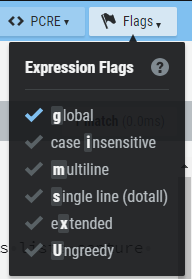
贪婪模式举例: (?U)\[.*\] 等价 \[.*?\]
()子表达式前面也用过多次,通过( )来定义。子表达式的常见用途包括:
对重复次数元字符的作用对象做出精确的设定和控制,对|操作符的OR条件做出准确的定义等。可嵌套,但需适可而止。
举例
aabbccddee中取aa或cc, 用aa|cc匹配固然可以,将来要匹配100个a或c呢。
尝试三种正则表达式a|c{2}、(a|c){2}和 [a|c]{2}来匹配 ,匹配结果:
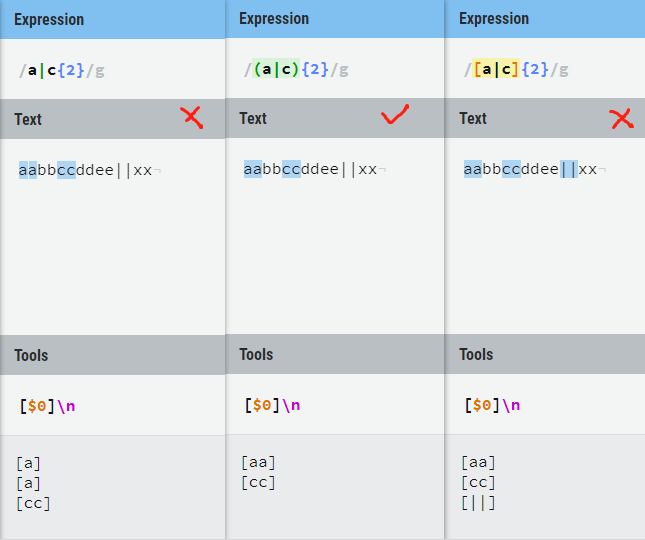
a|c{2} 乍一看匹配结果是对的,实际上看底部列出的所有结果,匹配的是单字符a或者c{2},所以匹配到结果是a a cc而不是aa或cc;
(a|c){2} 子表达式正确匹配两次a或c;
[a|c]{2} 匹配的是a 或| 或c 两次,故匹配到了多余的||。
注:图中用$0取所有匹配,因为没有分组,不能用$1等。$0代表完整的模式匹配文本,即$n`所匹配的的完整字符串
$1 \1 backreference回溯引用指在之后引用之前定义的子表达式。可以把回溯引用想象成变量。
即用$1 / \1取子表达式的分组数据。\1一般在匹配中直接使用,$1在匹配结果返回中做替换等操作。(可扩展到\n和$n, n为数字,不是回车。)
回溯引用名字听起来很高大上,实质就是用子表达式的结果,
aa bb ccc ddd A123A123 B2B2B2B2B2b2取单字母开头跟多个数字,并重复的字符串,应该取A123A123和B2B2B2B2B2。
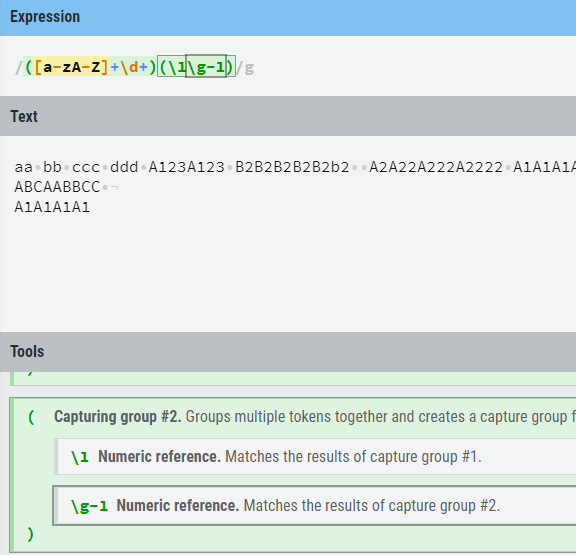
正则表达式:([a-zA-Z]{1})(\d+)(\1\2)+。\1和\2各取之前分组中的数据,+并组合匹配多次。
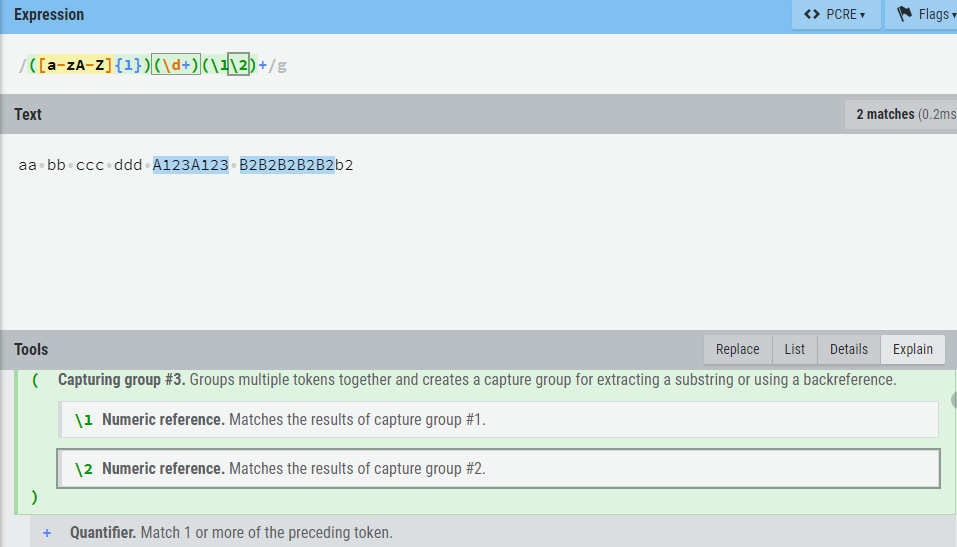
鼠标移动到Explain栏中的\2上,可以看得很清楚,\2匹配捕获#2组的结果(\d+)。
网站中对回溯(数字)引用(numeric reference)的解释和示例:
Matches the results of a capture group. For example \1 matches the results of the first capture group & \3 matches the third.
There are multiple syntaxes for this feature: \1 \g1 \g{1}.The latter syntaxes support relative values preceded by + or -. For example \g-1 would match the group preceding the reference.
Example
(\w)a\1
hah dad bad dab gag gab
看到有一个\g-1可以引用前一个组,那就引出了一个
未解之谜
([a-zA-Z]+\d+)(\1\g-1)此处\g-1代表(\1\g-1)这个组本身。
有点递归的味道,但还没有更清晰的想法。留待以后再研究。(模糊的想法是未成形的,语义化不出来则不成思想,这是意和言的统一。不可麻痹自己)
比如:在vscode替换字符的时候,使用子表达式比如(.*)匹配每一行并通过$1取结果做其他操作。不用子表达式()则不可用$1取结果(更多结果用$n)。注:$0匹配所有问题,子表达式节中最后有提。
替换自己已用过多次,把实验节中的举例拿过来。
0 => string ‘3EC6C43A0A693BD72E2A74EB4318E6C8‘ (length=32)
1 => string ‘3272E5C80A9A11A974DA212AA8A8BD28‘ (length=32)
2 => string ‘327CCB7E0A9A11A974DA212A94690D02‘ (length=32)
3 => string ‘327242740A6903923CB2A07E4145D71B‘ (length=32)
4 => string ‘32A87AE20A9A11A974DA212A1AED92A9‘ (length=32)
5 => string ‘32CE77E30A9A11A974DA212A5AA2E2DB‘ (length=32)
6 => string ‘4EE1BC220A693BD7138327E7B220E9A1‘ (length=32)
7 => string ‘4EE772830A9A11A93DA15BC986243AA8‘ (length=32)
8 => string ‘4E26C2200A693BD7138327E7B949BC9D‘ (length=32)
9 => string ‘4E2C52900A9A11A93DA15BC95AD6269A‘ (length=32)
10 => string ‘420029500A9A11A93DA15BC9A39C6520‘ (length=32)
11 => string ‘426B68D70A9A11A93DA15BC9E5650D90‘ (length=32)
12 => string ‘426E27270A9A11A93DA15BC945328A3E‘ (length=32)
13 => string ‘E5AAD21C0A693BD700102B14B94672DB‘ (length=32)
14 => string ‘E7836D080A693BD700102B149B7365A7‘ (length=32)
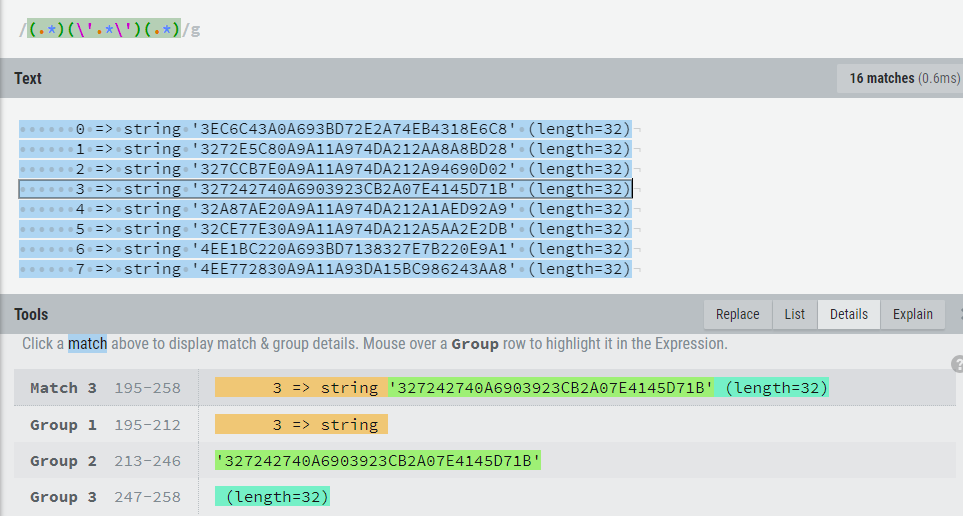
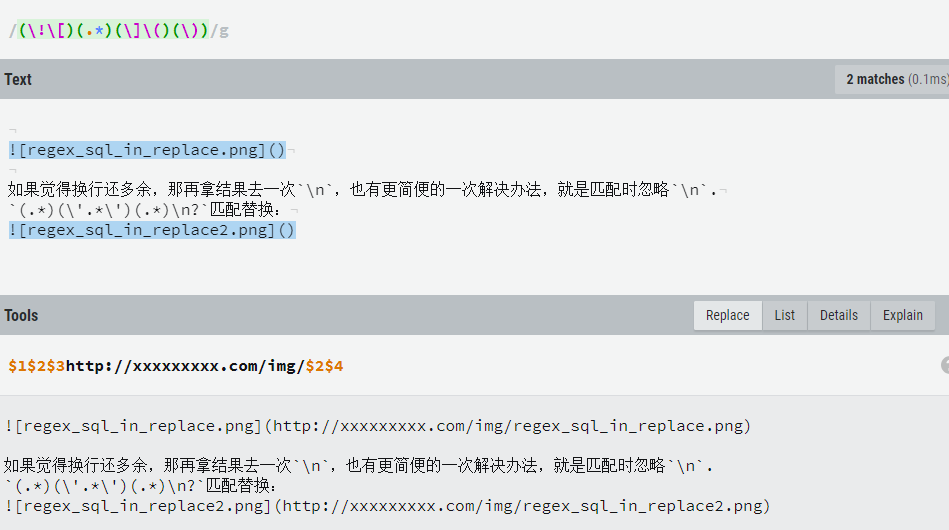
15 => string ‘ED652E220A69249067892A3D470C8D06‘ (length=32)处理为逗号分隔的字符串,好在sql中 in (形如‘A‘,‘B‘)。
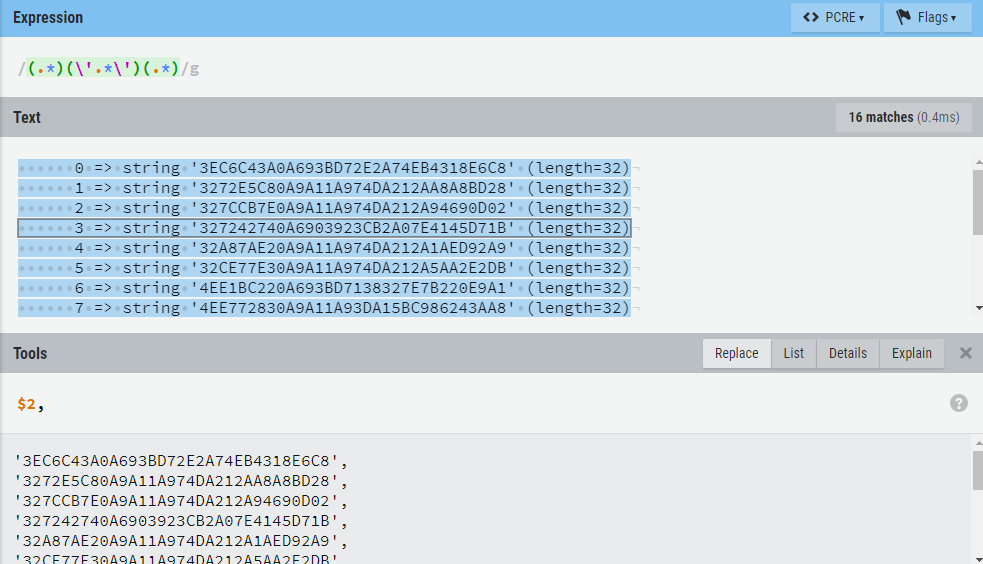
直接使用(\‘.*\‘)可以匹配到每个带引号的ID,要替换完成还需要把其他的无用块过滤掉,(.*)(\‘.*\‘)(.*) 分成三组,取第二组即可。网站的图形化工具很方便可以看到每组匹配的串
$2,替换结果:
如果觉得换行还多余,那再拿结果去一次\n,也有更简便的一次解决办法,就是匹配时忽略\n.
(.*)(\‘.*\‘)(.*)\n?匹配替换:
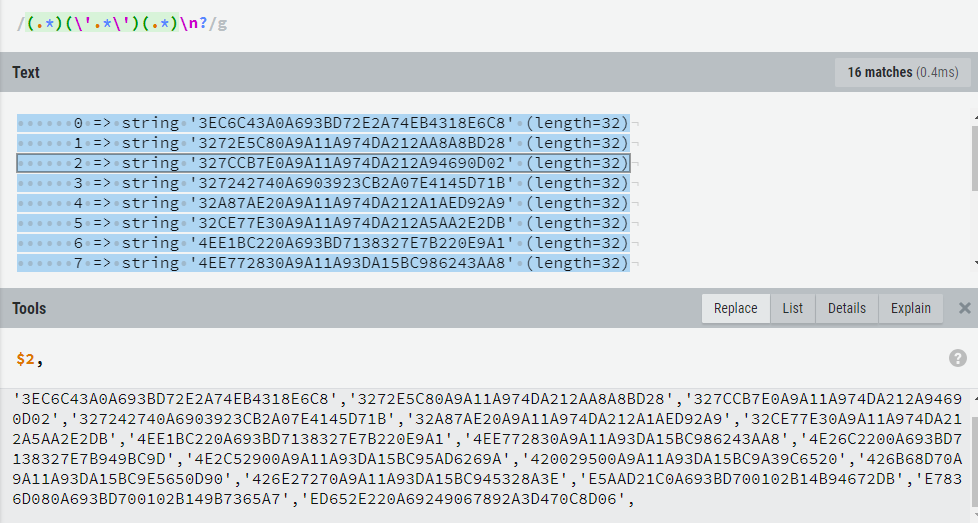
最后一个逗号,手动去掉吧。(:
写md时,传图片到服务器太麻烦,先在描述处写个文件名![201.png]()放着,写完传完之后才放真正的图片地址http://xxxxxxxxx.com/img/201.png。比如这篇就是如此,截取一段

使用
# 匹配
(\!\[)(.*)(\]\()(\))
# 替换
$1$2$3http://xxxxxxxxx.com/img/$2$4演示
Matches a group after/before the main expression without including it in the result.
(正)向前查找 (?=)
在主表达式之后匹配一个组, 而不将其包括在结果中。
(正)向后查找 (?<=)
在主表达式之前匹配一个组, 而不将其包括在结果中。
负向前查找 (?!)
将向前查找不与给定模式相匹配的文本。
负向后查找 (?<!)
将向后查找不与给定模式相匹配的文本。
举例
aa+$120
bb $130
cc $140
dd+$150用模式(?<=\+\$)([0-9.]+)(?!\n)匹配到12和150。
主表达式之前匹配+$字符串(向后查找),之后匹配不以\n回车结束(负向前查找)的数字和小数点(主表达式)。前后查找会匹配响应规则但不包含到结果字符串中。只匹配不消费

匹配到12而不是120,因为之后有回车。
注:向前查找模式的长度是可变的,它们可以包含.和+之类的元字符,所以非常灵活。而向后查找模式的长度只能是固定长度。难怪,试着用(?<=.*)匹配,正则解析服务崩溃。
正则表达式里的条件:
?匹配前一个字符或表达式,如果它存在。
?=和?<=前后查找匹配前后的文本,如果它存在。
回溯引用条件
(?(backreference)true-regex|false-regex)
前后查找条件
同回溯引用条件,只是条件不是分组,而是条件(?(lookaround)true-regex|false-regex)
回溯引用条件
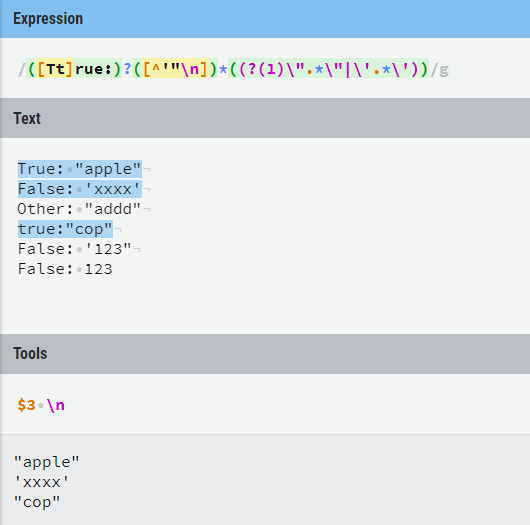
模式:([Tt]rue:)?([^‘"\n])*((?(1)\".*\"|\‘.*\‘))
在true:后面选取双引号内的值,其他参数选取单引号中的值。
前后查找条件
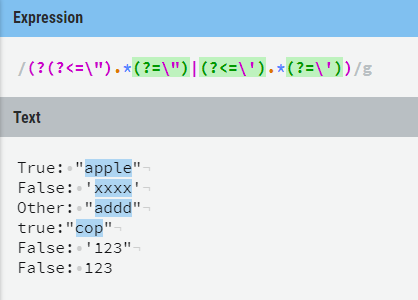
模式:((?(?<=\").*(?=\")|(?<=\‘).*(?=\‘))),取双引号对或者单引号对包含的字符串。
用向后查找在表达式之前找双引号,找到则找下一个双引号,否则,取单引号数据(这里又用前后查找只为去掉引号本身)。
A great many people think they are thinking when they are merely rearranging their prejudices. William James
很多人觉得他们在思考,但实际上只是重新安排自己的偏见。——威廉·詹姆斯

标签:hello 去掉 眼睛 必知必会 存在 this 底部 man express
原文地址:https://www.cnblogs.com/warcraft/p/10098660.html