标签:str 都对 细节 小数 完全 lis 不包含 技术 array
public Node createTreee(List<Node> nodes){
while (nodes.size()>1){
Collections.sort(nodes);
Node left = nodes.get(nodes.size()-1);
Node right = nodes.get(nodes.size()-2);
Node parent = new Node(null,left.getWeight()+right.getWeight());
parent.setLeft(left);
parent.setRight(right);
nodes.remove(nodes.size()-1);
nodes.remove(nodes.size()-1);
nodes.add(parent);
}
return nodes.get(0);
}
//广度遍历
public static List<Node> levelTraverse(Node root){
List<Node> list = new ArrayList<Node>();
Queue<Node> queue = new ArrayDeque<Node>();
if (root != null) {
queue.offer(root);
root.getLeft().setCode(root.getCode() + "0");
root.getRight().setCode(root.getCode() + "1");
}
while (!queue.isEmpty()) {
list.add(queue.peek());
Node node = queue.poll();
if (node.getLeft() != null)
node.getLeft().setCode(node.getCode() + "0");
if (node.getRight() != null)
node.getRight().setCode(node.getCode() + "1");
if (node.getLeft() != null) {
queue.offer(node.getLeft());
}
if (node.getRight() != null) {
queue.offer(node.getRight());
}
}
return list;
}
结点实现类
public Node(T data,double weight){
this.data = data;
this.weight = weight;
this.code="";
}
public Node(T data, double weight, String code){
this.data = data;
this.weight = weight;
this.code = code;
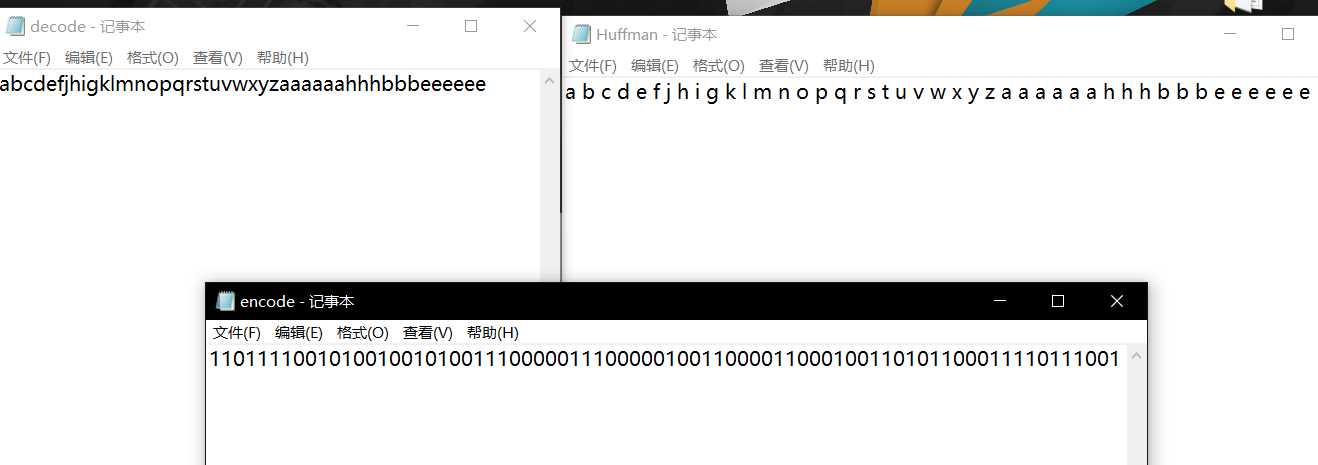
}

标签:str 都对 细节 小数 完全 lis 不包含 技术 array
原文地址:https://www.cnblogs.com/326477465-a/p/10105230.html