标签:bubuko 验证 mode save dfs 图片 build filter park
1 package code.parquet 2 3 import java.net.URI 4 5 import org.apache.hadoop.conf.Configuration 6 import org.apache.hadoop.fs.{Path, FileSystem} 7 import org.apache.spark.sql.{SaveMode, SparkSession} 8 9 /** 10 * Created by zhen on 2018/12/11. 11 */ 12 object ParquetIO { 13 // 指定hdfs根节点 14 private val hdfsRoot = "hdfs://172.20.32.163:8020" 15 // 获取HDFS路径 16 def getPath(path: String): Path = { 17 if (path.toLowerCase().startsWith("hdfs://")) { 18 new Path(path) 19 } else { 20 new Path(hdfsRoot + path) 21 } 22 } 23 def main(args: Array[String]) { 24 val spark = SparkSession.builder().appName("parquet").master("local[2]").getOrCreate() 25 spark.sparkContext.setLogLevel("WARN") // 设置日志级别为WARN 26 val fsUri = new URI(hdfsRoot) 27 val fs = FileSystem.get(fsUri, new Configuration()) 28 val path = hdfsRoot + "/YXFK/compute/KH_JLD" 29 val has = fs.exists(getPath(path)) 30 if(has){ 31 // 读取hdfs文件系统parquet数据 32 val dataFrame = spark.read.parquet(path) 33 dataFrame.show(10) 34 // 筛选,过滤数据 35 val result = dataFrame.select("JLDBH", "JLDDZ", "JLDMC", "JLFSDM", "CJSJ") 36 .filter("JLDDZ is not null AND JLFSDM = 3") 37 .sort("JLDBH") 38 result.show(10) 39 // 写入部分数据到本地 40 result.write.mode(SaveMode.Overwrite).parquet("E:\\result") 41 } 42 // 读取本地parquet数据 43 val localDataFrame = spark.read.parquet("E:\\jld.parquet") 44 localDataFrame.show(10) 45 // 读取写入数据验证 46 val resultSpace = spark.read.parquet("E:\\result") 47 resultSpace.show(10) 48 } 49 }
结果:
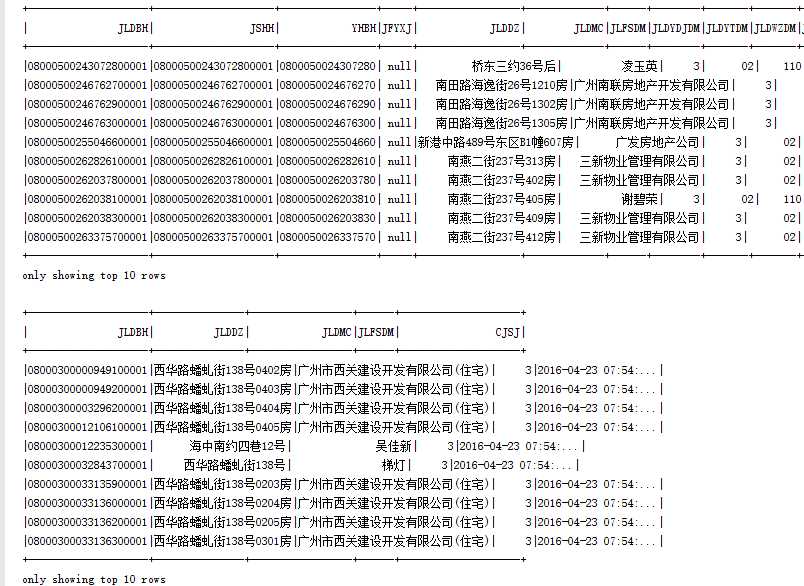
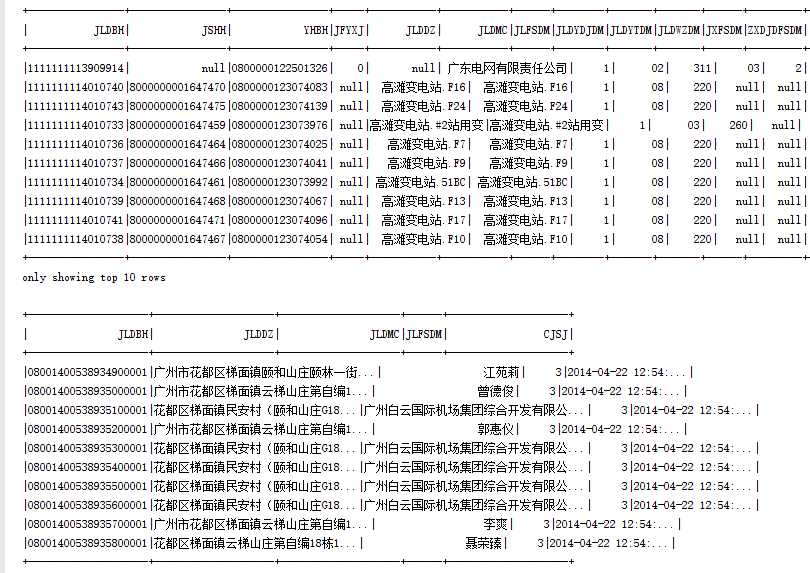
分析:Spark读取parquet数据默认为目录,因此可以只指定到你要读取的上级目录即可(本地模式除外),当保存为parquet时,会自动拆分,因此只能指定为上级目录。

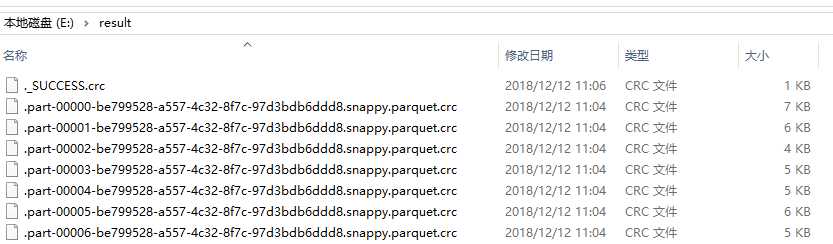

标签:bubuko 验证 mode save dfs 图片 build filter park
原文地址:https://www.cnblogs.com/yszd/p/10107443.html