标签:add 浏览次数 十分 kaggle count() rop 相关 代码 ide
‘channelGrouping‘, ‘customDimensions‘, ‘date‘, ‘device‘, ‘fullVisitorId‘, ‘geoNetwork‘, ‘hits‘, ‘socialEngagementType‘, ‘totals‘, ‘trafficSource‘, ‘visitId‘, ‘visitNumber‘, ‘visitStartTime‘

import os import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns import json from pandas.io.json import json_normalize from datetime import datetime from ast import literal_eval import warnings warnings.filterwarnings(‘ignore‘) data_path = ‘C:\\Project\\Kaggle\\Revenue_Prediction\\data\\‘
def read_df(path, file_name, nrows = None): os.chdir(path) df = pd.read_csv(file_name, dtype = {‘fullVisitorId‘: ‘str‘, ‘visitId‘: ‘str‘}, chunksize = 10000) return df train_head = read_df(data_path, ‘train_v2.csv‘, nrows = 10000)

可以看出数据的结构较为复杂,对于JSON列和类JSON列,需要经过处理,才能进行有效使用。在处理的过程中, 我也参考了其他参赛者分享的一些Kernels,再通过拆分计算的思想,完成了数据的解析。
def split_df(df, path, num_split): os.chdir(path) for i in range(num_split): temp = df[i*20000 : (i+1)*20000] temp.to_csv(str(i) + ‘.csv‘, index = False) print(‘No. %s is done.‘ %i) def load_df(csv_name, nrows = None): "csv_path:文件路径, nrows 读取行数,JSON_COLUMNS: JSON的列" df = pd.read_csv(csv_name, converters = {column: json.loads for column in JSON_COLUMNS}, # json.loads : json --> python dtype = {‘fullVisitorId‘: ‘str‘, ‘visitId‘: ‘str‘}, nrows = nrows) for col in NEW_COLUMNS: df[col][df[col] == "[]"] = "[{}]" df[col] = df[col].apply(literal_eval).str[0] for column in JSON_COLUMNS + NEW_COLUMNS: column_as_df = json_normalize(df[column]) # json column --> tabel(DataFrame) column_as_df.columns = [f"{column}.{subcolumn}" for subcolumn in column_as_df.columns] # f-string in Python 3.6 # Extract the product and promo names from the complex nested structure into a simple flat list: if ‘hits.product‘ in column_as_df.columns: column_as_df[‘hits.v2ProductName‘] = column_as_df[‘hits.product‘].apply(lambda x: [p[‘v2ProductName‘] for p in x] if type(x) == list else []) column_as_df[‘hits.v2ProductCategory‘] = column_as_df[‘hits.product‘].apply(lambda x: [p[‘v2ProductCategory‘] for p in x] if type(x) == list else []) del column_as_df[‘hits.product‘] if ‘hits.promotion‘ in column_as_df.columns: column_as_df[‘hits.promoId‘] = column_as_df[‘hits.promotion‘].apply(lambda x: [p[‘promoId‘] for p in x] if type(x) == list else []) column_as_df[‘hits.promoName‘] = column_as_df[‘hits.promotion‘].apply(lambda x: [p[‘promoName‘] for p in x] if type(x) == list else []) del column_as_df[‘hits.promotion‘] df = df.drop(column, axis = 1).merge(column_as_df, left_index = True, right_index = True) df.to_csv(‘exjson_‘ + csv_name.split(‘.‘)[0] + ‘.csv‘, index = False) return df def exjson(path, num): os.chdir(path) files = [str(d) + ‘.csv‘ for d in range(num)] for i in files: load_df(i) print(‘No. {} is done.‘.format(i.split(‘.‘)[0])) def concat_df(path, num, outname): "path: path_train/path_test; num: 86/21" os.chdir(path) file_list = [‘exjson_{}.csv‘.format(i) for i in range(num)] df_list = [] for file in file_list: dfname = file.split(‘.‘)[0] dfname = pd.read_csv(file, dtype = {‘fullVisitorId‘: ‘str‘, ‘visitId‘: ‘str‘}) df_list.append(dfname) df = pd.concat(df_list, ignore_index = True) df.to_csv(outname, index = False) return df def bug_fix(df): drop_list = df[df[‘date‘] == "No"].index.tolist() df = df.drop(drop_list) print(df) return df
由于比较担心计算能力,拆分、解析、组合的过程被分别执行,且存储了过程结果,三者的主要函数见上面折叠的代码。
此后又对数据做出了一些简单处理,分离了年月日的信息,将totals.transactionRevenue取了对数(np.log1p),去掉了缺失值过多和数值单一的列,下面将主要对浏览、购买次数和时间进行分析。
all_precleaning = read_df(path_data, ‘all_data_precleaning.csv‘) all_eda = all_precleaning[[‘fullVisitorId‘, ‘visitStartTime‘, ‘visitNumber‘, ‘totals.transactionRevenue‘, ‘totals.hits‘, ‘totals.pageviews‘, ‘totals.timeOnSite‘, ‘totals.newVisits‘, ‘date‘]]
all_precleaning 总共有70列,为了突出重点展示,本文只对以上特征进行分析。
提取年和月作为一列,方便后续分组。
all_eda[‘yearMonth‘] = all_eda.apply(lambda x: x[‘date‘].split(‘-‘)[0] + x[‘date‘].split(‘-‘)[1], axis = 1)

计算过程中,将仅浏览一次的数据单独计算; 其余数据根据 fullVisitorId 进行分组累计,每个分组内按照浏览时间由小到大排列,以便标记次数。
计算特征的代码较长,折叠于下方,结果为29列。
def add_groupby_col(df, new_column_names, by = ‘fullVisitorId‘, agg_cols = [‘totals.transactionRevenue‘], aggfunc =[‘count‘]): "new_column_names: a list of col names" temp = df.groupby(by)[agg_cols].aggregate(aggfunc) temp.columns = new_column_names df = pd.merge(df, temp, left_on = ‘fullVisitorId‘, right_index = True, how = ‘left‘) return df def calculate_id_features(df): df = df.sort_values(by = ‘visitNumber‘) df[‘buy‘] = df.apply(lambda x: 1 if x[‘totals.transactionRevenue‘]>0 else 0, axis = 1) df[‘buyNumber‘] = df[‘buy‘].cumsum() df[‘nextBuyGroup‘] = df[‘buyNumber‘] - df[‘buy‘] next_buy_time = df.groupby(‘nextBuyGroup‘).agg({‘visitStartTime‘: ‘max‘}) next_buy_time.columns = [‘nextBuyTime‘] df = pd.merge(df, next_buy_time, left_on = ‘buyNumber‘, right_index = True, how = ‘left‘) df[‘sumRevenue‘] = df[‘totals.transactionRevenue‘].sum() df[‘everBuy‘] = df.apply(lambda x: 1 if x[‘sumRevenue‘]>0 else 0, axis = 1) df[‘buyTimes‘] = df[‘buy‘].sum() df[‘averageRevenue‘] = df.apply(lambda x: x[‘sumRevenue‘]/x[‘buyTimes‘] if x[‘buyTimes‘]>0 else 0, axis = 1) df[‘firstVisitTime‘] = df[‘visitStartTime‘].min() df[‘lastVisitTime‘] = df[‘visitStartTime‘].max() df[‘sinceFirstVisit‘] = df[‘visitStartTime‘] - df[‘firstVisitTime‘] df[‘sinceFirstVisit.day‘] = df[‘sinceFirstVisit‘] // (24*3600) df[‘sinceFirstVisit.period‘] = pd.cut(df[‘sinceFirstVisit.day‘], [-1, 30, 60, 120, 240, 800], labels = [‘within30‘, ‘30-60‘, ‘60-120‘, ‘120-240‘, ‘240-800‘]) def get_timegap(df_l): timegap = df_l[‘nextBuyTime‘] - df_l[‘visitStartTime‘] if timegap > 0: return timegap df[‘timeToBuy‘] = df.apply(lambda x: get_timegap(x), axis = 1) df[‘timeToBuy‘].fillna(0, inplace = True) df[‘timeToBuy.day‘] = df.apply(lambda x: x[‘timeToBuy‘]/(24*3600) if x[‘everBuy‘]==1 else -10, axis = 1) df[‘revNum‘] = df.apply(lambda x: x[‘buyNumber‘] if x[‘buy‘]==1 else 0, axis = 1) df[‘firstBuy‘] = df.apply(lambda x: 1 if x[‘revNum‘]==1 else 0, axis = 1) df[‘reBuy‘] = df.apply(lambda x: 1 if x[‘revNum‘]>1 else 0, axis = 1) return df def one_visit_features(df): df[‘buy‘] = df.apply(lambda x: 1 if x[‘totals.transactionRevenue‘]>0 else 0, axis = 1) df[‘sumRevenue‘] = df[‘totals.transactionRevenue‘].sum() df[‘everBuy‘] = df.apply(lambda x: 1 if x[‘sumRevenue‘]>0 else 0, axis = 1) #df[‘viewTimes‘] = df[‘visitStartTime‘].count() df[‘buyTimes‘] = df[‘buy‘].sum() df[‘averageRevenue‘] = df.apply(lambda x: x[‘sumRevenue‘]/x[‘buyTimes‘] if x[‘buyTimes‘]>0 else 0, axis = 1) df[‘firstVisitTime‘] = df[‘visitStartTime‘] df[‘lastVisitTime‘] = df[‘visitStartTime‘] df[‘revNum‘] = df.apply(lambda x: 1 if x[‘buy‘]==1 else 0, axis = 1) df[‘firstBuy‘] = df.apply(lambda x: 1 if x[‘buy‘]==1 else 0, axis = 1) df[‘reBuy‘] = 0 return df all_eda = add_groupby_col(all_eda, [‘viewTimes‘]) all_eda_oneview = all_eda[all_eda[‘viewTimes‘] == 1] all_eda_views = all_eda[all_eda[‘viewTimes‘] > 1] all_eda_oneview_cal = one_visit_features(all_eda_oneview) all_eda_views_cal = all_eda_views.groupby(‘fullVisitorId‘).apply(calculate_id_features) all_eda_cal = pd.concat([all_eda_views_cal, all_eda_oneview_cal], ignore_index = True) all_eda_cal.to_csv(‘all_eda_cal.csv‘, index = False)
def view_range_agg(df): "df: all_eda_cal" view_times = df.groupby(‘fullVisitorId‘).agg({‘viewTimes‘: ‘max‘}) view_times_agg = view_times.groupby(‘viewTimes‘).agg({‘viewTimes‘: ‘count‘}) view_times_agg.columns = [‘num‘] view_times_agg.reset_index(inplace = True) view_times_agg[‘viewRange‘] = pd.cut(view_times_agg[‘viewTimes‘], [-1, 1, 2, 3, 6, 10, 20, 40, 80, 500], labels = [‘1‘, ‘2‘, ‘3‘, ‘4-6‘, ‘7-10‘, ‘11-20‘, ‘21-40‘, ‘41-80‘, ‘81-500‘]) result = view_times_agg.groupby(‘viewRange‘).agg({‘num‘: ‘sum‘}) return result def buy_range_agg(df): "df: all_eda_agg" buy_times = df.groupby(‘fullVisitorId‘).agg({‘buyTimes‘: ‘max‘}) buy_times_agg = buy_times.groupby(‘buyTimes‘).agg({‘buyTimes‘: ‘count‘}) buy_times_agg.columns = [‘num‘] buy_times_agg.reset_index(inplace = True) buy_times_agg[‘buyRange‘] = pd.cut(buy_times_agg[‘buyTimes‘], [-1, 0, 1, 2, 3, 6, 10, 33], labels = [‘0‘, ‘1‘, ‘2‘, ‘3‘, ‘4-6‘, ‘7-10‘, ‘11-33‘]) result = buy_times_agg.groupby(‘buyRange‘).agg({‘num‘: ‘sum‘}) return result view_range = view_range_agg(all_eda_cal) buy_range = buy_range_agg(all_eda_cal) print(‘浏览次数分布如下:‘) print(view_range) print(‘-‘ * 10) print(‘购买次数分布如下:‘) print(buy_range)
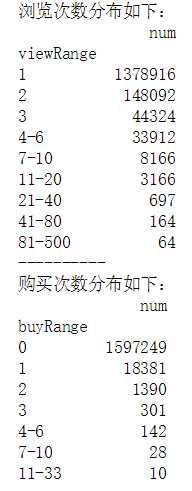
包含所有取值可能,会导致部分数据无法获得直观展示
plt.rcParams[‘font.sans-serif‘]=[‘SimHei‘] fig,axes = plt.subplots(1,2,figsize = (20,6)) view_range.plot.barh(ax = axes[0]) axes[0].set_title(‘浏览次数分布‘) buy_range.plot.barh(ax = axes[1]) axes[1].set_title(‘购买次数分布‘)
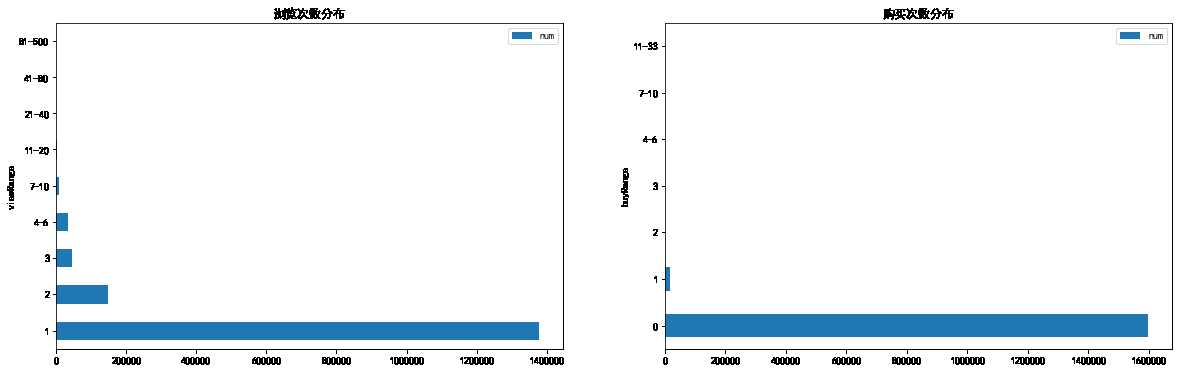
fig,axes = plt.subplots(1,2,figsize = (20,6)) view_range[2:].plot.barh(ax = axes[0]) axes[0].set_title(‘浏览次数分布‘) buy_range[2:].plot.barh(ax = axes[1]) axes[1].set_title(‘购买次数分布‘)
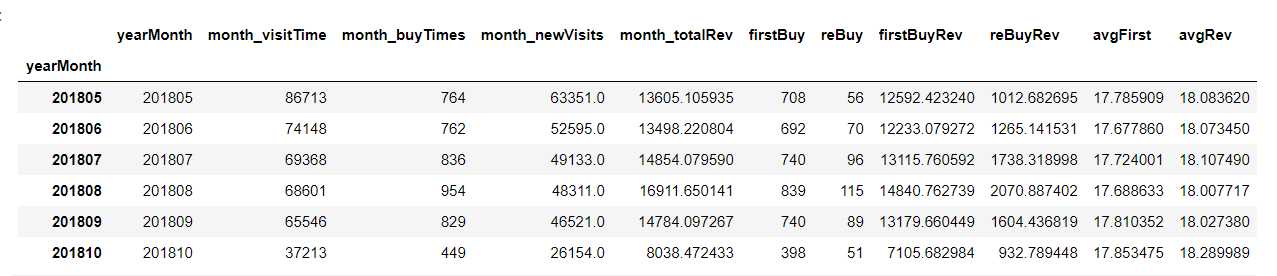
def yearMonth_des(df): "df: all_eda_cal" # 总购买数 新增浏览 总销售额 yearmonth_1 = df.groupby(‘yearMonth‘).agg({‘buy‘: ‘sum‘, ‘totals.newVisits‘: ‘sum‘, ‘totals.transactionRevenue‘: ‘sum‘}) yearmonth_1.columns = [‘month_buyTimes‘, ‘month_newVisits‘, ‘month_totalRev‘] # 总浏览数 yearmonth_visit_time = df.groupby(‘yearMonth‘).apply(lambda x: len(x)).reset_index() yearmonth_visit_time.columns = [‘yearMonth‘, ‘month_visitTime‘] yearmonth_visit_time.index = yearmonth_visit_time[‘yearMonth‘] # 新增购买 / 重复购买 销售额 # 此时的重复购买指:不是第一次购买,有可能第一次购买就发生于当月 first_buy_rev = df[df[‘firstBuy‘]==1].groupby(‘yearMonth‘).agg({‘totals.transactionRevenue‘: ‘sum‘}) rebuy_rev = df[df[‘reBuy‘]==1].groupby(‘yearMonth‘).agg({‘totals.transactionRevenue‘: ‘sum‘}) first_buy_rev.columns = [‘firstBuyRev‘] rebuy_rev.columns = [‘reBuyRev‘] # 统计新增/重复购买人数 按年月分组 yearmonth_2 = df.groupby(‘yearMonth‘).agg({‘firstBuy‘: ‘sum‘, ‘reBuy‘: ‘sum‘}) # 将分散的groupby特征整合到一起 yearmonth_des = pd.concat([yearmonth_visit_time, yearmonth_1, yearmonth_2, first_buy_rev, rebuy_rev], axis = 1) # 计算首次购买和重复购买的金额均值 yearmonth_des[‘avgFirst‘] = yearmonth_des[‘firstBuyRev‘] / yearmonth_des[‘firstBuy‘] yearmonth_des[‘avgRev‘] = yearmonth_des[‘reBuyRev‘] / yearmonth_des[‘reBuy‘] #yearmonth_des.to_csv(‘yearmonth_group.csv‘, index = False) return yearmonth_des yearmonth_des = yearMonth_des(all_eda_cal) yearmonth_des.index = yearmonth_des.index.astype(str) yearmonth_des.tail(6)
fig, ax = plt.subplots(2, 1, figsize = (20, 16)) ax[0].plot(yearmonth_des[‘month_visitTime‘]) ax[0].plot(yearmonth_des[‘month_newVisits‘]) ax[0].plot(yearmonth_des[‘month_buyTimes‘]) ax[0].legend() ax[0].set_title(‘浏览次数 新增浏览 购买次数‘) ax[1].plot(yearmonth_des[‘month_buyTimes‘]) ax[1].plot(yearmonth_des[‘firstBuy‘]) ax[1].plot(yearmonth_des[‘reBuy‘]) ax[1].legend() ax[1].set_title(‘购买次数 首次购买 重复购买‘)
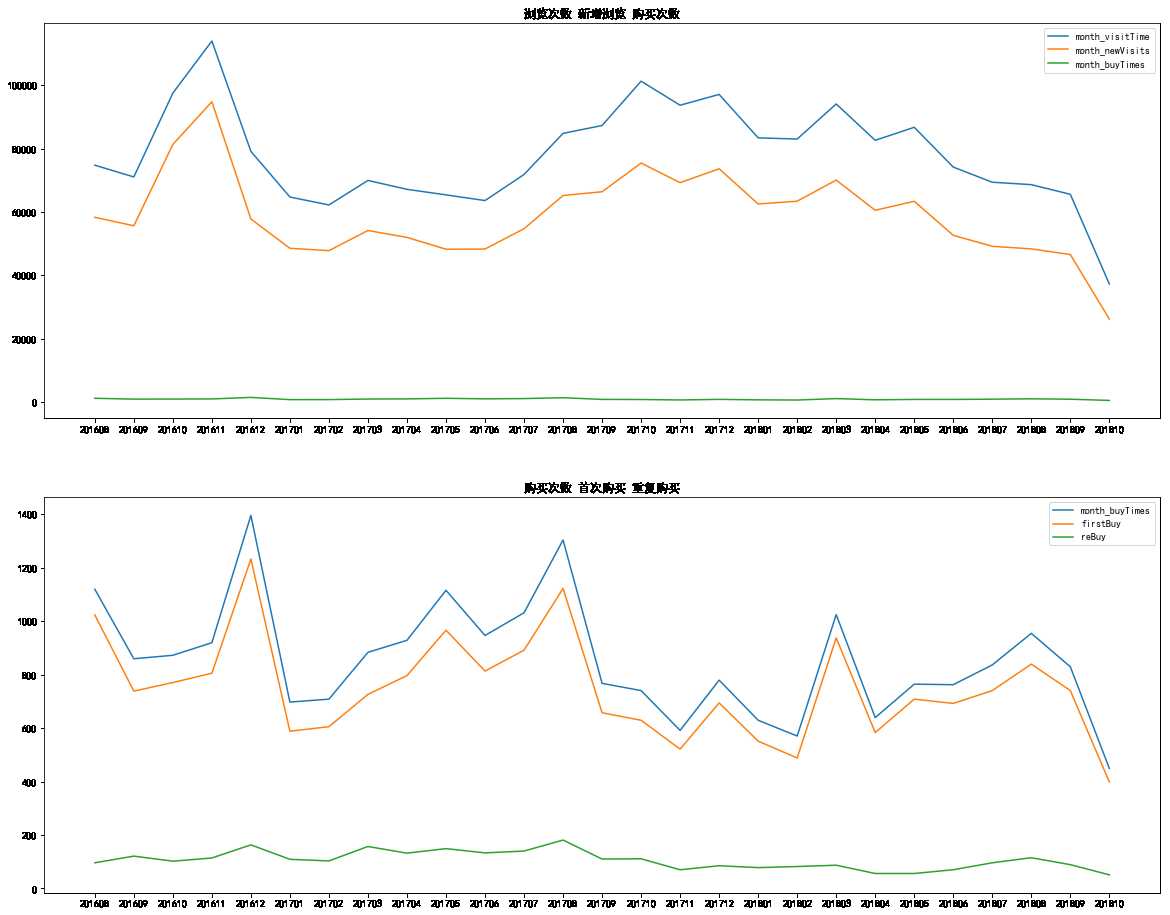
yearmonth_buy_pivo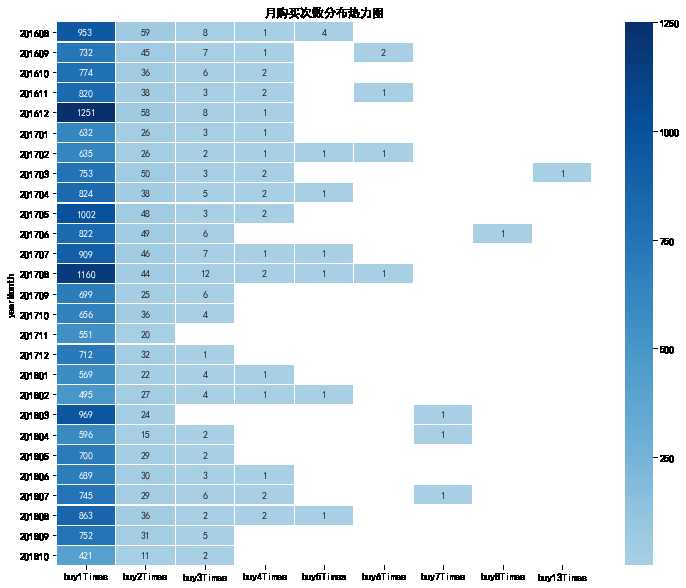
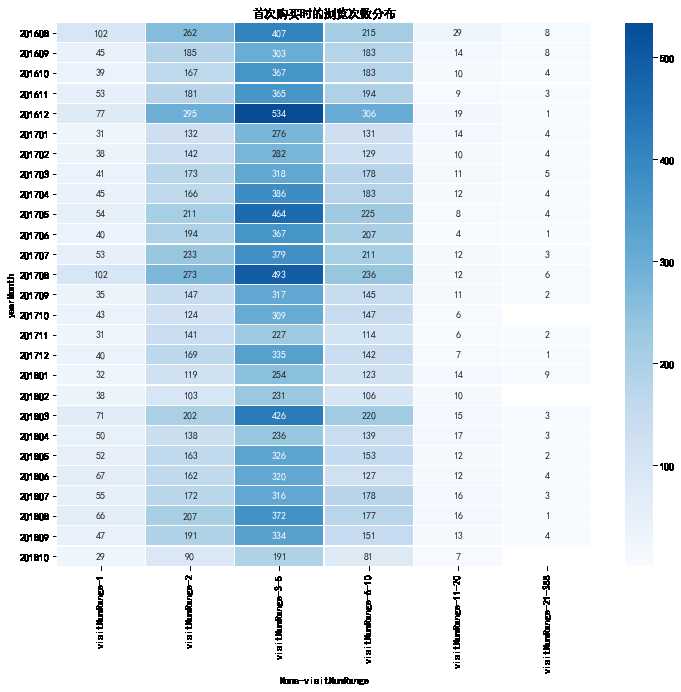
## 表2 # 首次购买的用户需要的浏览次数 区间 all_eda_cal[‘visitNumRange‘] = pd.cut(all_eda_cal[‘visitNumber‘], [0, 1, 2, 5, 10, 20, 388], labels = [‘1‘, ‘2‘, ‘3-5‘, ‘6-10‘, ‘11-20‘, ‘21-388‘]) firstBuy_visitNum_pivot = all_eda_cal[all_eda_cal[‘firstBuy‘]==1].pivot_table(index = ‘yearMonth‘, columns = ‘visitNumRange‘, aggfunc = {‘visitNumRange‘: ‘count‘}) firstBuy_visitNum_pivot.tail(6) plt.figure(figsize = (12, 10)) #yearmonth_buy_pivot.fillna(0, inplace = True) sns.heatmap(firstBuy_visitNum_pivot, annot = True, # 是否显示数值 fmt = ‘.0f‘, # 格式化字符串 linewidths = 0.1, # 格子边线宽度 center = 300, # 调色盘的色彩中心值,若没有指定,则以cmap为主 cmap = ‘Blues‘, # 设置调色盘 cbar = True, # 是否显示图例色带 #cbar_kws={"orientation": "horizontal"}, # 是否横向显示图例色带 #square = True, # 是否正方形显示图表 ) plt.title(‘首次购买时的浏览次数分布‘)
## 表3表4 # 首次购买和重复购买与首次浏览时间间隔的分布 firstBuy_sinceFisrtVisit_pivot = all_eda_cal[all_eda_cal[‘firstBuy‘]==1].pivot_table(index = ‘yearMonth‘, columns = ‘sinceFirstVisit.period‘, aggfunc = {‘sinceFirstVisit.period‘: ‘count‘}) reBuy_sinceFisrtVisit_pivot = all_eda_cal[all_eda_cal[‘reBuy‘]==1].pivot_table(index = ‘yearMonth‘, columns = ‘sinceFirstVisit.period‘, aggfunc = {‘sinceFirstVisit.period‘: ‘count‘}) firstBuy_sinceFisrtVisit_pivot.columns = [[‘120-240‘, ‘240-800‘, ‘30-60‘, ‘60-120‘, ‘within30‘]] reBuy_sinceFisrtVisit_pivot.columns = [[‘120-240‘, ‘240-800‘, ‘30-60‘, ‘60-120‘, ‘within30‘]] firstBuy_sinceFisrtVisit_pivot = firstBuy_sinceFisrtVisit_pivot[[‘within30‘, ‘30-60‘, ‘60-120‘, ‘120-240‘, ‘240-800‘]] reBuy_sinceFisrtVisit_pivot = reBuy_sinceFisrtVisit_pivot[[‘within30‘, ‘30-60‘, ‘60-120‘, ‘120-240‘, ‘240-800‘]] firstBuy_sinceFisrtVisit_pivot.tail(6)
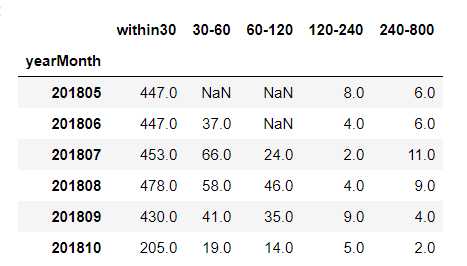
plt.figure(figsize = (12, 10)) #yearmonth_buy_pivot.fillna(0, inplace = True) sns.heatmap(firstBuy_sinceFisrtVisit_pivot.drop(‘within30‘, axis = 1), annot = True, # 是否显示数值 fmt = ‘.0f‘, # 格式化字符串 linewidths = 0.1, # 格子边线宽度 center = 30, # 调色盘的色彩中心值,若没有指定,则以cmap为主 cmap = ‘Blues‘, # 设置调色盘 cbar = True, # 是否显示图例色带 #cbar_kws={"orientation": "horizontal"}, # 是否横向显示图例色带 #square = True, # 是否正方形显示图表 ) plt.title(‘首次购买与首次浏览的时间间隔‘)
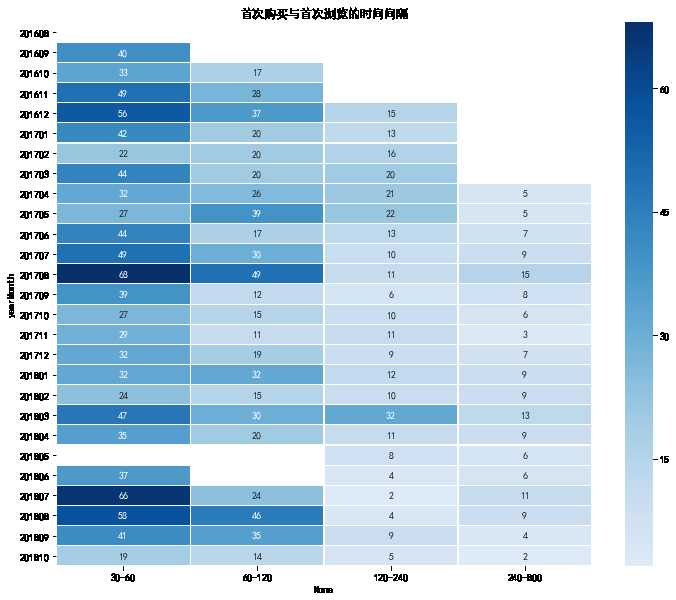
plt.figure(figsize = (12, 10)) #yearmonth_buy_pivot.fillna(0, inplace = True) sns.heatmap(reBuy_sinceFisrtVisit_pivot, annot = True, # 是否显示数值 fmt = ‘.0f‘, # 格式化字符串 linewidths = 0.1, # 格子边线宽度 center = 35, # 调色盘的色彩中心值,若没有指定,则以cmap为主 cmap = ‘Blues‘, # 设置调色盘 cbar = True, # 是否显示图例色带 #cbar_kws={"orientation": "horizontal"}, # 是否横向显示图例色带 #square = True, # 是否正方形显示图表 ) plt.title(‘重复购买与首次浏览的时间间隔‘)
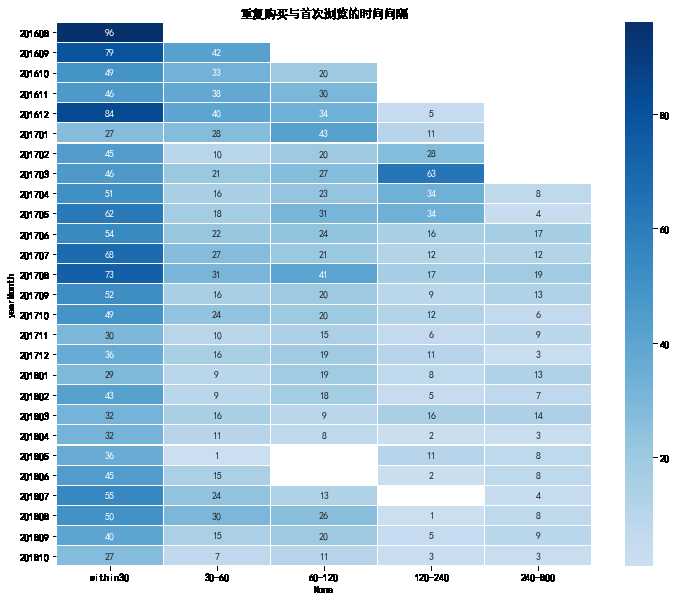
至此,我们已经对这个预测问题的基本情况有了一个初步的认识,这些数据可以为自己的交叉验证做出有效的补充。
Kaggle: Google Analytics Customer Revenue Prediction EDA
标签:add 浏览次数 十分 kaggle count() rop 相关 代码 ide
原文地址:https://www.cnblogs.com/simon95/p/10086922.html
