标签:tom 参考 模式 分享图片 步骤 element 建模 ice normal
转自:https://www.cnblogs.com/TaigaCon/p/5304563.html
算术编码是基于区间划分的,普通的概率划分需要使用到多位乘法。CABAC的算术编码为了降低计算复杂度,并便于硬件实现,采取了如下一些方法:
- 总是估计小概率符号LPS(pLPS<0.5pLPS<0.5)的概率,并将其概率离散化成64个不同概率状态。概率估计转换成基于表格的概率状态的转换(见初始化部分的描述)。
- 使用9bit的变量R与10bit的L表示当前区间,其中L为区间的起点,R为区间长度
- 每当输入新符号时,会对区间的起点LL以及区间的长度RR进行更新,在前面的二进制算术编码时,我们已经得知两者的更新方法,其中R与L的更新包含了浮点数乘法Ri?p,为了降低运算复杂度,CABAC把乘法换算成了查表的形式。换算方法如下:
- 离散化的状态pStateIdx代表了符号的概率p
- 9个bit的区间长度RR通过(R>>6)&3(R>>6)&3被量化成2个bit,即{0,1,2,3}(因为RR总是大于等于2828小于2929,在后面的归一化可以看出来)
- 有了上述两个离散的变量,区间更新所需要的乘法就能转换成查表操作,表格请查看标准9.3.3.2中的第一个表格。
- 在算术编码的过程中,尽管是同一上下文,但是概率并不是固定的,每次输入一个新符号都会改变相应上下文的概率,也就是会进行状态转换(见初始化部分的描述)
- 对近似均匀分布的语法元素,在编码和解码时选择旁路(bypass)模式,可以免除上下文建模,提高编解码的速度。
- 由于编码区间是有限位表示的,因此在输入一个符号进行区间更新后,需要进行重归一化以保证编码精度。
算术编码过程

该过程可分为5个步骤
- 通过当前编码器区间范围R得到其量化值ρ作为查表索引,然后利用状态索引pStateIdx与ρ进行查表得出RLPS的概率区间大小。
- 根据要编码的符号是否是MPS来更新算术编码中的概率区间起点L以及区间范围R
- pStateIdx==0表明当前LPS在上下文状态更新之前已经是0.5的概率,那么此时还输入LPS,表明它已经不是LPS了,因此需要进行LPS、MPS的转换
- 更新上下文模型概率状态
- 重归一化,输出编码比特。
重归一化分析


在CABAC编码过程中,在输入符号后,进行区间更新,接下来就是重归一化过程。下面就以[0,210)[0,210)表示区间[0,1)[0,1)为例,分析重归一化过程
(请注意,在该过程中,[0,210)[0,210)只起到辅助作用,实际的区间为RR)
- R<28R<28的情况,如果L<28L<28,则可知R+L<29R+L<29,那么可以确定编码区间[L,L+R)[L,L+R)在区间[0,0.5)[0,0.5)上,用二进制表示这个区间即为0.0x0.0x,因此输出00(只记录小数点后面的二进制)。最后用[0,210)[0,210)来表示区间[0,0.5)[0,0.5),也就是将原本的[0,29)[0,29)线性扩增到[0,210)[0,210)
- R<28R<28的情况,如果L?29L?29,那么就可以确定编码区间[L,L+R)[L,L+R)在区间[0.5,1)[0.5,1)上,用二进制表示这个区间即为0.1x0.1x,因此输出11。最后用[0,210)[0,210)来表示区间[0.5,1)[0.5,1),也就是将原本的[29,210)[29,210)线性扩增到[0,210)[0,210)
- R<28R<28的情况,如果28?L<2928?L<29,则28<R+L<29+2828<R+L<29+28,编码区间[L,L+R)[L,L+R)可能在[0,0.5)[0,0.5)区间内,也有可能跨越[0,0.5)[0,0.5)与[0.5,1)[0.5,1)两个区间,即可能是0.01x0.01x,也可能是0.10x0.10x。此时可以先暂缓输出,用[0,210)[0,210)来表示区间[0.25,0.75)[0.25,0.75),也就是将原本的[28,28+29)[28,28+29)线性扩增到[0,210)[0,210),然后进入重归一化的下一个循环继续判断。
- R?28R?28的情况,无法通过L<28L<28来确定编码区间,需要通过输入下一个符号来对RR与LL进行更新后再继续进行判断,因此当前符号的编码流程结束。由于这个原因,因此在一个符号编码结束后,另一个符号编码开始前,总是28?R<2928?R<29。

输出
在编码输出“0”或者“1”的阶段,用PutBit(B)表示

关于PutBit(B)的分析,参考上面重归一化的区间图,可以看到有三种情况
- 情况1,走PutBit(0),直接输出“0”
- 情况2,走PutBit(1),直接输出“1”
- 情况3,输出可能为“10”或者“01”,因此不能直接输出,走bitsOutstanding++的步骤。在下一次编码符号时,符合情况2,走PutBit(1),此时bitsOutstanding = 1,因此输出“10”
另外,PutBit(B)不会编码第一个bit。原因是CABAC在初始化的时候,会以[0,210)[0,210)表示区间[0,1)[0,1),而在初始化区间时R=510,L=0R=510,L=0,这意味着已经进行了第一次区间选择,区间为[0,0.5)[0,0.5),需要输出“0”。PutBit(B)在此阻止这个“0”的输出,这样就能得到正确的算术编码结果了。
旁路(bypass)编码
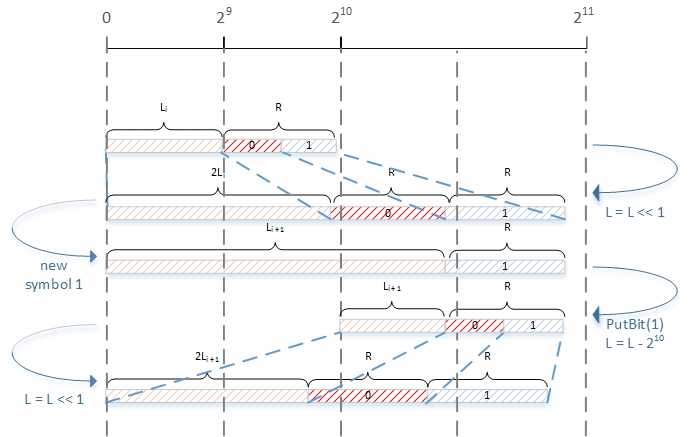
有些语法元素在二值化后选择的可能不是上述的算术编码,而是旁路编码,具体情况请查看h.264标准9.3.2的第一个表格。旁路编码中,假设待编码的符号符合近似的均匀分布。下图给出了旁路模式下的编码过程。
旁路模式有几个特点:符号均匀分布,无需对RR进行量化与查表;每编码完一个符号后,RR总是会小于2828,因此每次都需要对概率区间进行放大;把对LL的移位操作提到了前面,因此旁路编码的重归一化的区间可以看作由[0,210)[0,210)变成了[0,211)[0,211)。

下面是旁路编码的一个例子
编码结束 EncodeTerminate
在编码语法元素end_of_slice_flag以及I_PCM mb_type时(ctxIdx = 276)会调用EncodeTerminate这个编码过程。
在EncodeTerminate中,采用的是pStateIdx = 63的状态,这个状态表示的是当前宏块是否为该slice的最后一个宏块的概率。在该状态下,对概率区间的划分跟概率区间量化值无关。在编码end_of_slice_flag以及I_PCM的mb_type时,概率区间固定为RLPS=2RLPS=2。如果当前宏块为slice的最后一个宏块(end_of_slice_flag = 1)或者当前编码为PCM宏块并且编码它的mb_type I_PCM时,结束CABAC编码,调用EncodeTerminate中的EncodeFlush。具体情况请参考标准中的9.3.4.5小节以及CABAC补充讨论。

在编码完成slice的最后一个宏块后,将会调用字节填充过程。该过程会往NAL单元写入0个或者更多个字节(cabac_zero_word),目的是完成对NAL单元的封装(标准9.3.4.6)。这里有计算如下
k=?(?3×(32×BinCountsInNALunits?RawMbBits×PicSizeInMbs1024)??NumBytesInVclNalunits)/3?k=?(?3×(32×BinCountsInNALunits?RawMbBits×PicSizeInMbs1024)??NumBytesInVclNalunits)/3?
如果k>0k>0,则需要将3字节长的0x000003添加到NAL单元kk次。这里的前两字节0x0000代表了cabac_zero_word,第三个字节0x03代表一个emulation_prevention_three_byte,这两个语法元素请参考h.264语法结构分析的相关部分。
如果k?0k?0,则无需添加字节到NAL单元。
式子中的各个变量所代表的意思请查看标准
H.264---CABAC---第四步--算术编码
标签:tom 参考 模式 分享图片 步骤 element 建模 ice normal
原文地址:https://www.cnblogs.com/qing1991/p/10111376.html





