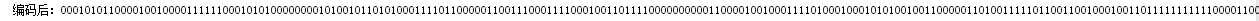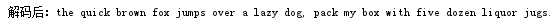标签:article 倒数 百度 pack fileread package let 代码实现 次数
这个老师上课说过。首先确定文件中各个字符的概率然后将其。按照概率大小。将概率小的放在离根节点较近的地方。
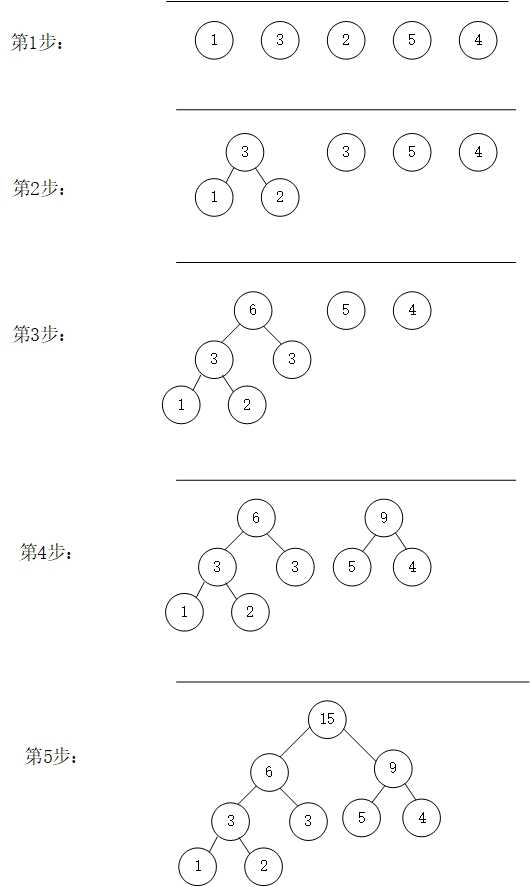
这里用数字来代表字符的概率然后,首先将概率最小的两个字符放到一起,将它们的概率合成父结点的概率,然后父结点参与比较再次在备选集中找到比较小的两两结合,然后再次合成父结点的概率。
因为哈夫曼需要考虑到父结点的影响,所以定义了相关的左孩子右孩子的方法。
package HuffmanTree;
public class HNode {
/**
* 节点类
* @author LiRui
*
*/
public String code = "";// 节点的哈夫曼编码 public String data = "";// 节点的数据
public int count;// 节点的权值
public HNode lChild;
public HNode rChild;
public HNode() {
}
public HNode(String data, int count) {
this.data = data;
this.count = count;
}
public HNode(int count, HNode lChild, HNode rChild) {
this.count = count;
this.lChild = lChild;
this.rChild = rChild;
}
public HNode(String data, int count, HNode lChild, HNode rChild) {
this.data = data;
this.count = count;
this.lChild = lChild;
this.rChild = rChild;
}
}public HuffmanNode<T> createTree(List<HuffmanNode<T>> nodes) {
while (nodes.size() > 1) {
Collections.sort(nodes);
HuffmanNode<T> left = nodes.get(nodes.size() - 2);//令其左孩子的编码为0
left.setCode("0");
HuffmanNode<T> right = nodes.get(nodes.size() - 1);//令其右孩子的编码为1
right.setCode("1");
HuffmanNode<T> parent = new HuffmanNode<T>(null, left.getWeight() + right.getWeight());
parent.setlChild(left);
parent.setrChild(right);
nodes.remove(left);
nodes.remove(right);
nodes.add(parent);
}
return nodes.get(0);
}public List<HuffmanNode<T>> breath(HuffmanNode<T> root) {
List<HuffmanNode<T>> list = new ArrayList<HuffmanNode<T>>();
Queue<HuffmanNode<T>> queue = new LinkedList<>();
if (root != null) {
queue.offer(root);
root.getlChild().setCode(root.getCode() + "0");
root.getrChild().setCode(root.getCode() + "1");
}
while (!queue.isEmpty()) {
list.add(queue.peek());
HuffmanNode<T> node = queue.poll();
if (node.getlChild() != null)
node.getlChild().setCode(node.getCode() + "0");
if (node.getrChild() != null)
node.getrChild().setCode(node.getCode() + "1");
if (node.getlChild() != null)
queue.offer(node.getlChild());
if (node.getrChild() != null)
queue.offer(node.getrChild());
}
return list;
} String result = "";
for(int f = 0; f < sum; f++){
for(int j = 0;j<letter.length;j++){
if(neirong.charAt(f) == letter[j].charAt(0))
result += code[j];
}
}for(int h = list4.size(); h > 0; h--){
string1 = string1 + list4.get(0);
list4.remove(0);
for(int i=0;i<code.length;i++){
if (string1.equals(code[i])) {
string2 = string2+""+letter[i];
string1 = "";
}
}
}Collections.frequency();来实现,里面的两个形式参数,按照第二个形式参数表现的内容,记录其在第一个列表内的重复次数,这样只需要将文件内容一每个字符的形式存放在一个列表中就行,然后进行比对即可。总的字符数目就是每一个字母的重复次数。for(int a = 0; a <= getFileLineCount(file); a++){
String tp = bufferedReader.readLine();
neirong += tp;
for(int b = 0; b < tp.length(); b++){
list2.add(String.valueOf(tp.charAt(b)));
}
Esum[0] += Collections.frequency(list2, list1.get(0));
Esum[1] += Collections.frequency(list2, list1.get(1));
Esum[2] += Collections.frequency(list2, list1.get(2));
Esum[3] += Collections.frequency(list2, list1.get(3));
Esum[4] += Collections.frequency(list2, list1.get(4));
Esum[5] += Collections.frequency(list2, list1.get(5));
Esum[6] += Collections.frequency(list2, list1.get(6));
Esum[7] += Collections.frequency(list2, list1.get(7));
Esum[8] += Collections.frequency(list2, list1.get(8));
Esum[9] += Collections.frequency(list2, list1.get(9));
Esum[10] += Collections.frequency(list2, list1.get(10));
Esum[11] += Collections.frequency(list2, list1.get(11));
Esum[12] += Collections.frequency(list2, list1.get(12));
Esum[13] += Collections.frequency(list2, list1.get(13));
Esum[14] += Collections.frequency(list2, list1.get(14));
Esum[15] += Collections.frequency(list2, list1.get(15));
Esum[16] += Collections.frequency(list2, list1.get(16));
Esum[17] += Collections.frequency(list2, list1.get(17));
Esum[18] += Collections.frequency(list2, list1.get(18));
Esum[19] += Collections.frequency(list2, list1.get(19));
Esum[20] += Collections.frequency(list2, list1.get(20));
Esum[21] += Collections.frequency(list2, list1.get(21));
Esum[22] += Collections.frequency(list2, list1.get(22));
Esum[23] += Collections.frequency(list2, list1.get(23));
Esum[24] += Collections.frequency(list2, list1.get(24));
Esum[25] += Collections.frequency(list2, list1.get(25));
Esum[26] += Collections.frequency(list2, list1.get(26));
Esum[27] += Collections.frequency(list2, list1.get(27));
Esum[28] += Collections.frequency(list2, list1.get(28));
}for(int c = 0; c < Esum.length; c++)
sum += Esum[c];
System.out.println("总字母个数:" + sum);在此部分我用了一个可以确定文件内容行数的方法,便于当文件出现多行的时候的读写和编码、解码的相关操作。
File file = new File("英文文件.txt");
File file1 = new File("编码文件.txt");
File file2 = new File("解码文件.txt");
if (!file1.exists() && !file2.exists())
{
file1.createNewFile();
file2.createNewFile();
}
FileReader fileReader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(fileReader);
FileWriter fileWriter1 = new FileWriter(file1);
FileWriter fileWriter2 = new FileWriter(file2);
fileWriter1.write(result);
fileWriter2.write(string2);
fileWriter1.close();
fileWriter2.close(); 哈夫曼是一种用于压缩的算法,是一种很实用的算法,但可能是个人能力的限制,在具体实现过程中遇见了很多困难,在具体的代码实现中,借鉴了很多网页和同学的思路。标签:article 倒数 百度 pack fileread package let 代码实现 次数
原文地址:https://www.cnblogs.com/15248252144dzx/p/10111583.html