标签:架构 字段 溢出 技术分享 htm 出错 消息队列 image 分享图片
分布式事务就是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。简单的说,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
为什么我们要反反复复的强调一致性?
因为,一致性就保证了我们的数据,不会出大问题,至少不会导致出现对账对不上等奇怪的问题。 不然的话,扯皮都扯不清。这就是为什么我们宁愿让我们的交易失败,也不愿意让其出现不一致的情况。所以,涉及多个DML操作,特别是更新、新增、删除操作,我们一定要把它们放入一个事务中,进行事务的控制。
为什么分布式环境中,一致性的问题被如此多的提及,因为分布式环境中,网络问题更多,出现问题的机会会更多,特别又是高并发大数据量的情况下。我们开发环境下,虚拟机上两个机器的集群,相互之间出现网络问题的机会,几乎TM没见过。但是生产环境,我们都是独立部署的。不管怎么样,一旦出现网络问题了呢, 那就可能导致 数据的不一致的 问题。即使出现网络的机会可能只是100w分之一,那么如果一个系统的交易额一个是100w,那么就是说,一天出现一次网络问题的概念是1,是100%。
也许你会说,如果真出现了这个问题再来人工处理吧,或许人工处理的成本比程序保证的成本更低呢? 但是,一般来说现在的人工成本是很贵的,而程序员的工作就是要保证程序的稳定,尽量少出故障,出现了数据不一致现象,更加是大忌,难以解释。通常认为软件的成本是很低的,人工或者 硬件的成本是比较高的,虽然写一个软件的成本并不低,但是那个已经是程序员的脑力、能力的话题了。对于能力强的程序员来说,写一个稳定的、高效的、数据一致的程序,并不是什么太难的事。 所以呢,我们需要不断学习。。。
而且,我们的系统有方方面面,要是是不是这里出现数据不一致,那里也出现,那会被骂死。
从上面本地事务来看,我们可以看为两块,一个是service产生多个节点,另一个是resource产生多个节点。
随着互联网快速发展,微服务,SOA等服务架构模式正在被大规模的使用,举个简单的例子,一个公司之内,用户的资产可能分为好多个部分,比如余额,积分,优惠券等等。在公司内部有可能积分功能由一个微服务团队维护,优惠券又是另外的团队维护
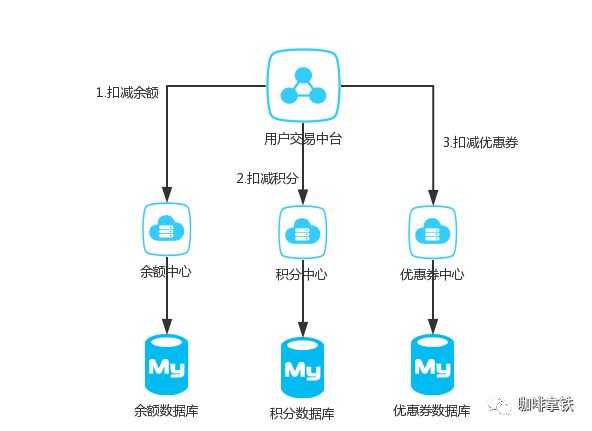
这样的话就无法保证积分扣减了之后,优惠券能否扣减成功。
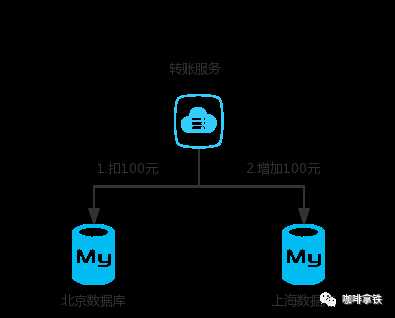
同样的,互联网发展得太快了,我们的Mysql一般来说装千万级的数据就得进行分库分表,对于一个支付宝的转账业务来说,你给的朋友转钱,有可能你的数据库是在北京,而你的朋友的钱是存在上海,所以我们依然无法保证他们能同时成功
本地消息表这个方案最初是ebay提出的 ebay的完整方案https://queue.acm.org/detail.cfm?id=1394128。
此方案的核心是将需要分布式处理的任务通过消息日志的方式来异步执行。消息日志可以存储到本地文本、数据库或消息队列,再通过业务规则自动或人工发起重试。人工重试更多的是应用于支付场景,通过对账系统对事后问题的处理。
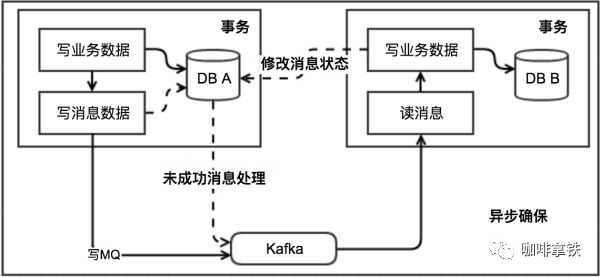
这个图看似已经把所有流程都画出来了,其实不是,很多地方不太确定, 具体的做法也可以各种各样。
当我们 本地消息表实现分布式事务 的最终一致性的时候, 我们其实需要明白 我们首先需要在本地数据库 新建一张本地消息表,然后我们必须还要一个MQ(不一定是mq,但必须是类似的中间件)
消息表怎么创建呢?这个表应该包括这些字段: id, biz_id, biz_type, msg, msg_result, msg_desc,atime,try_count。分别表示uuid,业务id,业务类型,消息内容,消息结果(成功或失败),消息描述,创建时间,重试次数, 其中biz_id,msg_desc字段是可选的。
具体怎么做呢?消息生产方(也就是发起方),需要额外建一个消息表,并记录消息发送状态。消息表和业务数据要在一个事务里提交,也就是说他们要在一个数据库里面。然后消息会经过MQ发送到消息的消费方。如果消息发送失败,会进行重试发送。
消息消费方(也就是发起方的依赖方),需要处理这个消息,并完成自己的业务逻辑。此时如果本地事务处理成功,表明已经处理成功了,如果处理失败,那么就会重试执行。如果是业务上面的失败,可以给生产方发送一个业务补偿消息,通知生产方进行回滚等操作。
生产方和消费方定时扫描本地消息表,把还没处理完成的消息或者失败的消息再发送一遍。如果有靠谱的自动对账补账逻辑,这种方案还是非常实用的。
实现思路:
1.生产方 向MQ来发送消息,消息内容是什么? 消息内容至少是包括了一些跨服务调用的参数。我们需要同步还是异步获取结果呢?一般选择 同步,获取结果r1,调用2;
2.生产方 执行我们的业务,同时向本地消息表新增一行,主要需要记录消息内容,消息结果r1—— 这两个数据库操作必须要在同一个事务内部完成;
3.消费方 监听MQ的某个业务dest,然后,发现消息被生产了,那么就消费之,调用4, 4成功后就算消费成功,然后从mq 删除对应的消息;4如果失败则等待少数时间后重试,4 放入一个循环里面,循环3次,3次失败后发通知,然后人工处理;
4.消费方 开始消费,怎么消费呢? 就是直接执行对应的本地事务逻辑;
(每一个步骤就是一个方法)
—— 这种方案的话,我们的每一个微服务就需要一张本地表,需要编程一些非业务的内容。
正常的操作逻辑就是这样的,但是,这么多步骤,每一步都是可能出现失败的。失败不要紧,我们来看看:
如何保证数据一致性的:
如果1 失败,消息都发送不出去,或者发出去了,但是获取不到结果。两种情况都是个大问题,系统都用不了了,玩不下去了,得赶紧看看原因, 一般这种情况 也不会是程序逻辑错误,很可能网络问题了,比如网关发生变化了,ip 变化了,防火墙啊,或者是mq 本身问题了,比如mq或mq集群都挂掉了。虽然是大问题,但是没有事务发生,自然数据保持一致性。
如果2 失败,表明事务回滚了,数据仍然保持一致。如果程序、业务逻辑正确,这种失败情况不应该出现, 罕见,不过也有可能是 数据库本身挂了,或者数据库 或应用程序 内存啊,容量啊 不够了。
如果3 失败,不涉及数据操作,数据仍然保持一致。这种失败情况不应该出现,一般是后面步骤比如消息处理出错。
如果4 失败,本地数据仍然保持一致,但是整体而言,数据已经不一致了! 那怎么办?那就重试。N次失败后发通知,然后人工处理。
如果消费方 服务挂掉了呢? 那么也不要紧,消息是 未消费状态,消费方服务恢复之后 可以预期达到最终一致性,当然, 恢复之前确实是不一致了!消费方 服务 挂掉这种情况也少见,通常是可能是由于消费方所在的机器挂掉了,或者 消费方服务内存溢出啊等原因, 整个进程异常退出了。这个一般就是运维的责任了。 出现了则需要立即 运维介入,依据 具体原因或者 运维自动化处理,或者人工处理。
消费方的第三、四步的时候,我们也可以这样做:
3.消费方 消费消息,同步调用4,4成功则删除消息,失败则重新消费,然后重复调用4; (需要mq 能够支持重复消费)
4.消费方 怎么处理消息呢? 就是直接 执行对应的本地事务;
或者我们也可以这样做:
3.消费方 消费消息,然后 同步调用4,把4的成功或失败的结果 记录到本地消费消息表,写一条数据; (没有循环)
4.消费方 怎么处理消息呢? 就是直接 执行对应的本地事务;
5.消费方 本地运行定时任务,定时扫描 本地消费消息表,扫描到失败记录,根据失败的具体原因,重新调用4 (怎么调用呢? 可以这样,先把消息解析出来,获取具体的内容(也就是生产方提供的参数),然后获取方法4所在的service单例,然后使用消息内容作为参数 调用4。这里的4,肯定是有参数的,最好service类是单例的,而且不要充血模型);(记录本地消息的时候呢,我们也有多个方案,我们可以把消息的业务类型记录下来,然后根据业务类型找到service类和方法,也可以直接把service类和方法 记录下来。或者记录service类,然后方法作为类型记录下来。)
—— 这种方案的话,我们的每一个微服务就需要两张本地表,一张是本地消费表,也就是本地消息生产表,一个是本地消息消费表,分别记录 生产和消费情况。
上面的3或者我们也可以这样做:
3.消费方 消费消息,然后 先记录到本地消费消息表,重试次数为0,再异步调用4,再删除消息;// 过程如果出错,那么根据情况 可能需要重新消费消息
4.消费方 怎么处理消息呢? 就是直接 执行对应的事务, 同时更新 本地消费消息表的重试次数为1、状态为成功 —— 这两个操作应该放入一个事务内完成
5 消费方 本地的定时器,定时扫描本地消费消息表;发现失败的记录则重试。重试成功则重试次数为2、状态为成功;如果重试失败呢?那么需要改为 重试次数为1、状态为失败,以此类推。如果 重试次数大于3, 那么发邮件或短信通知,然后可能需要人工介入。
消费方 处理消息为什么会失败? 从业务角度来考虑, 可能就是 资源不够了,资源不满足条件了。 像这种情况,我们也可以在前期做一些预处理, 即所谓的“资源预留”,也就是 给资源加锁。 比如 发起者 首先要 同步通知 消费者 先预留资源, ok后才 进行下一步,如发送消息之类的。
具体任务具体分析,我也可以异步校验数据(任务调度来处理),或者消息再推送一次,或者直接删除消息
如果消费方有多个,各个消费方没有依赖顺序,那么它们可以同时去消费,如果有依赖顺序,那么我们需要做一个 调用链, 也就是 消费者也生产消息,消费者也同时是生产者。
总结
分布式高并发环境下,我们需要仔细设计,仔细权衡每个方法调用,是异步还是同步, 是否需要设计成幂等, 是否需要写数据库,是否需要mq,是否需要拆分业务,是否需要多个表,是否需要多个数据库,是否需要这样的业务流程?
每一步都可能出错,要保证稳健的程序,我们需要考虑很多很多,特别需要仔细考虑当前方法是应该自己处理还是抛出,考虑各种问题,要做最全面而且详细的错误处理。
参考:
https://www.cnblogs.com/bigben0123/p/9453830.html
https://segmentfault.com/a/1190000012415698
http://www.cnblogs.com/zhangliwei/p/9984129.html
标签:架构 字段 溢出 技术分享 htm 出错 消息队列 image 分享图片
原文地址:https://www.cnblogs.com/FlyAway2013/p/10124283.html