标签:info cat 存储类别 文件夹 ase 防止 amp 变更 return
先来看一下我们的目录:
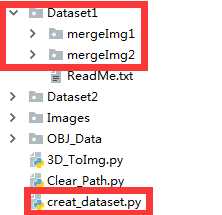
dataset1 和creat_dataset.py 属于同一目录 mergeImg1 和mergeImg2 为Dataset1的两子目录(两类为例子)目录中存储图像等文件
核心文件
creat_dataset.py 文件如下
#来生成训练集和测试集的矩阵 import cv2 as cv import numpy as np import os dataset_path = ["mergeImg1","mergeImg2"] #这里为了增加限制,只读取以下俩个(防止有其他文件夹 干扰) #有效的path def gain_data(path): train_data = [];train_label = [] test_data = [];test_label = [] category = 0 for i in os.listdir(path): #dataset 目录下的两类 if i in dataset_path: #读取指定的文件夹 因为会存在其他文件夹 filepath = os.path.join(path,i) #目录下/子目录 if os.path.isdir(filepath): for file in os.listdir(filepath): #目录下的文件 filename = os.path.join(filepath,file) img = cv.imread(filename) #打开文件 img = cv.resize(img,(160,160)) #将图片进行大小设置 train_data.append(img) train_label.append(category) #存储对应标签 category = category + 1 #存储类别变更 (0 , 1) data = np.array(train_data) label = train_label cv.destroyAllWindows() return data,label #标签转化函数 (0,0,1,1) --> ([1,0],[1,0],[0,1],[0,1]) def label_cov(train_label): result = [] calss_num = len(set(train_label)) label = [0] * calss_num for i in train_label: label[i-1] = 1 result.append(label) label = [0] * calss_num result = np.array(result) return result #将数据x 和标签y 进行随机排列(打乱) 注x和y 应该为矩阵类型 def shuffle_data(x , y): num_example = x.shape[0] arr = np.arange(num_example) np.random.shuffle(arr) data_train = x[arr] label_train = y[arr] return data_train,label_train def gain_data1(path): #对于数据集1 进行获取 train_data,train_label = gain_data(os.path.join(path,"Dataset1")) lab = label_cov(train_label) #标签转换 lab = np.array(lab) train_data, lab = shuffle_data(train_data, lab) #随机打乱 return train_data,lab def gain_data2(path): #对于数据集2 获取 train_data,train_label = gain_data(os.path.join(path,"Dataset2")) lab = label_cov(train_label) #标签转换 keras中不需要 tf需要 lab = np.array(lab) train_data, lab = shuffle_data(train_data, lab) #随机打乱 return train_data,lab a,b= gain_data1("目录") #a,b返回的就是我们需要的数据 可以直接传入神经网络中
如果大家有什么不明白的可以与我交流。 读取数据所使用的函数都十分简单。
深度学习(tensorflow) —— 自己数据集读取opencv
标签:info cat 存储类别 文件夹 ase 防止 amp 变更 return
原文地址:https://www.cnblogs.com/WSX1994/p/10128338.html