标签:sub cap 特征 str font 有一个 The 一个 show
1、Show, Attend and Tell: Neural Image Caption Generation with Visual Attention.Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, Yoshua Bengio ; Proceedings of the 32nd International Conference on Machine Learning, PMLR 37:2048-2057, 2015.
这篇文章中提出了hard attention与soft attention两种注意力机制,二者的通用计算框架相同,区别在于注意力计算方式的不同:
1)通用计算框架
步骤一:
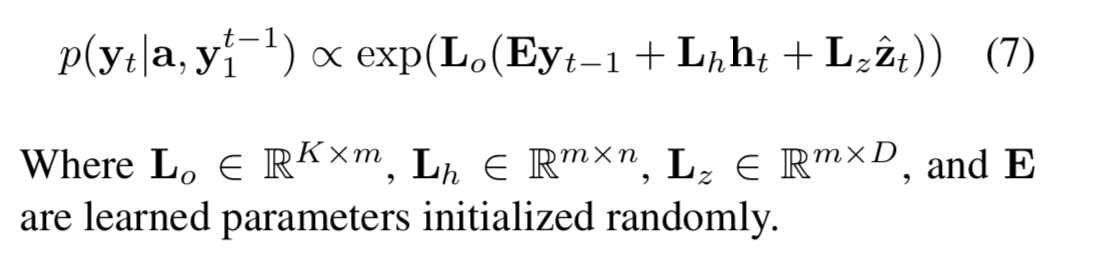
yt-1表示热编码的词向量,ht表示隐藏层,Zt表示(头部有箭头)上下文向量
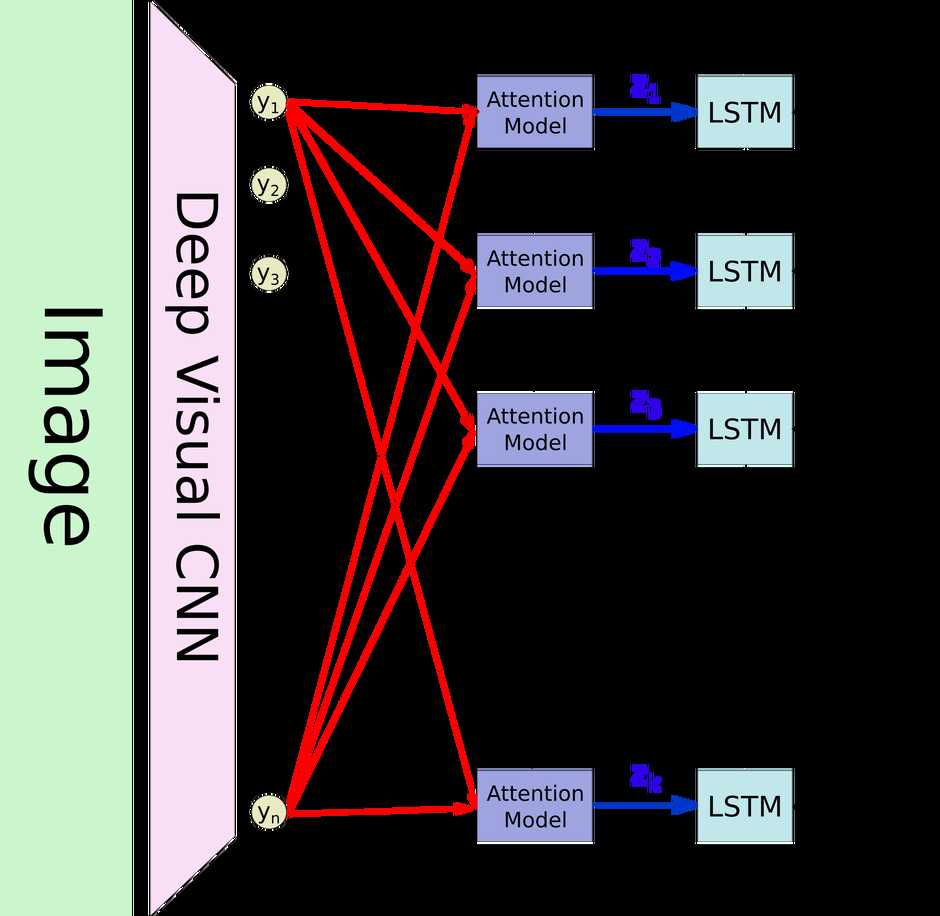

软、硬注意力的主要区别在于φ函数的计算方式的不同,ai表示抽取出的图像特征向量。

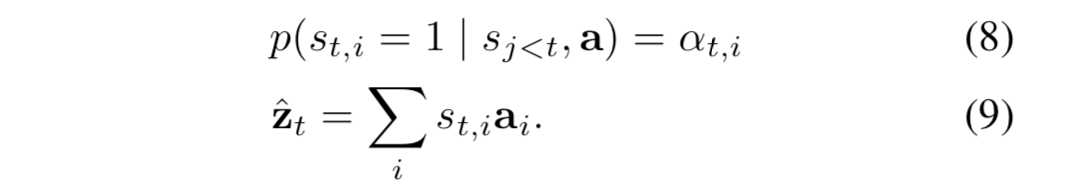
说完“硬”的 attention,再来说说“软”的 attention。 相对来说 soft attention 很好理解,在 hard attention 里面,每个时刻 t 模型的序列 [ St1,…,StL ] 只有一个取 1,其余全部为 0,
也就是说每次只 focus 一个位置,而 soft attention 每次会照顾到全部的位置,只是不同位置的权重不同罢了。这时 Zt 即为 ai 的加权求和:
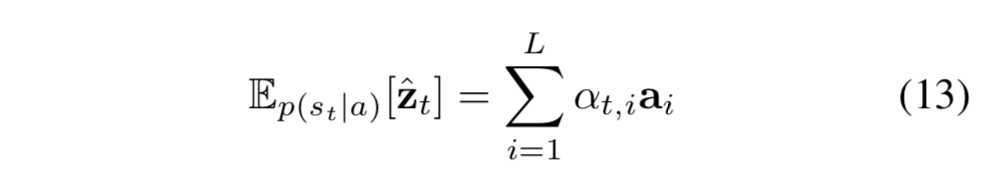
参考:https://blog.csdn.net/u011414416/article/details/51057789
标签:sub cap 特征 str font 有一个 The 一个 show
原文地址:https://www.cnblogs.com/AugusXing/p/10130399.html