标签:脑裂 node jdk zookeeper 出错 单点故障 love image 原理
1.所谓HA,即高可用(high available)
2.消除单点故障,避免集群瘫痪,hdfs中namenode保存了整个集群的元数据,如果namenode所在机器宕机,则整个集群瘫痪,HA
能够即使将备用的namenode替代宕机节点的namenode
3.当机器出现故障,或需要升级等操作时,HA起到了很好的作用
1.硬件需求:
三台主机(网络均能ping通、ssh免密服务)
2.软件需求:
①jdk 我使用的是jdk1.8.0_131
②hadoop 我使用hadoop-2.7.2
③zookeeper 我使用zookeeper-3.4.10
以上软件单独的配置我就不说了,网上有很多安装教程,下面我主要说明搭建HA的一些原理、步骤。
图解:
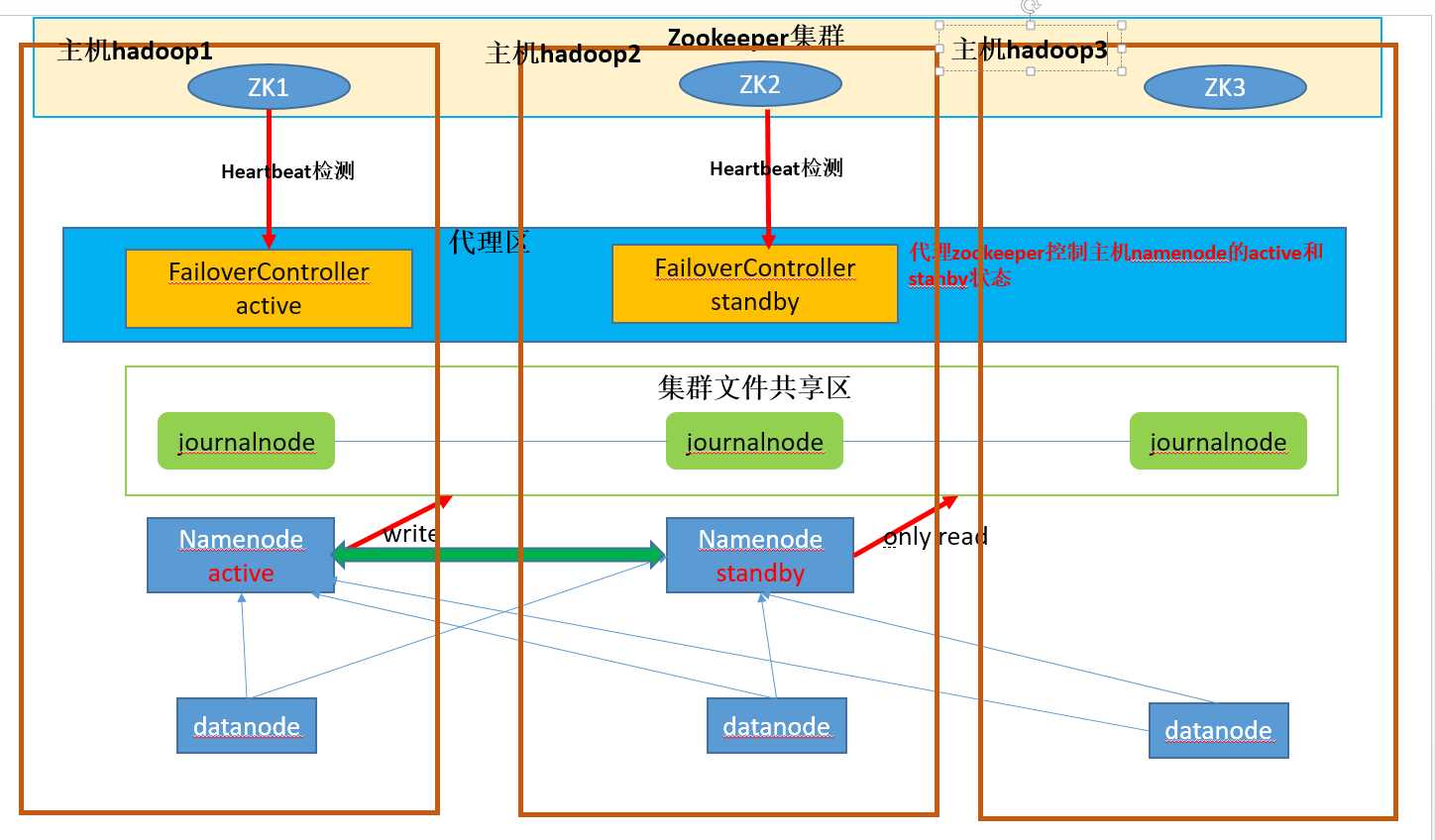
①集群文件共享区主要存放每个处于active的namenode所写的edit-profile文件和fsimage镜像,供其它备份的namenode节点(即standby namenode)
同步,及时更新集群的元数据信息
②代理区的FailoverController有active和standby两种,它们分别控制同一主机上namenode,防止脑裂现象(brain split)
如:当主机hadoop1和主机hadoop2网络连接异常时,原本hadoop1上的namenode为active,它并没有宕机,而主机hadoop2认为它宕机了,FailoverControlle
stanby 准备将自己主机上的namenode提升为active状态
为了防止脑裂现象,FailoverController stanby会先发送请求给FailoverController active去将它控制的namenode改变为stanby状态,之后hadoop2的namenode
才能为active状态
③JournalNode的作用:两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信。当active状态的NameNode的命名空间有任何修改时,
会告知大部分的JournalNodes进程。standby状态的NameNode有能力读取JNS中的变更信息,并且一直监控edit log的变化,把变化应用于自己的命名空间。
standby可以确保在集群出错时,命名空间状态已经完全同步了。
④zookeeper投票选举:zookeeper集群通过心跳检测,监视着集群中各个节点的健康状态,如果发现有节点下线,将自动删除该节点在zookeeper中的信息,进行重新
投票选举。
选举制度
标签:脑裂 node jdk zookeeper 出错 单点故障 love image 原理
原文地址:https://www.cnblogs.com/jim0816/p/10137066.html