标签:log 用户线程 阶段 http epo jdk 初始 没有 速度
前一篇讲了垃圾收集算法--JVM之GC算法、垃圾收集算法——标记-清除算法、复制算法、标记-整理算法、分代收集算法,如果把它看作是方法论,那么下面说的就应该是内存回收的具体实现。
先看一下JVM中有哪些垃圾收集器,如下图所示:
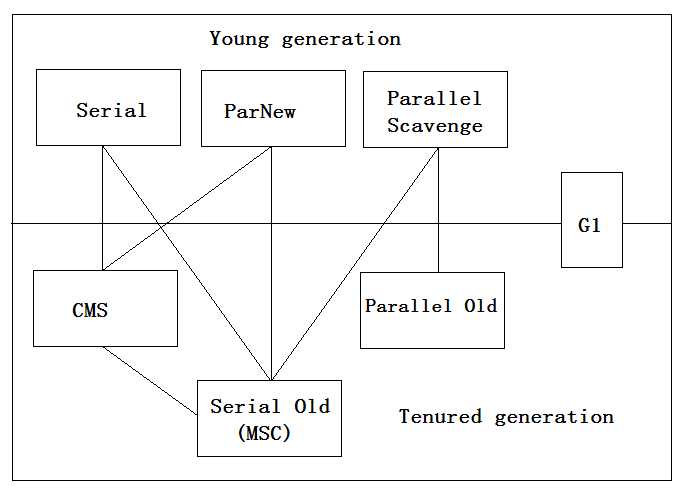
上图一共展示了七种作用于不同分代的垃圾收集器,如果两个收集器之间存在连线,就说明它们可以搭配使用。
1、Serial 收集器
JDK1.3之前作为新生代收集器的唯一选择。它是单线程收集器,这里的单线程不仅仅说明它只会使用一个CPU和一条收集线程去完成垃圾收集工作,
更重要的是在它进行垃圾收集时,必须暂停其他所有工作线程,直到它收集结束。此种现象称之为“Stop The World”,通俗点讲就是“妈妈在打扫房间
的时候,孩子只能等待,不能乱扔垃圾”。
Serial/Serial Old收集器运行示意图如下:
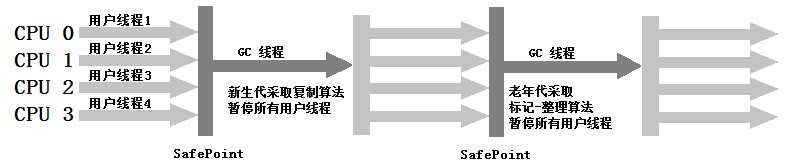
当然,Serial收集器也有其优点:简单而高效(与其他收集器的单线程比),对于限定单个CPU的环境来说,Serial收集器由于没有线程交互的开销,
专心做垃圾收集自然可以获得最高的单线程收集效率。所以,Serial收集器对于运行在Client模式下的虚拟机来说是一个很好的选择。
2、ParNew 收集器
ParNew收集器其实就是Serial收集器的多线程版本,除了使用多线程进行垃圾收集之外,其余行为(Serial收集器可用的所有控制参数、收集算法、
Stop The World、对象分配规则、回收策略等)都与Serial收集器完全一样。
ParNew收集器运行示意图如下:
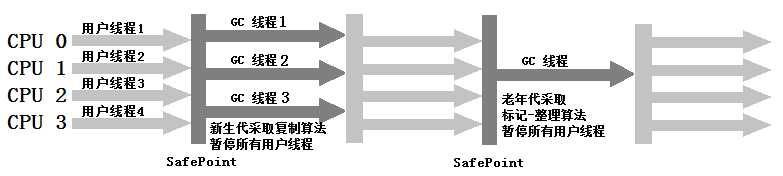
除了Serial收集器,目前只有ParNew收集器可以和CMS收集器配合工作。CMS收集器是并发收集器,可以让垃圾收集线程和用户线程(基本上)
同时工作,用前面的例子,就是说,“妈妈在打扫房间的时候,孩子可以扔垃圾”。
3、Parallel Scavenge收集器
使用的是复制算法,又是并行的多线程收集器。其特点是,关注点和其他收集器不同,CMS等收集器的关注点是尽可能的缩短垃圾收集时用户线程
的停顿时间,而Parallel Scavenge收集器的目标则是达到一个可控制的吞吐量。吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间),
虚拟机总共运行100分钟,其中垃圾收集花掉了1分钟,那吞吐量就是99%。
Parallel Scavenge收集器也经常称为“吞吐量优先”收集器,通过参数:-XX:MaxGCPauseMillis(设置最大垃圾收集停顿时间)、-XX:GCTimeRatio(设置吞吐量大小)
可以精确控制吞吐量。另外还有一个参数:-XX:+UseAdaptiveSizePolicy,这是一个开关参数,当这个参数打开后,就不需要手工指定新生代的大小(-Xmn)、Eden
与Survivor区的比例(-XX:SurvivorRatio)、晋升老年代对象大小(-XX:PretenureSizeThreshold)等细节参数了,虚拟机会根据当前系统的运行情况收集性能监控信
息,动态调整这些参数以提供最合适的停顿时间或者最大的吞吐量,这种调节方式称为GC自适应的调节策略(GC Ergonomics)。
4、Serial Old收集器
是Serial收集器的老年代版本,是单线程收集器,使用“标记-整理算法”。
Serial Old收集器运行示意图如下:
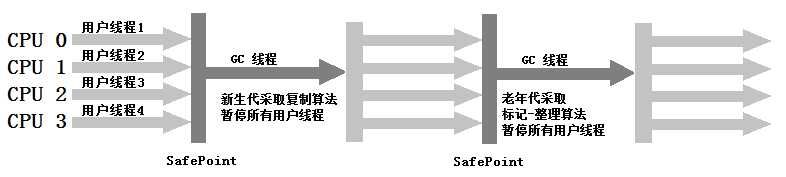
5、Parallel Old收集器
是Parallel Scavenge收集器的老年代版本,使用多线程和“标记-整理”算法。在注重吞吐量以及CPU资源敏感的场合,都可以优先考虑Parallel Scavenge加Parallel Old收集器。
Parallel Old收集器运行示意图如下:
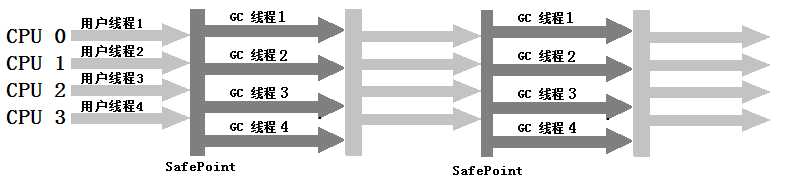
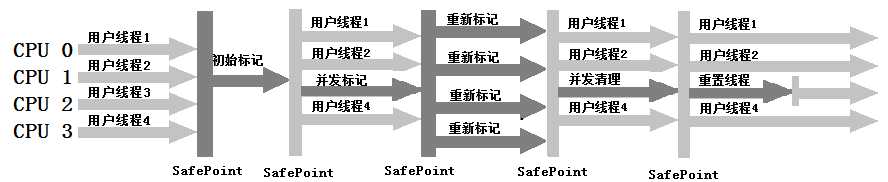
6、CMS收集器
CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。使用的是“标记-清除”算法。
在运行过程分为四个步骤:
整个过程中并发标记和并发清除线程都可以与用户线程一起工作,所以从总体上来说,CMS收集器的内存回收过程与用户线程是一起并发执行的。
CMS收集器运行示意图如下:
优点:并发收集、低停顿、
-XX:+UseCMSCompactAtFullCollection开关参数,用于在CMS收集器顶不住要进行FullGC时开启内存碎片的合并整理过程,内存
整理的过程是无法冰法的,空间碎片问题没有了,但停顿时间不得不变长。
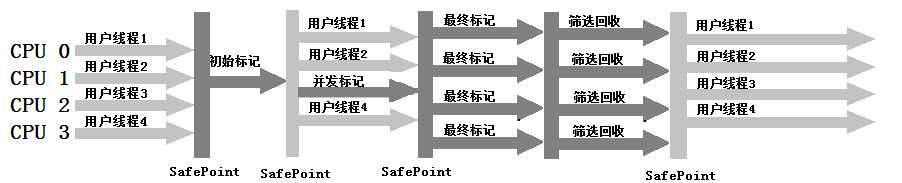
7、G1收集器
是一款面向服务端应用的垃圾收集器。运行过程分为如下几个步骤:
G1收集器运行示意图如下:
标签:log 用户线程 阶段 http epo jdk 初始 没有 速度
原文地址:https://www.cnblogs.com/java-spring/p/10138132.html