标签:发展 方式 结束 失效 ref 有一个 转换 https 灰色
上个月参加了一个云存储的技术讨论会。这一个月里,陆续收到几位同学讨论大数据保存和处理的邮件。今天是周末,索性把这个月的交流内容整理写下来,供各位参考。
目前大数据存储有两种方案可供选择:行存储和列存储。业界对两种存储方案有很多争持,集中焦点是: 谁能够更有效地处理海量数据,且兼顾安全、可靠、完整性。从目前发展情况看,关系数据库已经不适应这种巨大的存储量和计算要求,基本是淘汰出局。在已知的几种大数据处理软件中,Hadoop 的 HBase 采用列存储,MongoDB 是文档型的行存储,Lexst 是二进制型的行存储。在这里,我不讨论这些软件的技术和优缺点,只围绕机械磁盘的物理特质,分析行存储和列存储的存储特点,以及由此产生的一些问题和解决办法。
行存储数据排列
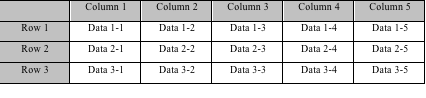
列存储数据排列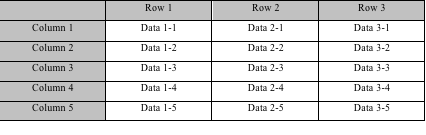
表格的灰色背景部分表示行列结构,白色背景部分表示数据的物理分布,两种存储的数据都是从上至下,从左向右的排列。行是列的组合,行存储以一行记录为单位,列存储以列数据集合单位,或称列族(column family)。行存储的读写过程是一致的,都是从第一列开始,到最后一列结束。列存储的读取是列数据集中的一段或者全部数据,写入时,一行记录被拆分为多列,每一列数据追加到对应列的末尾处。
从上面表格可以看出,行存储的写入是一次完成。如果这种写入建立在操作系统的文件系统上,可以保证写入过程的成功或者失败,数据的完整性因此可以确定。列存储由于需要把一行记录拆分成单列保存,写入次数明显比行存储多,再加上磁头需要在盘片上移动和定位花费的时间,实际时间消耗会更大。所以,行存储在写入上占有很大的优势。
还有数据修改, 这实际也是一次写入过程。不同的是,数据修改是对磁盘上的记录做删除标记。行存储是在指定位置写入一次,列存储是将磁盘定位到多个列上分别写入,这个过程仍是行存储的列数倍。所以,数据修改也是以行存储占优。 数据读取时,行存储通常将一行数据完全读出,如果只需要其中几列数据的情况,就会存在冗余列,出于缩短处理时间的考量,消除冗余列的过程通常是在内存中进行的。列存储每次读取的数据是集合的一段或者全部,如果读取多列时,就需要移动磁头,再次定位到下一列的位置继续读取。 再谈两种存储的数据分布。由于列存储的每一列数据类型是同质的,不存在二义性问题。比如说某列数据类型为整型(int),那么它的数据集合一定是整型数据。这种情况使数据解析变得十分容易。相比之下,行存储则要复杂得多,因为在一行记录中保存了多种类型的数据,数据解析需要在多种数据类型之间频繁转换,这个操作很消耗 CPU,增加了解析的时间。所以,列存储的解析过程更有利于分析大数据。
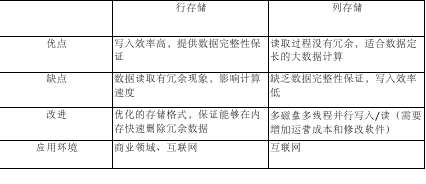
显而易见,两种存储格式都有各自的优缺点:行存储的写入是一次性完成,消耗的时间比列存储少,并且能够保证数据的完整性,缺点是数据读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略;数量大可能会影响到数据的处理效率。列存储在写入效率、保证数据完整性上都不如行存储,它的优势是在读取过程,不会产生冗余数据,这对数据完整性要求不高的大数据处理领域,比如互联网,犹为重要。
改进集中在两方面:行存储读取过程中避免产生冗余数据,列存储提高读写效率。
如何改进它们的缺点,并保证优点呢?
行存储的改进:减少冗余数据首先是用户在定义数据时避免冗余列的产生;其次是优化数据存储记录结构,保证从磁盘读出的数据进入内存后,能够被快速分解,消除冗余列。要知道,目前市场上即使最低端 CPU 和内存的速度也比机械磁盘快上 100-1000 倍。如果用上高端的硬件配置,这个处理过程还要更快。
列存储的两点改进:1. 在计算机上安装多块硬盘,以多线程并行的方式读写它们。多块硬盘并行工作可以减少磁盘读写竞用,这种方式对提高处理效率优势十分明显。缺点是需要更多的硬盘,这会增加投入成本,在大规模数据处理应用中是不小的数目,运营商需要认真考虑这个问题。2. 对写过程中的数据完整性问题,可考虑在写入过程中加入类似关系数据库的“回滚”机制,当某一列发生写入失败时,此前写入的数据全部失效,同时加入散列码校验,进一步保证数据完整性。
这两种存储方案还有一个共同改进的地方:频繁的小量的数据写入对磁盘影响很大,更好的解决办法是将数据在内存中暂时保存并整理,达到一定数量后,一次性写入磁盘,这样消耗时间更少一些。目前机械磁盘的写入速度在 20M-50M/ 秒之间,能够以批量的方式写入磁盘,效果也是不错的。
两种存储格式各自的特性都决定了它们不可能是完美的解决方案。 如果首要考虑是数据的完整性和可靠性,那么行存储是不二选择,列存储只有在增加磁盘并改进软件设计后才能接近这样的目标。如果以保存数据为主,行存储的写入性能比列存储高很多。在需要频繁读取单列集合数据的应用中,列存储是最合适的。如果每次读取多列,两个方案可酌情选择:采用行存储时,设计中应考虑减少或避免冗余列;若采用列存储方案,为保证读写入效率,每列数据尽可能分别保存到不同的磁盘上,多个线程并行读写各自的数据,这样避免了磁盘竞用的同时也提高了处理效率。 无论选择哪种方案,将同内容数据聚凑在一起都是必须的,这是减少磁头在磁盘上的移动,提高数据读取时间的有效办法。
Reference:
https://www.infoq.cn/article/bigdata-store-choose 大数据存取的选择:行存储还是列存储
标签:发展 方式 结束 失效 ref 有一个 转换 https 灰色
原文地址:https://www.cnblogs.com/piperck/p/10142124.html