标签:调用 服务 无法 上层 big 1.2 接口 论文 入门
2018-12-13
2018-12-20
在了解HBase之前,非常有必要先了解一下最基础的概念,毕竟了解概念是学习的第一步,也是必不可少的一步。
首先我们以哲学史上三个终极问题来向HBase say hello.
1、我是谁?
2、我从哪里来?
3、我要到哪里去?
* HBase是什么(我是谁)?
HBase是Apache公司根据Google发表的几篇关于如何处理海量数据的论文(GFS, MapReduce, BigTable)中的思想而创立的一个开源项目。一句话:HBase是一个用于存储海量数据的分布式数据库软件。这里涉及到一个概念不得不提,何谓“海量数据”?个人对海量数据的定义有两点:1. 数据本身足够大。TB及以上级别的数据量; 2. 数据增长速度足够快。每天以几十上百GB的速度在增长。
* 为什么需要HBase(我从哪里来)?
我们都知道,能量是不可能凭空产生的。HBase如是,它并不是有一群人吃饱了没事做要弄个HBase出来玩玩。一件新事物的诞生,必然是出于人们对旧有事物的不满足。在HBase诞生之前,人们使用的数据库软件都是面向“行”存储的。什么是面向行存储呢?我们都知道,数据库存储数据最终还是要以文件的形式保存到硬盘中的。一般来说,文件在硬盘中都是物理连续地保存起来的(机械盘,有土豪用固态盘作数据存储?),而面向行存储呢,就是表中的每一行的所有数据都是连续地存储起来的。如下图所示:

图1 传统数据库的存储方式
* 该如何学习HBase(我要到哪里去)?
接下来再谈谈软件环境咯。有的人可能要说了,上面谈硬件设备的时候不是已经说了要win10,要虚拟机了吗,那个不是软件环境吗! 好像是这么个理,但是,其实,它。。。不要在意这些细节啦,往下看咯。
HBase的分布式能力完全是仰仗于Hadoop这头小神象的(Hadoop的LOGO就是一只欢快的小象象,如下图2所示)。假如你了解了Hadoop以后再去学习HBase,你会有一种HBase就是把Hadoop的各种概念再用他自己的话“复述”一遍而已的感觉。

图2 Hadoop LOGO
然后还有一个Zookeeper,
因此,有条件的老铁,在学习HBase之前,可以先去了解一下Hadoop和Zookeeper。如果不想自己学习HBase的一腔热血被强行中途打断而去学习其它东东,也可以不去了解它们而直接学习HBase。因为我在后面也会讲一下Hadoop和Zookeeper的一些相关概念的。
如果你能坚持看到这里,那么我要开始刮一次目再来和你相看了,因为我已经开始有点相信你不是一时头脑发热而想去学习什么鬼HBase的了。那话又说回来,既然看到了这里,说明你在HBase上的哲学史三大终极问题都已经捋清楚了,对“自我”有一个基本的认识以后,就开始要稍微深入一点了。先来看看HBase的技术架构吧。
HBase的架构对于小白同学来讲还是很复杂的。刚刚我才说到,干嘛好学不学学什么鬼HBase嘛,它真的超级多概念的,刚开始学的时候,光是记这些概念就能让你



 。不过其实也没有这么严重了,因为。。。现在放弃还来得及!!!
。不过其实也没有这么严重了,因为。。。现在放弃还来得及!!! 。
。
言归正传了,要看HBase的架构,直接抓取网上的一幅架构图来讲解吧:
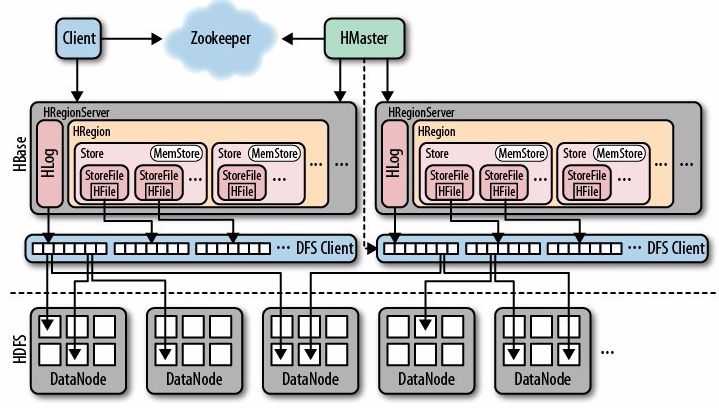
图3 HBase架构
整个HBase系统是基于HDFS构建的。这个怎么理解呢,呃,就像小米手机的 MIUI是基于Android原生系统构建的,锤子手机的smartisan os也是基于Android原生系统构建的一样。一些很繁琐很基础的事情先由Android原生系统帮你搞定了,你再把你的精力专注于构建你自己的应用生态圈去那样。HBase系统也是这样。HDFS的全称是Hadoop distributed file system,分布式的能力HDFS已经做的很优秀了,你HBase直接拿过来,专注于上层应用开发,整个项目就会简单的多了。
真正属于HBase的东西只有两样:1、HMaster; 2、 HRegionServer。 HMaster是用来作决策的。HRegionServer是用来存储数据的。
Zookeeper也是一个第三方的程序。它是用来解决HBase系统中服务协同问题的。
Client端其实就是HBase开放出来的给程序员们调用的各种API。当然你也可以把它理解成是在屏幕前操纵的人。
关于HBase架构图更详细一点的介绍,本篇博文限于篇幅就不再赘述,有兴趣的同学可以参考一下另一篇博文: HBase轻松入门之HBase架构图解析 。
暂时不更。
暂时不更。
暂时不更。
标签:调用 服务 无法 上层 big 1.2 接口 论文 入门
原文地址:https://www.cnblogs.com/chorm590/p/10114987.html