标签:\n out text 编码转换 部分 软件 内容 数字 存储位置
目录
上面说了很多了,那么真正的开始篇幅讲解.
C++中整数的基本数据类型有三种, int long short. 在 VC6.0中,int long所占内存都是4字节.
short两个字节. 以16进制为例 int long 分别就是4个字节. short两个字节. 一个字节是8位.
在内存中,无符号整数是用来表示数值的.如果32位下.那么取值范围是 0x00000000~0xFFFFFFF
10进制: 0~4294967295,因为无符号数,那么最高位就是0填充.所以表示数值比较大.
有符号整数跟上面无符号整数一样.只不过高位用来表示符号位,其余低位表示数值.这样有符号的整数.表示的数值就只有31位了.范围则是 0x80000000~0x7FFFFFFF 转为十进制: -2147483648~ 2147483647
因为最高位是符号位,可以表示 负数. 例如 -3
在内存中负数都是补码形式表示的
补码规则: 补码规则则是用0 - 去这个数的绝对值
例如: 0 - 3 的结果就是 -3在内存中的表现形式.
因为补码高位为1,要转为真值也是 0 - 补码的形式. 但是一般计算机计算的话,通常都是用补码取反+1进行获得真值. 前边带上符号即可.
为什么负数取值总比整数取值多一个值.
例如如上:
-2147483648~2147483647
原因:
对于四个字节补码 0x80000000 代表的是-0. 但是对于0来讲. 正负区分没必要.所以0x800000000规定了就是4字节补码最小值了.所以这也是负数比正数多一位的原因.
关于浮点数存储.科学上有很多争议.有很多存储实数(小数)的方式.不过很少用了.所以我们也不再介绍了
现在是不管如何存储.都分为 定点实数存储 跟 浮点数实数存储 这两种方式
值得注意 浮点数转为整数,并不是四舍五入.而是向0取整. 也就是说舍弃小数位.转为整数.
例如: a = 3.78; int b = (int) a; 此时b的值是3. 而不是传统意义上的 4; 因为不是四舍五入.
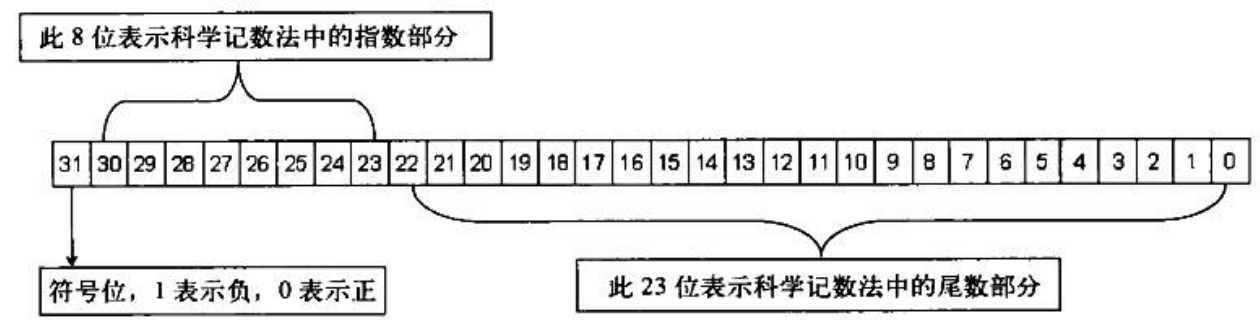
最高位是符号位,表示正负
去掉符号位往后数8位 是指数域.
最后的23位则表示尾数.
2.浮点数转为16进制存储
现在我们要把浮点数转为十六进制存储在内存里.转换步骤
1.将一个浮点数转化为二进制
例如:12.25 转为2进制 = 1100.01
整数直接转为二进制即可. 小数不断 * 2 取整.
例如: 0.25
0.25 * 2 = 0.5 取整 = 0
0.5 * 2 = 1.0 取整就是1
所有12.25 转为二进制表示就是 1100.01
2.计算指数位
计算指数位首先移动小数点位置到符号位置除最高位为1的地方.
也就是符号位也好.不是符号位也好.移动到最高位为1的地方. 7.25 转换之后是
0111.01 移动到最高位则是 1.1101.
1100.01 移动 1.10001 总共移动了3位.每次移动一位,指数+1
因为指数为移动了三位.所以 3 + 127(8位) = 130 转为二进制 10000010 这个就是指数位.
也就是上图中所说的符号位后面数8位是指数位. 我们上边计算的就是指数位的值.
为什么 +127.因为可能会出现负数.十进制127可以表示二进制的01111111. IEEE浮点编码规定
当指数域< 0111111的时候,就是一个负数.如果大于01111111的时候就是一个正数. 所以01111111为0. IEEE浮点编码规定的.所以只要记住即可. 127即可. 也可以理解为指数域是8位,表示的数值是128.但IEE规定了.所以-1 指数最大值 - 1即可.
3.计算尾数位
经过上面计算我们符号是1,但是符号位基本不变.因为是正数浮点.所以符号位为0:
指数位为: 130 10000010
现在计算尾数位. 尾数位就是我们移动小数点之后的数值
1.10001 尾数位就是 10001,但是他不组23位.所以我们补0填充.
1000 1000 0000 0000 0000 000 补0之后,我们需要从左到右,按照4个字节分开
100 0100 0000 0000 0000 0000 分开之后.
此时加上我们之前的符号位以及指数位
0100 0001 0100 0100 0000 0000 0000 0000 这是拼接好的.我们转换为16进制进行存储
0x41440000 那么在内存中,我们的浮点数12.25 其实就是16进制 0x41 44 00 00 进行存储的.
负数跟上边一样.一样计算指数位.也是分为以下步骤
1.转为科学计数法.
2.移动指数位.
3.计算指数位
4.尾数位补零到23位.
5.拼接进行二进制,并且二进制转为16进制.
1.转为科学计数法
-0.125 = 0.001
2.移动指数位
此时移动指数位是往小数点右边移动,移动到最高位为1的地方.
0.001 =>1.0 移动了三位,计算 -3. 往右边移动就是负数
1.0 则符号位是1代表负数. 指数位是负数.
3.计算指数位.
上面我们计算指数位是往小数点左边移动.所以指数位去相加.现在是往右边移动.所以相减
127-3 = 124 转为二进制 = 01111100
4.尾数位补零
0000 0000 0000 0000 0000 000
5.符号位 指数位 尾数位 进行拼接
1011 1110 0000 0000 0000 0000 0000 0000 (总共32位)
转为16进制
0xBE00 0000
所以-0.125 在内存中的16进制则是 0xBE000000
我们会转换为16进制那么也要回转换回来
1.16进制拆分为2进制.
2.分出符号位 指数位 尾数位
3.求指数位是负数还是整数
4.移动指数位
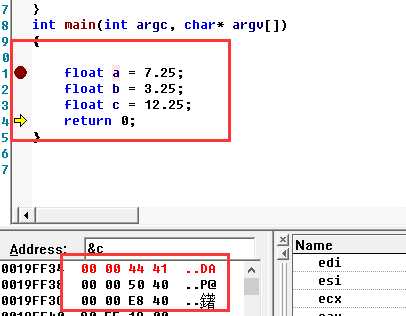
比如我们的12.25f. 十六进制是x41440000
1.16进制转为2进制
0100 0001 0100 0100 0000 0000 0000 0000
2.分出符号位 指数位 尾数位
0 10000010 10001000000000000000000
3.求出指数位
指数位位 10000010 > 01111111 所以可以判断我们的小数是正数
10000010 - 01111111 = 130 - 127 = 3;
得出了我们要移动的位数
4.移动指数位
首先计算出的指数转为2进制 3 = 0011;
然后反过来.尾数位右移动三位.如下.
100010 >> 3 = 100.010 尾数的最高位不需要.所以补零
然后加上符号位.
符号位为0.代表是正数.所以+1
1100.010
再举个例子
7.25 在内存的16进制为0x40E8
1.16进制转为二进制
0100 0000 1110 1000 0000 0000 .....
2.计算指数位,尾数需要往右移动纪委
10000001 - 01111111 = 129 - 127 = 2;得出移动2位
3.移动尾数位
因为高位为0,所以代表我们转换的浮点数是正数.最后我们的高位要加上1才可以.
11010 ==>2位 = 11.010
符号位为0.所以高位补1
111.01 这个二进制在转换为10进制得出7.25
小数转为10进制:
.01是是两位. 分别记位 2的-1次方 2-2次方.
第一位计算: 0 * 1/2-1次方.
第二位计算: 1 * 1/2-2次方即可.
最后结果相加.
如果有三位.那么就是 用第三位数值 * 1/2-3次方即可.
01/2 + 1 1/4 = 0.25.所以我们可以推算出是0.25
double类型转换跟float一样.只不过指数位变成了11位. 剩余的42位表示尾数位.
2~11次方 - 1;就是用于计算的指数.也就是 1023.
因为有了浮点协处理器.所以浮点指令的操作有点不同.它是通过浮点寄存器来实现的.
浮点寄存器是通过栈结构来实现的.也称作浮点栈. 由 st(0) - st(7); 其中写st默认就是st(0)
操作任意浮点栈就需要加上序号 st(7);
值得注意的是浮点栈是循环栈. 也就是说st(0)出栈的数据.会放到st(7)中.这样依次使用.
针对协处理器.也提供的相应的汇编进行操作.
分别是 fld类指令 fst 指令. 以及 fcom fadd等指令
都是大写
出栈指令
FST OUT 将浮点栈顶(st(0))的值给OUT存储. out可以是 mem32/64,但是不出栈
FSTP OUT 同FST out保存值,但是会出栈.
FISTP OUT 出栈,并且以整数的形式给OUT存储.
浮点加法
FADD IN 将St(0)的数据于in做加法. 值保存在 栈顶st(0);中.
FADDP st(N),st 将st(n)栈中的数据于st(0)中的数据进行运算.浮点栈有7个.那么N的取值就是0~7;
先执行一次出栈冬枣.然后相加结果放在 st(0)中存储.
int main(int argc, char* argv[])
{
float a = 11.25;
float c = 12.35;
float d = 13.25f;
float b = 0.0f;
__asm{
fld dword ptr[ebp - 0x4];
fld dword ptr[ebp - 0x8];
fld dword ptr[ebp - 0xc];
faddp st(1),st(0)
fstp dword ptr[ebp - 0x10];
}
printf("%f \r\n",b);
return 0;
}
实现结果:
float GetFloatValue()
{
return 12.25f;
}
int main(int argc, char* argv[])
{
int value = GetFloatValue();
return 0;
}
观看汇编,汇编分为两层.一层是调用内.一层是调用外.
调用内: 也就是GetFloatValue()函数内部.
push ebp
mov ebp,esp
sub esp,40h
push ebx
push esi
push edi
lea edi,[ebp-40h]
mov ecx,10h
mov eax,0CCCCCCCCh
rep stos dword ptr [edi]
fld dword ptr [__real@4@4002c400000000000000 (00423fd0)]主要看最后一样. fld 内存的值. 其实就是把我们的浮点数转为IEE编码.放到内存中.
其实就是放到内存中.
外层调用: 就是调用完毕之后.
0040EB1D call __ftol (004010ec)
0040EB22 mov dword ptr [ebp-4],eax
调用完毕之后,会使用 _ftol. 浮点数转为整数进行转化.下面的返回值放到我们的局部变量中
所以以后看到这样操作.我们就要明白. 返回值是float或者double类型.进行了转换.
_ftol内部
004010EC push ebp
004010ED mov ebp,esp
004010EF add esp,0F4h
;浮点异常检查
004010F2 wait
004010F3 fnstcw word ptr [ebp-2]
004010F6 wait
004010F7 mov ax,word ptr [ebp-2]
004010FB or ah,0Ch
004010FE mov word ptr [ebp-4],ax
00401102 fldcw word ptr [ebp-4]
;从str(0)中取出八个字节放到局部变量 ebp -och中. 所以后面是qword ptr代表8个字节.
;将st(0);从栈中弹出.
00401105 fistp qword ptr [ebp-0Ch]
00401108 fldcw word ptr [ebp-2]
;下方 eax edx同用,eax保存4字节的整数部分. edx则保存小数部分.
0040110B mov eax,dword ptr [ebp-0Ch]
0040110E mov edx,dword ptr [ebp-8]
平展返回.
00401111 leave
00401112 ret内部则是进行浮点转化.比较等等.
布尔类型就是0 跟 1 表示.在内存中就是这样的表示形式. 0就是 false 1就是true
int main(int argc, char* argv[])
{
int a = 10;
int &nType = a;
printf("Value = %d\r\n",nType);
system("pause");
return 0;
}
对应汇编代码
.text:00401158 mov [ebp+var_4], 0Ah
.text:0040115F lea eax, [ebp+var_4]
.text:00401162 mov [ebp+var_8], eax
.text:00401165 mov ecx, [ebp+var_8]
.text:00401168 mov edx, [ecx]
.text:0040116A push edx
.text:0040116B push offset aValueD ; "Value = %d\r\n"
.text:00401170 call _printf可以看到引用其实就是隐藏了细节.
1.赋值变量为10
2.获得这个变量的地址
3.变量地址给引用保存(ntype)
4.获取引用变量地址.
5.从地址取值给edx
6.下方进行打印.
跟指针一样.指针也是保存地址.只不过引用就是对外隐藏了细节.
指针跟引用一样,产生的汇编代码也是一样的.不过使用的时候我们可以直接传引用进行打印.而使用指针
需要加上符号. 例如 printf(nType,type); 前边是引用,后边是指针取值. 两种取值方式不同.
****引用****
在C++中,创建引用 TYPE & a = szBuffer; 创建引用的时候必须给变量给初始化.
本质就是一个变量的别名.在内存中其实就是对地址 取内容的操作.
关于指针.我们说过有不同的表达形式. 例如 BYTE * short ...
因为指针有不同的表达形式.所以自增自减都会产生偏移计算.
例如:
mov eax,byte ptr[ebp - 0xc];
mov ebx,byte ptr[ebp - 0xb];
mov ecx,byte ptr[ebp - 0xa];
....
所以我们可以总结一条寻址公式
目的地址 = 首地址 + sizeof(type) n的值.
目的地址就是我们要进行寻址目的.
sizeof(type) 就是你的数据类型大小
n的值就是你的偏移量.
例如一个数组:
char szBuf[10] = {1,2...7,8,9,10};
我们想要得到下标为8的位置的的值怎么获得.
高级代码: int a = szbuf[8];完了.
因为有公式,我们可以不用这样写.
写成如下:
目的地址 = 首地址 + sizeof(type) *n; 套公式
szbuffer = szbuffer + sizeof(char) * 8;
此时szBuffer的地址就是指向数组下表为8的位置.我们对其取内容即可获取其值.
int main(int argc, char* argv[])
{
char szBuf[10] = {1,2,3,4,5,6,7,8,9,10};
char *dst = szBuf + sizeof(char) * 8;
printf("Value = %d\r\n",*dst);
system("pause");
return 0;
}
逆向工作者看完本博客,应该思考一下如何逆向. 归根结底,计算机就是输入 - 处理 - 输出的过程
学完各种数据类型表达形式.以及转换等等.
那么在逆向的第一步,就是对于内存中的数据.做一个简单的猜想.
1.首先确定数据的处理存储位置
2.确定位置.得到内存中的值,要确定内存属性
3.内存的属性有 可读 可写 可执行. 基于这个,我们可以知道内存是否是变量.
可读写(常量) 可读可执行(代码)
4.确定内存布局. 一般栈所占的内存跟代码区是不一样的. 堆也是.这是经验总结.可以多看看内存得出结论.
举一个例子,比如数字0x12 34 56 78在内存中的表示形式。
5.熟悉内存中存储数据的大端模式小端模式
大端模式: 低地址放数据的高位.高地址方数据的低位
小端模式: 低地址放低位,高地址放高位.
低地址 --------------------> 高地址
0x12 | 0x34 | 0x56 | 0x78
2)小端模式:Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
低地址 --------------------> 高地址
0x78 | 0x56 | 0x34 | 0x12
标签:\n out text 编码转换 部分 软件 内容 数字 存储位置
原文地址:https://www.cnblogs.com/iBinary/p/10150485.html