标签:hadoop .com red 交互 https 图片 centos6.8 export 服务器
一、Spark概述
Spark 是一个用来实现快速而通用的集群计算的平台。
在速度方面,Spark 扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。 在处理大规模数据集时,速度是非常重要的。速度快就意味着我们可以进行交互式的数据操作,否则我们每次操作就需要等待数分钟甚至数小时。
Spark 的一个主要特点就是能够在内存中进行计算,因而更快。不过即使是必须在磁盘上进行的复杂计算,Spark 依然比 MapReduce 更加高效。
Spark 5个核心库
1.内核: spark 的核心基础设施,提供了表示和存储数据的原始数据类型,称为 RDD(Resilient Distributed Dataset, 弹性分布式数据集)
2.SQL
3. MLlib(Machine Learning Library, 机器学习库)
4. GraphX: 供图和图相关的计算使用
5.流(Streaming)
二、安装步骤
1. 安装JDK环境
下载JDK安装包,配置JDK环境

2.安装SCALA
1).下载scala,我这里下载的是scala-2.12.2.tgz,并上传到linux服务器
2).新建scala目录:/usr/local/scala
3).将scala-2.12.2.tgz复制到:/usr/local/scala,并解压缩
4).在/etc/profile文件中添加:
SCALA_HOME=/usr/local/scala/scala-2.12.2
PATH=$PATH:${SCALA_HOME}/bin
5).输入source /etc/profile 使profile文件生效
6).输入scala,查看scala是否生效 
3.安装Spark
1).下载Spark,我这里下载的是spark-2.3.1-bin-hadoop2.7.tgz
2).新建spark目录:/usr/local/spark
3).将spark-2.3.1-bin-hadoop2.7.tgz复制到:/usr/local/spark,并解压缩
4).在/etc/profile文件中添加:
SPARK_HOME=/usr/local/spark/spark-2.3.1-bin-hadoop2.7
PATH=$PATH:${SPARK_HOME}/bin
5).输入source /etc/profile 使profile文件生效
6).修改spark配置
进入spark-2.3.1-bin-hadoop2.4/conf
复制模板文件:
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves
7).编辑spark-env.sh,添加:
export JAVA_HOME=/usr/local/java/jdk1.8.0_131
export SCALA_HOME=SCALA_HOME=/usr/local/scala/scala-2.12.2
export SPARK_MASTER_IP=172.20.0.204
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/usr/local/spark/spark-2.3.1-bin-hadoop2.7
8).输入source spark-env.sh,使spark-env.sh文件生效
9).试一下spark是否安装成功
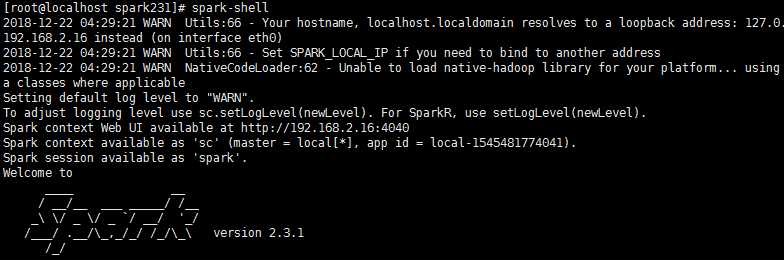
统计一下README.md文件中的单词个数

Reference:
[1]:https://margaret0071.iteye.com/blog/2384805
Centos6.8 安装spark-2.3.1 以及 scala-2.12.2
标签:hadoop .com red 交互 https 图片 centos6.8 export 服务器
原文地址:https://www.cnblogs.com/hoojjack/p/10160663.html