标签:inf 特点 框架 drive int storm spark tor sys

Storm与Spark、Hadoop这三种框架,各有各的优点,每个框架都有自己的最佳应用场景。所以,在不同的应用场景下,应该选择不同的框架。
1.Storm是最佳的流式计算框架,Storm由Java和Clojure写成,Storm的优点是全内存计算,所以它的定位是分布式实时计算系统,按照Storm作者的说法,Storm对于实时计算的意义类似于Hadoop对于批处理的意义。
Storm的适用场景:
1)流数据处理
Storm可以用来处理源源不断流进来的消息,处理之后将结果写入到某个存储中去。
2)分布式RPC。由于Storm的处理组件是分布式的,而且处理延迟极低,所以可以作为一个通用的分布式RPC框架来使用。
在这里还是要推荐下我自己建的大数据学习交流群:199427210,群里都是学大数据开发的,如果你正在学习大数据 ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有大数据软件开发相关的),包括我自己整理的一份最新的大数据进阶资料和高级开发教程,欢迎进阶中和进想深入大数据的小伙伴加入。
2.Spark是一个基于内存计算的开源集群计算系统,目的是更快速的进行数据分析。Spark由加州伯克利大学AMP实验室Matei为主的小团队使用Scala开发,类似于Hadoop MapReduce的通用并行计算框架,Spark基于Map Reduce算法实现的分布式计算,拥有Hadoop MapReduce所具有的优点,但不同于MapReduce的是Job中间输出和结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的Map Reduce的算法。
Spark的适用场景:
1)多次操作特定数据集的应用场合
Spark是基于内存的迭代计算框架,适用于需要多次操作特定数据集的应用场合。需要反复操作的次数越多,所需读取的数据量越大,受益越大,数据量小但是计算密集度较大的场合,受益就相对较小。
2)粗粒度更新状态的应用
由于RDD的特性,Spark不适用那种异步细粒度更新状态的应用,例如Web服务的存储或者是增量的Web爬虫和索引。就是对于那种增量修改的应用模型不适合。
总的来说Spark的适用面比较广泛且比较通用。
3.Hadoop是实现了MapReduce的思想,将数据切片计算来处理大量的离线数据。Hadoop处理的数据必须是已经存放在HDFS上或者类似HBase的数据库中,所以Hadoop实现的时候是通过移动计算到这些存放数据的机器上来提高效率。
Hadoop的适用场景:
1)海量数据的离线分析处理
2)大规模Web信息搜索
3)数据密集型并行计算
简单来说:
Hadoop适合于离线的批量数据处理适用于对实时性要求极低的场景
Storm适合于实时流数据处理,实时性方面做得极好
Spark是内存分布式计算框架,试图吞并Hadoop的Map-Reduce批处理框架和Storm的流处理框架,但是Spark已经做得很不错了,批处理方面性能优于Map-Reduce,但是流处理目前还是弱于Storm,产品仍在改进之中
大数据是不能用传统的计算技术处理的大型数据集的集合。它不是一个单一的技术或工具,而是涉及的业务和技术的许多领域。
目前主流的三大分布式计算系统分别为Hadoop、Spark和Strom:
Hadoop是使用Java编写,允许分布在集群,使用简单的编程模型的计算机大型数据集处理的Apache的开源框架。 Hadoop框架应用工程提供跨计算机集群的分布式存储和计算的环境。 Hadoop是专为从单一服务器到上千台机器扩展,每个机器都可以提供本地计算和存储。
Hadoop适用于海量数据、离线数据和负责数据,应用场景如下:
基于京麦业务三个实用场景:
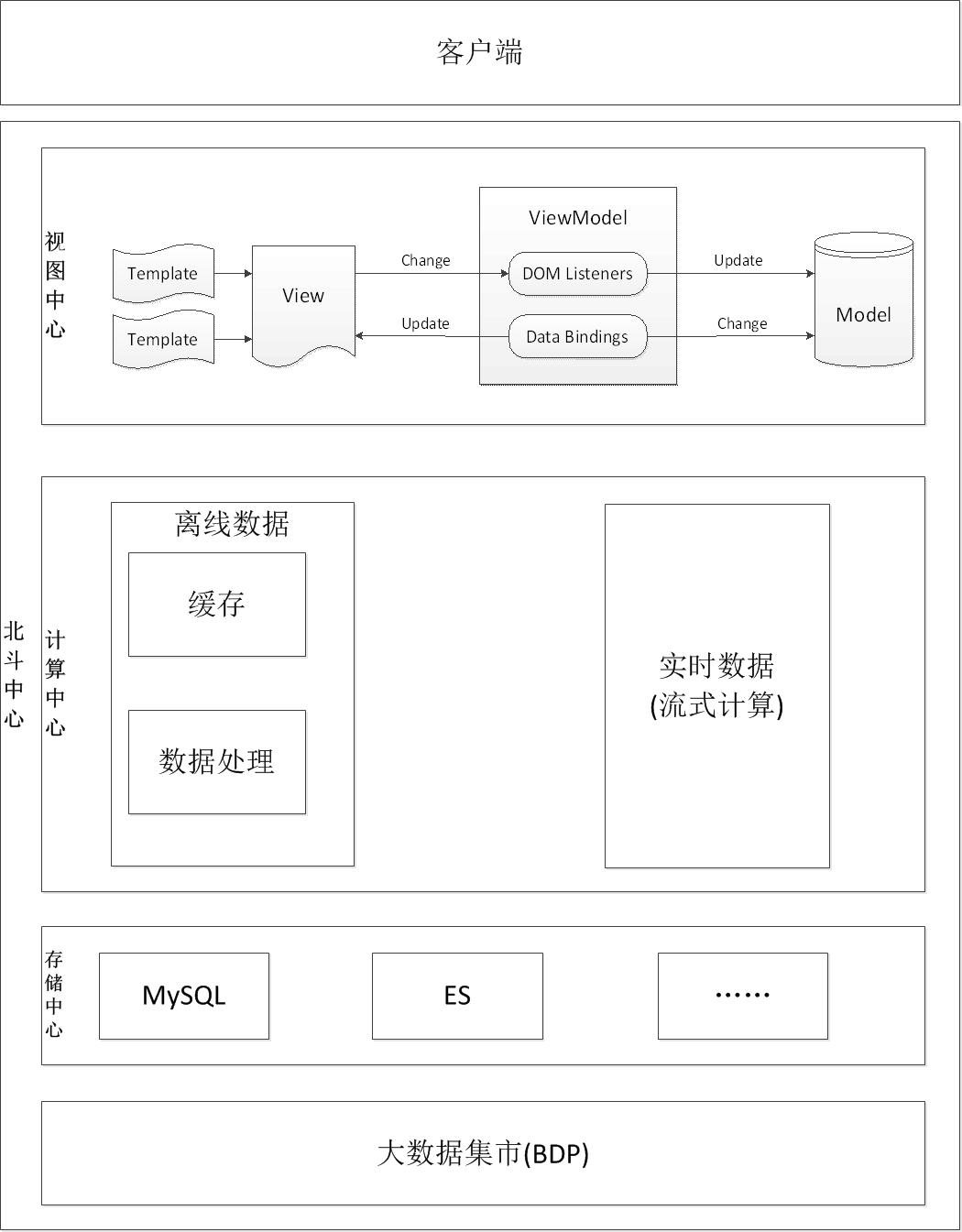
都属于离线数据,决定采用Hadoop作为京麦数据类产品的数据计算引擎,后续会根据业务的发展,会增加Storm等流式计算的计算引擎,下图是京麦的北斗系统架构图:
Hadoop分布式处理框架核心设计:
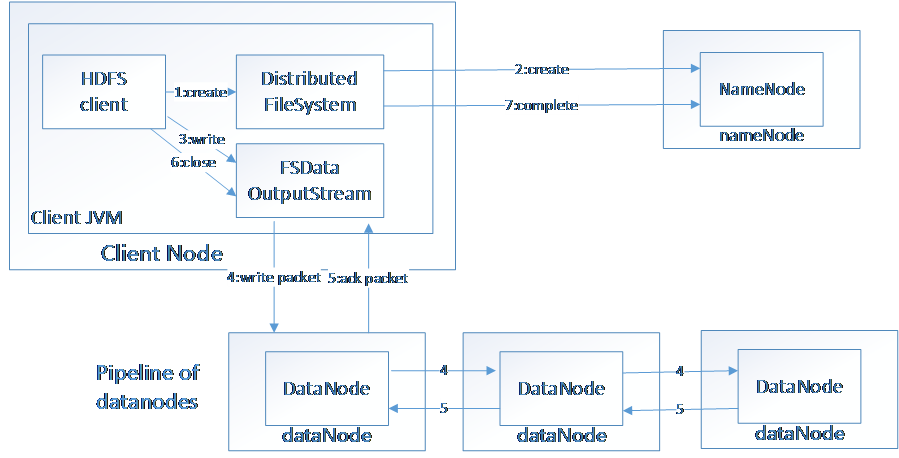
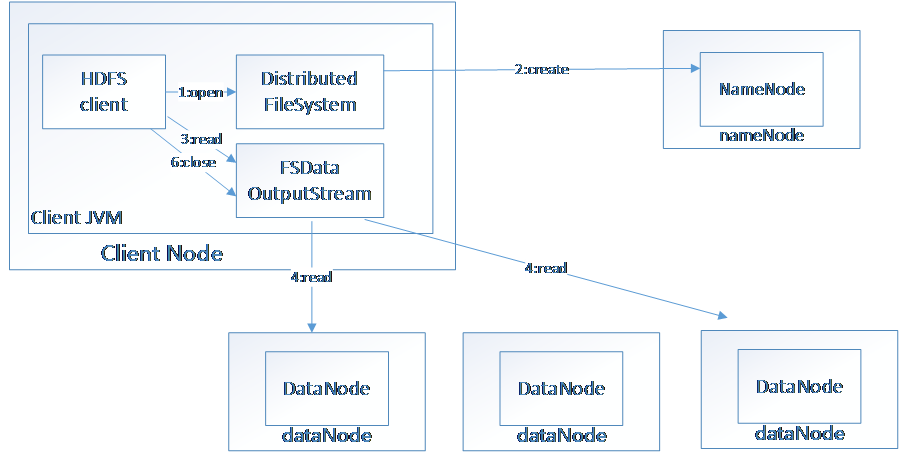
2.1 HDFS
HDFS(Hadoop File System),是Hadoop的分布式文件存储系统。
将大文件分解为多个Block,每个Block保存多个副本。提供容错机制,副本丢失或者宕机时自动恢复。默认每个Block保存3个副本,64M为1个Block。将Block按照key-value映射到内存当中。
2.2 MapReduce
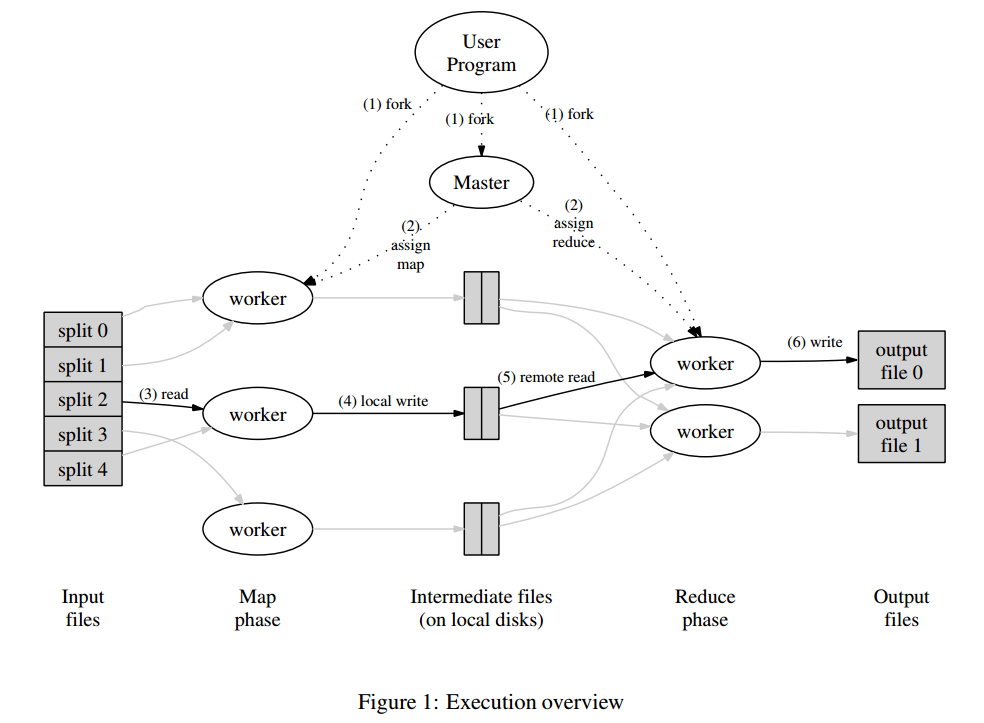
MapReduce是一个编程模型,封装了并行计算、容错、数据分布、负载均衡等细节问题。MapReduce实现最开始是映射map,将操作映射到集合中的每个文档,然后按照产生的键进行分组,并将产生的键值组成列表放到对应的键中。化简(reduce)则是把列表中的值化简成一个单值,这个值被返回,然后再次进行键分组,直到每个键的列表只有一个值为止。这样做的好处是可以在任务被分解后,可以通过大量机器进行并行计算,减少整个操作的时间。但如果你要我再通俗点介绍,那么,说白了,Mapreduce的原理就是一个分治算法。
2.3 HIVE
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行,这套SQL 简称HQL。使不熟悉mapreduce 的用户很方便的利用SQL 语言查询,汇总,分析数据。而mapreduce开发人员可以把己写的mapper 和reducer 作为插件来支持Hive 做更复杂的数据分析。
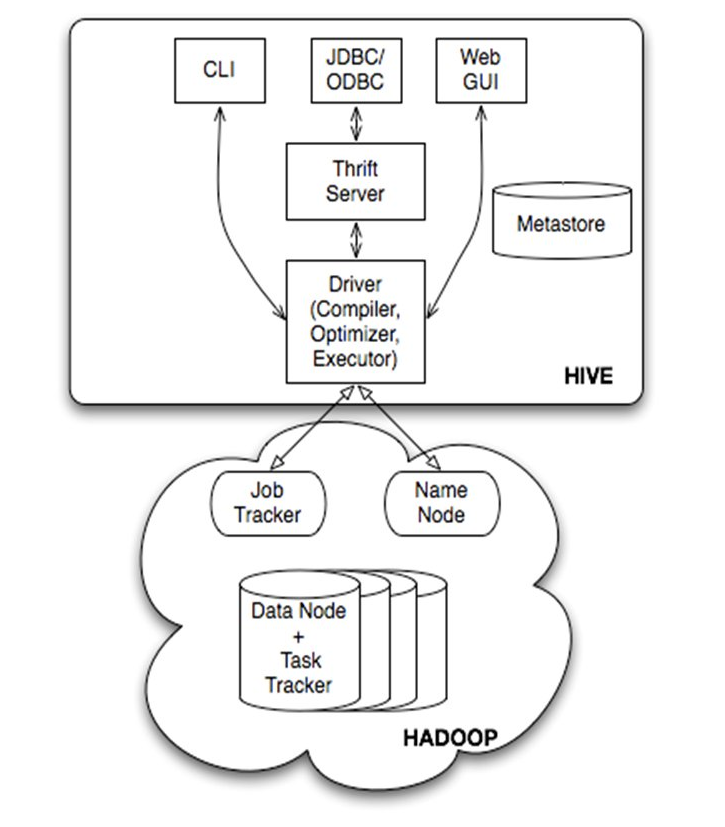
由上图可知,hadoop和mapreduce是hive架构的根基。Hive架构包括如下组件:CLI(command line interface)、JDBC/ODBC、Thrift Server、WEB GUI、metastore和Driver(Complier、Optimizer和Executor)。
标签:inf 特点 框架 drive int storm spark tor sys
原文地址:https://www.cnblogs.com/gon99/p/10162070.html