标签:learn 例子 pytho 下载 strong 价格 原理 ESS 高等数学
线性回归是一种较为简单,但十分重要的机器学习方法。掌握线性的原理及求解方法,是深入了解线性回归的基本要求。除此之外,线性回归也是监督学习回归部分的基石,希望您能通过本次实验掌握机器学习的一些重要的思想。
在上一个「监督学习介绍」的实验中,我们了解了分类和回归问题的区别。也就是说,回归问题旨在实现对连续值的预测,例如股票的价格、房价的趋势等。比如,下方展现了一个房屋面积和价格的对应关系图。
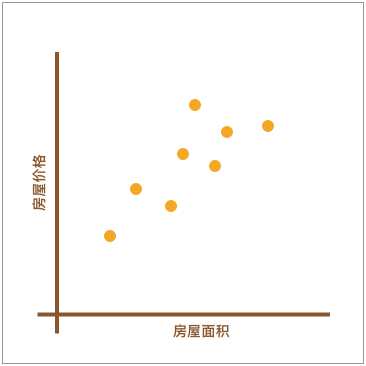
如上图所示,不同的房屋面积对应着不同的价格。现在,假设我手中有一套房屋想要出售,而出售时就需要预先对房屋进行估值。于是,我想通过上图,也就是其他房屋的售价来判断手中的房产价值是多少。应该怎么做呢?
我采用的方法是这样的。如下图所示,首先画了一条红色的直线,让其大致验证橙色点分布的延伸趋势。然后,我将已知房屋的面积大小对应到红色直线上,也就是蓝色点所在位置。最后,再找到蓝色点对应于房屋的价格作为房屋最终的预估价值。
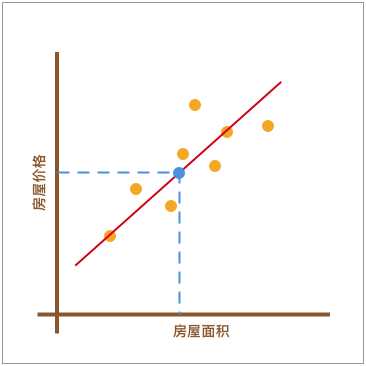
在上图呈现的这个过程中,通过找到一条直线去拟合数据点的分布趋势的过程,就是线性回归的过程。而线性回归中的「线性」代指线性关系,也就是图中所绘制的红色直线。
此时,你可能心中会有一个疑问。上图中的红色直线是怎么绘制出来的呢?为什么不可以像下图中另外两条绿色虚线,而偏偏要选择红色直线呢?
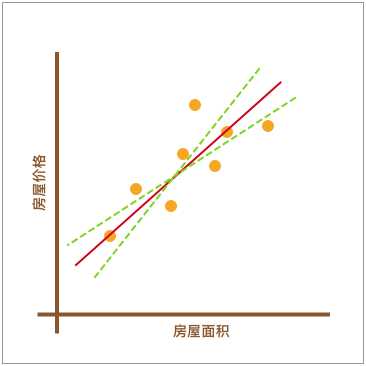
上图中的绿色虚线的确也能反应数据点的分布趋势。所以,找到最适合的那一条红色直线,也是线性回归中需要解决的重要问题之一。
通过上面这个小例子,相信你对线性回归已经有一点点印象了,至少大致明白它能做什么。接下来的内容中,我们将了解线性回归背后的数学原理,以及使用 Python 代码对其实现。
上面针对线性回归的介绍内容中,我们列举了一个房屋面积与房价变化的例子。其中,房屋面积为自变量,而房价则为因变量。另外,我们将只有 1 个自变量的线性拟合过程叫做一元线性回归。
下面,我们就生成一组房屋面积和房价变化的示例数据。x 为房屋面积,单位是平方米; y 为房价,单位是万元。
import numpy as np
x = np.array([56, 72, 69, 88, 102, 86, 76, 79, 94, 74])
y = np.array([92, 102, 86, 110, 130, 99, 96, 102, 105, 92])
?
示例数据由 10 组房屋面积及价格对应组成。接下来,通过 Matplotlib 绘制数据点,x, y 分别对应着横坐标和纵坐标。
from matplotlib import pyplot as plt
%matplotlib inline
plt.scatter(x, y)
plt.xlabel("Area")
plt.ylabel("Price")
?
正如上面所说,线性回归即通过线性方程(1 次函数)去拟合数据点。那么,我们令函数的表达式为:
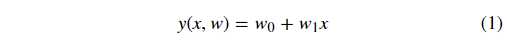
公式(1)是典型的一元一次函数表达式,我们通过组合不同的 w0w0 和 w1w1 的值得到不同的拟合直线。我们对公式(1)进行代码实现:
def f(x, w0, w1):
y = w0 + w1 * x
return y
那么,哪一条直线最能反应出数据的变化趋势呢?
想要找出对数据集拟合效果最好的直线,这里再拿出上小节图示进行说明。如下图所示,当我们使用 y(x,w)=w0+w1xy(x,w)=w0+w1x 对数据进行拟合时,我们能得到拟合的整体误差,即图中蓝色线段的长度总和。如果某一条直线对应的误差值最小,是不是就代表这条直线最能反映数据点的分布趋势呢?
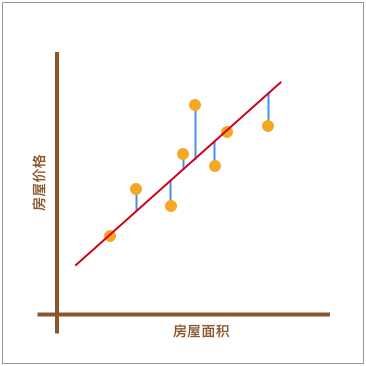
正如上面所说,如果一个数据点为 (xi, yi),那么它对应的误差就为:
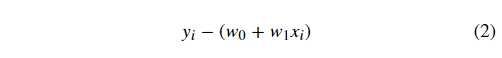
上面的误差往往也称之为残差。但是在机器学习中,我们更喜欢称作「损失」,即真实值和预测值之间的偏离程度。那么,对应 n 个全部数据点而言,其对应的残差损失总和就为:
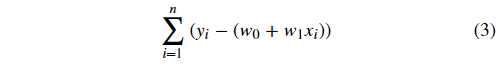
在线性回归中,我们使用残差的平方和来表示所有样本点的误差。公式如下:
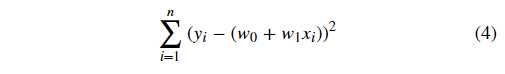
对于公式(4)而言,机器学习中有一个专门的名词,那就是「平方损失函数」。而为了得到拟合参数 w0 和 w1 最优的数值,我们的目标就是让公式(4)对应的平方损失函数最小。
同样,我们可以对公式(4)进行代码实现:
def square_loss(x, y, w0, w1):
loss = sum(np.square(y - (w0 + w1*x)))
return loss
?
最小二乘法是用于求解线性回归拟合参数 w 的一种常用方法。最小二乘法中的「二乘」代表平方,最小二乘也就是最小平方。而这里的平方就是指代上面的平方损失函数。
简单来讲,最小二乘法也就是求解平方损失函数最小值的方法。那么,到底该怎样求解呢?这就需要使用到高等数学中的知识。推导如下:
首先,平方损失函数为:
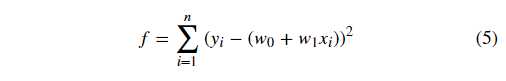
我们的目标是求取平方损失函数 min(f) 最小时,对应的w。首先求 f 的 1 阶偏导数:
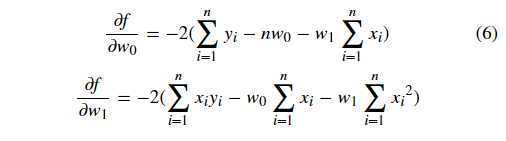
然后,我们令 ?f?w0=0?f?w0=0 以及 ?f?w1=0?f?w1=0,解得:
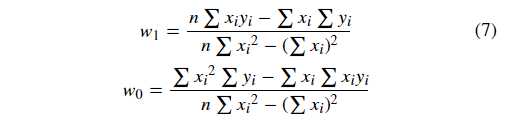
到目前为止,已经求出了平方损失函数最小时对应的 ww 参数值,这也就是最佳拟合直线。
我们将公式(7)求解得到 ww 的过程进行代码实现:
def w_calculator(x, y):
n = len(x)
w1 = (n*sum(x*y) - sum(x)*sum(y))/(n*sum(x*x) - sum(x)*sum(x))
w0 = (sum(x*x)*sum(y) - sum(x)*sum(x*y))/(n*sum(x*x)-sum(x)*sum(x))
return w0, w1
于是,可以向函数 w_calculator(x, y) 中传入 x 和 y 得到 w0w0 和 w1w1 的值。
w_calculator(x, y)
当然,我们也可以求得此时对应的平方损失的值:
w0 = w_calculator(x, y)[0]
w1 = w_calculator(x, y)[1]
square_loss(x, y, w0, w1)
接下来,我们尝试将拟合得到的直线绘制到原图中:
x_temp = np.linspace(50,120,100) # 绘制直线生成的临时点
plt.scatter(x, y)
plt.plot(x_temp, x_temp*w1 + w0, ‘r‘)
从上图可以看出,拟合的效果还是不错的。那么,如果你手中有一套 150 平米的房产想售卖,获得预估报价就只需要带入方程即可:
f(150, w0, w1)
这里得到的预估售价约为 154 万元。
上面的内容中,我们学习了什么是最小二乘法,以及使用 Python 对最小二乘线性回归进行了完整实现。那么,我们如何利用机器学习开源模块 scikit-learn 实现最小二乘线性回归方法呢?
使用 scikit-learn 实现线性回归的过程会简单很多,这里要用到 LinearRegression() 类。看一下其中的参数:
sklearn.linear_model.LinearRegression(fit_intercept=True,normalize=False,copy_X=True,n_jobs=1)
其中:
fit_intercept: 默认为 True,计算截距项。normalize: 默认为 False,不针对数据进行标准化处理。copy_X: 默认为 True,即使用数据的副本进行操作,防止影响原数据。n_jobs: 计算时的作业数量。默认为 1,若为 -1 则使用全部 CPU 参与运算。"""scikit-learn 线性回归拟合
"""
from sklearn.linear_model import LinearRegression
# 定义线性回归模型
model = LinearRegression()
model.fit(x.reshape(len(x),1) , y) # 训练, reshape 操作把数据处理成 fit 能接受的形状
# 得到模型拟合参数
model.intercept_, model.coef_
我们通过 model.intercept_ 得到拟合的截距项,即上面的 w0w0,通过 model.coef_ 得到 xx 的系数,即上面的 w1w1。对比发现,结果是完全一致的。
同样,我们可以预测 150 平米房产的价格:
model.predict([[150]])
可以看到,这里得出的结果和自行实现计算结果一致。
学习完上面的内容,相信你已经了解了什么是最小二乘法,以及如何使用最小二乘法进行线性回归拟合。上面,实验采用了求偏导数的方法,并通过代数求解找到了最佳拟合参数 w 的值。
这里,我们尝试另外一种方法,即通过矩阵的变换来计算参数 w 。推导如下:
首先,一元线性函数的表达式为 y(x,w)=w0+w1x,表达成矩阵形式为:

*矩阵求导是超纲内容,如果有兴趣可以 自行阅读学习。
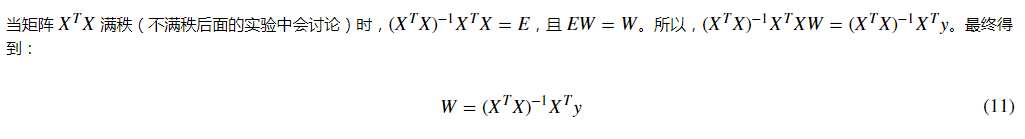
我们可以针对公式(11)进行代码实现:
def w_matrix(x, y):
w = (x.T * x).I * x.T * y
return w
我们针对原 x 数据添加截距项系数 1。
x = np.matrix([[1,56],[1,72],[1,69],[1,88],[1,102],[1,86],[1,76],[1,79],[1,94],[1,74]])
y = np.matrix([92, 102, 86, 110, 130, 99, 96, 102, 105, 92])
w_matrix(x, y.reshape(10,1))
可以看到,矩阵计算结果和前面的代数计算结果一致。你可能会有疑问,那就是为什么要采用矩阵变换的方式计算?一开始学习的代数计算方法不好吗?
其实,并不是说代数计算方式不好,在小数据集下二者运算效率接近。但是,当我们面对十万或百万规模的数据时,矩阵计算的效率就会高很多,这就是为什么要学习矩阵计算的原因。
目前,你已经学习了如何使用最小二乘法进行线性回归拟合,以及通过代数计算和矩阵变换两种方式计算拟合系数 ww,这已经达到了掌握线性回归方法的要求。在这个小节中,我们将尝试加载一个真实数据集,并使用 scikit-learn 构建预测模型,实现回归预测。
既然前面的 2 个小节中,都使用了和房价相关的示例数据。这里,我们就采用一个真实的房价数据集,也就是「波士顿房价数据集」。
波士顿房价数据集是机器学习中非常知名的数据集,它被用于多篇回归算法研究的学术论文中。该数据集共计 506 条,其中包含有 13 个与房价相关的特征以及 1 个目标值(房价)。
首先,我们使用 Pandas 加载并预览数据集。数据集名称为 course-5-boston.csv。
# 运行并下载数据集
!wget -nc http://labfile.oss.aliyuncs.com/courses/1081/course-5-boston.csv
import pandas as pd
df = pd.read_csv("course-5-boston.csv")
?
查看 DataFrame 前 5 行数据。
df.head()
该数据集统计了波士顿地区各城镇的住房价格中位数,以及与之相关的特征。每列数据的列名解释如下:
CRIM: 城镇犯罪率。ZN: 占地面积超过 2.5 万平方英尺的住宅用地比例。INDUS: 城镇非零售业务地区的比例。CHAS: 查尔斯河是否经过 (=1 经过,=0 不经过)。NOX: 一氧化氮浓度(每 1000 万份)。RM: 住宅平均房间数。AGE: 所有者年龄。DIS: 与就业中心的距离。RAD: 公路可达性指数。TAX: 物业税率。PTRATIO: 城镇师生比例。BLACK: 城镇的黑人指数。LSTAT: 人口中地位较低人群的百分数。MEDV: 城镇住房价格中位数。本次实验中,我们不会使用到全部的数据特征。这里,仅选取 CRIM, RM, LSTAT 三个特征用于线性回归模型训练。我们将这三个特征的数据单独拿出来,并且使用 describe() 方法查看其描述信息。 describe() 统计了每列数据的个数、最大值、最小值、平均数等信息。
features = df[[‘crim‘, ‘rm‘, ‘lstat‘]]
features.describe()
同样,我们将目标值单独拿出来。训练一个机器学习预测模型时,我们通常会将数据集划分为 70% 和 30% 两部分。
其中,70% 的部分被称之为训练集,用于模型训练。例如,这里的线性回归,就是从训练集中找到最佳拟合参数 ww 的值。另外的 30% 被称为测试集。对于测试集而言,首先我们知道它对应的真实目标值,然后可以给学习完成的模型输入测试集中的特征,得到预测目标值。最后,通过对比预测的目标值与真实目标值之间的差异,评估模型的预测性能。
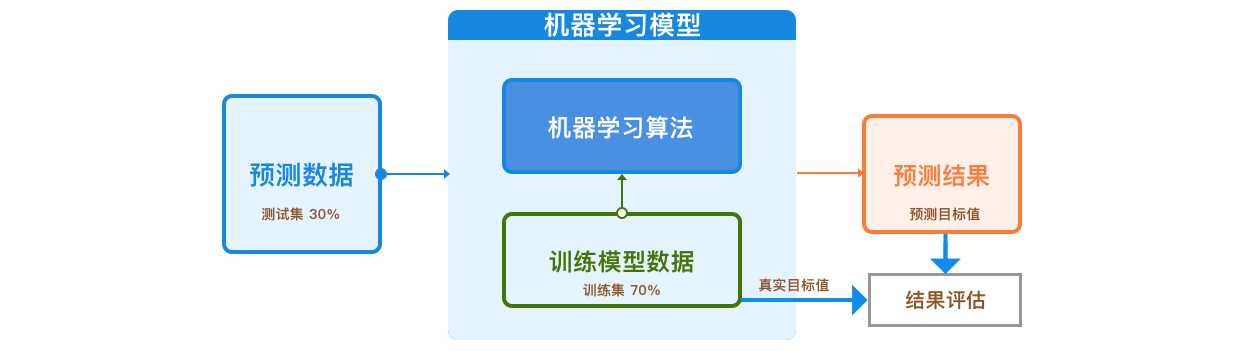
上图就是一个简单的机器学习模型训练流程。接下来,我们针对数据集的特征和目标进行分割,分别得到 70% 的训练集和 30% 的测试集。其中,训练集特征、训练集目标、测试集特征和测试集目标分别定义为:train_x, train_y, test_x, test_y。
target = df[‘medv‘] # 目标值数据
split_num = int(len(features)*0.7) # 得到 70% 位置
train_x = features[:split_num] # 训练集特征
train_y = target[:split_num] # 训练集目标
test_x = features[split_num:] # 测试集特征
test_y = target[split_num:] # 测试集目标
划分完数据集之后,就可以构建并训练模型。同样,这里要用到 LinearRegression() 类。对于该类的参数就不再重复介绍了。
from sklearn.linear_model import LinearRegression
model = LinearRegression() # 建立模型
model.fit(train_x, train_y) # 训练模型
model.coef_, model.intercept_ # 输出训练后的模型参数和截距项
上面的单元格中,我们输出了线性回归模型的拟合参数。也就是最终的拟合线性函数为:
其中,x1, x2, x3 分别对应数据集中 LSTAT, RM 和 PTRATIO 列。接下来,向训练好的模型中输入测试集的特征得到预测值。
preds = model.predict(test_x) # 输入测试集特征进行预测
preds # 预测结果
对于回归预测结果,通常会有平均绝对误差、平均绝对百分比误差、均方误差等多个指标进行评价。这里,我们先介绍两个:
平均绝对误差(MAE)就是绝对误差的平均值,它的计算公式如下:

其中,yi 表示真实值,y? i 表示预测值,nn 则表示值的个数。MAE 的值越小,说明预测模型拥有更好的精确度。我们可以尝试使用 Python 实现 MAE 计算函数:
def mae_value(y_true, y_pred):
n = len(y_true)
mae = sum(np.abs(y_true - y_pred))/n
return mae
均方误差(MSE)它表示误差的平方的期望值,它的计算公式如下:

其中,yiyi 表示真实值,y? iy^i 表示预测值,nn 则表示值的个数。MSE 的值越小,说明预测模型拥有更好的精确度。同样,我们可以尝试使用 Python 实现 MSE 计算函数:
def mse_value(y_true, y_pred):
n = len(y_true)
mse = sum(np.square(y_true - y_pred))/n
return mse
?
于是,我们可以计算出上面模型的平均指标,即预测结果的 MSE 和 MAE 值:
mae = mae_value(test_y.values, preds)
mse = mse_value(test_y.values, preds)
print("MAE: ", mae)
print("MSE: ", mse)
?
可以看到,这里模型预测结果的平均绝对误差约为 13.02。如果你计算一下全部目标值的平均值(结果为22 左右),你会发现 13.02 的平均绝对误差在本次实验中应该说是很大了。这也就说明模型的表现并不好,这是什么原因呢?
这主要是因为我们没有针对数据进行预处理。上面的实验中,我们随机选择了 3 个特征,并没有合理利用数据集提供的其他特征。除此之外,也没有针对异常数据进行剔除以及规范化处理。
当然,关于使用机器学习训练模型过程中涉及到的数据预处理知识,我们会在后续的课程中逐渐学习。掌握好线性回归的原理和实现方法,才是本次实验内容的重点。
本次实验是楼+ 课程的第一节真正意义上的实战内容,我们从线性回归原理入手,学习了最小二乘法的两种求解方法,并针对线性回归算法进行了完整实现,相信会对你有所帮助。回顾本次实验的知识点有:
拓展阅读:
标签:learn 例子 pytho 下载 strong 价格 原理 ESS 高等数学
原文地址:https://www.cnblogs.com/coshaho/p/10163337.html