标签:比例 效率 call 网络 分布 代码 单词 log 如意
在开始调参之前,需要确定方向,所谓方向就是确定了之后,在调参过程中不再更改
1、根据任务需求,结合数据,确定网络结构。
例如对于RNN而言,你的数据是变长还是非变长;输入输出对应关系是many2one还是many2many等等,更多结构参考如下
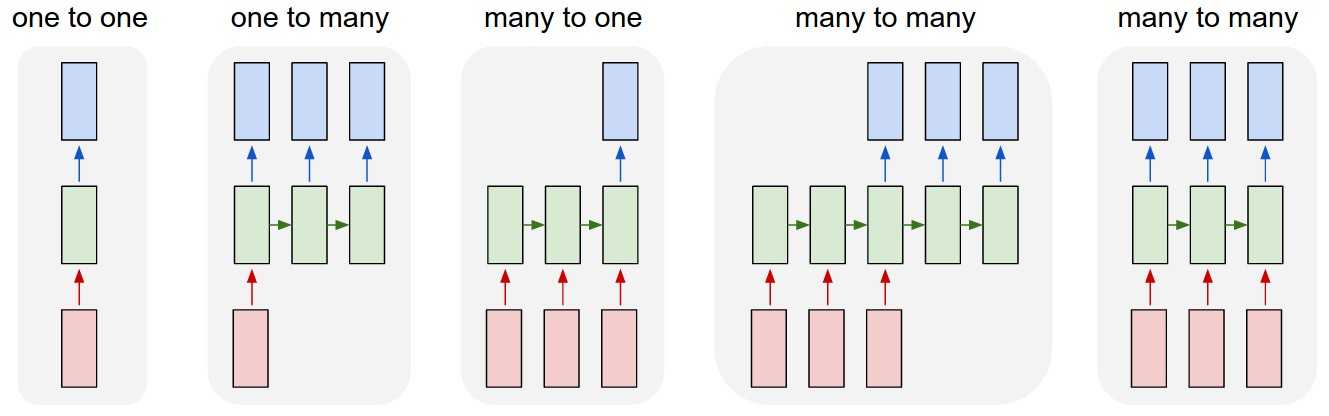
非RNN的普通过程,从固定尺寸的输入到固定尺寸的输出(比如图像分类)
输出是序列(例如图像标注:输入是一张图像,输出是单词的序列)
输入是序列(例如情绪分析:输入是一个句子,输出是对句子属于正面还是负面情绪的分类)
输入输出都是序列(比如机器翻译:RNN输入一个英文句子输出一个法文句子)
同步的输入输出序列(比如视频分类中,我们将对视频的每一帧都打标签)
2、确定训练集、验证集和测试集,并尽可能的确保它们来自相同的分布,并且训练集与测试集的划分通常是7:3,然后在训练集中在进行验证集的划分,验证集的划分可以是交叉验证,也可以是固定比例。
一旦确定了数据集的划分,就能够专注于提高算法的性能。如果能够保证三者来自相同的分布,对于后续的问题定位也会有着极大的意义。
例如,某个模型在训练集上效果很好,但是在测试集上的结果并不如意,如果它们来自相同的分布,那么就可以肯定:模型在训练集上过拟合了(overfitting),那么对应的解决办法就是获取更多的训练集。
但是如果训练集和测试集来自不同的分布,那么造成上述结果的原因可能会是多种的:
(i).在训练集上过拟合;(ii).测试集数据比训练集数据更难区分,这时,有必要去进行模型结构,算法方面的修改;(iii).测试集并不一定更难区分,只是与训练集的分布差异比较大,那么此时如果我们去想方设法提高训练集上的性能,这些工作都将是白费努力。
3、确定单一的评估算法的指标。
这里需要注意的是,在进行调参之前,我们需要明确我们的目的是什么,是尽可能的分的准(查准率,precision)还是尽可能的找的全(查全率,recall)亦或者两者都要考虑(F1或者ROC曲线下面积);还或者说,我不仅要关注准确率还要考虑时间效率(此时可以将准确率与算法的运行时间做一个简单的加权,来构建出一个新的指标)。
我们需要确定使用的指标,并且在优化过程中不再更改,否者你会不知道究竟哪个参数好,因为两个不同的指标之间不容易比较。另外,需要明确使用一个指标,这样能够更加直观的观察不同参数之间的好坏。
4、
参考文献:
2、Machine Learning Yearning,吴恩达
标签:比例 效率 call 网络 分布 代码 单词 log 如意
原文地址:https://www.cnblogs.com/kamekin/p/10163743.html