标签:cli 透视投影 影子 pass 了解 存在 line 分辨率 演示
这两天勉勉强强把一个shadowmap的demo做出来了。参考资料多,苦头可不少。Shadow Map技术是目前与Shadow Volume技术并行的传统阴影渲染技术,而且在游戏领域可谓占很大优势。本篇是第一辑。——ZwqXin.com
Shadow Map的原理很简单,但是实现起来到处是雷。当然这只是我的体会。恩,不过就是“从光源处看场景,那些看不见的区域全部都该是阴影”。很容易看出,与针对特定模型的Shadow Volume不同,Shadow Map是针对场景的。这就是说,对一个光源应用一次Shadow Map,该光源所“看”到的所有对象——都在作阴影判断的范围内。当然,不针对模型说明了不用再像Shadow Volume那样需要考究和处理模型的形状、几何信息,工作成本下去了,效率上来了,因此在不那么注重阴影准确度的游戏里可是很受欢迎。准确度?恩,是的,有得必有失,这样两者至今才能依然肩并肩。Shadow Map注重对场景信息的采样,采样,也就是说要考究锯齿处理——这也是Shadow Map技术不断求突破的核心。当然还有别的便利,譬如对透明纹理的阴影生成支持,shadow volume前天一直在找可以实现这种效果的方法,但是暂时没找着——譬如一张纯黑背静的树的图片做Billboard,shadow volume处理的是一个矩形,得出的阴影也只是个矩形;但是Shadow Map中可以预先处理这张图片(剔除背景色)再做MAP操作,可以得出树轮廓的阴影——Billboard在Shadow Volume眼里是一个矩形的“模型”(可能有别的技法可以改变它的这种“看法”,知情者可否相告呢?),但在shadow map眼里是“场景”的一部分,它完全可以融合在这个大环境中生成阴影贴图。
两步走。首先是获得光源视觉下场景深度,保存在一张纹理上。通常是通过上一篇所说的矩阵变换,到达光源视点下的屏幕投影空间,截屏,把该截屏的深度信息写入一张纹理上(通常用专门的深度纹理,它可以用来作深度比较)。之后一步,回到普通的相机视觉,对相机所看到的每一点,找到刚才深度纹理对应的那个点——把该点像素在纹理图的深度作为判断该点是否应该处于阴影区域的依据。怎样判断?和“光源 - 该像素点”的距离做比较咯。实际上这个比较在做深度图的时候就可以出来了啊~为什么要等到做完深度图再专门拿出来比较呢?因为在光视觉下看到的“点的集合”跟照相机视觉下看到的“点集合”是不一样的。通俗点讲,两种视觉下看到的场景不一样(除非你照相机本来就在光源,视线一致),这么说来,可以“点与点对应”(注意,不是唯一对应)的那部分仅仅是这两个“点集合”的交集而已.......比两者中任一者都要来得小。我们于是只处理这部分可以一一对应起来的点,也只能处理它们——这里就隐含了一个巨大的问题了:那些在相机中可以看到,但是在光源视觉下看不到的场景怎么办?这部分场景的点做不了比较啊!是的,我思考这个问题颇久了,然后我在下篇将会讲到这个问题。
比较出来,把距离大于对应深度的那些部分涂黑就可以了。比较部分,老实说,我觉得手工比较很麻烦,毕竟这种对应关系是很难确定的。幸好OPENGL有专门的API给我们来做这事情,呵呵。完成这种比较有几个条件:1.上面提到了深度纹理就是条件之一,它能直接储存深度;2.深度纹理比较命令。它们的位置看起来是这样的:
GenTex() //一般可在初始化里调用
{
..................
glGenTextures(1, &shadowmapid);
glBindTexture(GL_TEXTURE_2D, shadowmapid);
glTexImage2D(GL_TEXTURE_2D, 0, GL_DEPTH_COMPONENT, fbowidth, fboheight, 0,
GL_DEPTH_COMPONENT, GL_UNSIGNED_INT, NULL);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
...............
}
GenShadow()
{
glBindTexture(GL_TEXTURE_2D, shadowmapid);
渲染场景到纹理
.....
}
CastShadow
{
glBindTexture(GL_TEXTURE_2D, shadowmapid);
//深度纹理比较的API
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_COMPARE_MODE, GL_COMPARE_R_TO_TEXTURE);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_COMPARE_FUNC, GL_LEQUAL);
//glTexParameteri(GL_TEXTURE_2D, GL_DEPTH_TEXTURE_MODE, GL_INTENSITY);
...............//正常地再渲染一次场景
}
GenTex() //一般可在初始化里调用{..................glGenTextures(1, &shadowmapid); glBindTexture(GL_TEXTURE_2D, shadowmapid); glTexImage2D(GL_TEXTURE_2D, 0, GL_DEPTH_COMPONENT, fbowidth, fboheight, 0, GL_DEPTH_COMPONENT, GL_UNSIGNED_INT, NULL); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR); glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);...............}GenShadow(){glBindTexture(GL_TEXTURE_2D, shadowmapid);渲染场景到纹理.....}CastShadow{glBindTexture(GL_TEXTURE_2D, shadowmapid);//深度纹理比较的APIglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_COMPARE_MODE, GL_COMPARE_R_TO_TEXTURE);glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_COMPARE_FUNC, GL_LEQUAL);//glTexParameteri(GL_TEXTURE_2D, GL_DEPTH_TEXTURE_MODE, GL_INTENSITY);...............//正常地再渲染一次场景}
同样是设置纹理特性(glTexParameteri),为什么不一起放在生成纹理时就操作呢?因为上面说过那个理由:我们不是比较整张深度图 嘛(当然我不知道它内部是不是一比较就得全部比较的)。
涂黑部分,固定管道下见过是依赖于上面注释掉的那句。它能把比较结果X(两种结果,X =1代表距离大于深度,要涂黑;X = 0则相反,代表距离小于等于[GL_LEQUAL]深度,比较“通过”,不用处理)应用到纹理的所有通道(GL_INTENSITY大概表示这意思吧)。接下来用ALPHA测试存到透明通道里的结果,大于0.99则涂黑便可(我所看的那教程上就是这样做的);如果你跟我一样用shader来更灵活地处理像素,则可注释掉上面GL_INTENSITY那句,在我们的像素shader里,用sampler2DShadow采样上面那深度纹理,用shadow2DProj就同样能获取这个结果X了。
最后附录一下与GL_INTENSITY相关的几个纹理“像素值储存格式”(参考这里:平民程序):
GL_INTENSITY: RGBA = (X, X, X, X) 把结果储存到所有通道
GL_ALPHA: RGBA = (0, 0, 0, X) 仅把结果储存到Alpha通道
GL_LUMINANCE: RGBA = (X, X, X, 1)把结果储存到3个Color通道
更多关于本次实现的信息,可参考下篇:Shadow Map阴影贴图技术之探Ⅱ
本文来源于ZwqXin http://www.zwqxin.com/ , 转载请注明
原文地址:http://www.zwqxin.com/archives/opengl/shadow-map-1.html
这里是ZwqXin关于Shadow Map阴影贴图的OpenGL实现记录的第二辑,在上篇中讲述了大概原理,在本篇我想在此基础上讲讲我所认为和理解的细节关键点,并放出demo。上篇请参考 Shadow Map阴影贴图技术之探Ⅰ。——ZwqXin.com
事实上我在这里最想要讲的就是在再弹OpenGL矩阵——到另一个空间去 和 Shadow Map阴影贴图技术之探Ⅰ 中重重地提及但没有展开的两个问题(当然,其实当时是不太了解所以没说下去,但是经过这些天对demo运作效果的调试,我想我应该可以说说了)。其一,怎么变换矩阵到所需的光源视觉下投影空间,怎样转化为可查询的纹理;其二,那些“在相机中可以看到,但是在光源视觉下看不到”的场景,怎么办。
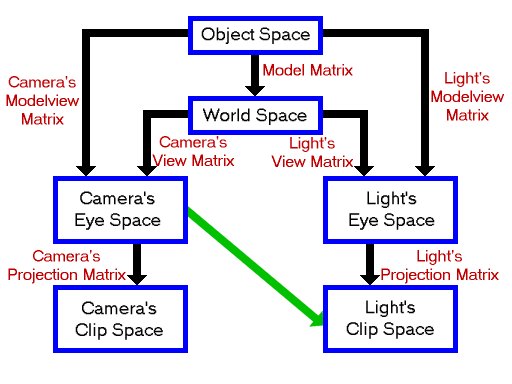
1. 到深度纹理的纹理空间去
先讲讲矩阵变换的问题。Shadow Map中的第一步(PASS 1),我们要把光源所看到的东西映射到一张深度纹理中,这涉及的也就上面这张曾经给我莫大启发的图中的变换。找到光源的视界,我们是回到最初,按照右边那条路一路变下来的,矩阵变换也应该按照这条路子思考。明确我们现在(在PASS 2中)要做的是:寻找这么一个矩阵变换,通过变换可以让物体某个坐标(局部坐标)逐步对应到那幅深度图的某个纹理坐标(即点与点对应,见上篇),这跟我以前说过的顶点坐标在不同空间的转换一样的嘛。因为涉及最终目标——纹理空间下的纹理坐标,所以我们叫此变换为:纹理矩阵变换。OpenGL也专门给了一个外号这类型的变换:GL_TEXTURE。和GL_MODELVIEW,GL_PROJECTION一样,是一个标志,glMatrixMode(GL_TEXTURE)表明接下来的变换是“纹理矩阵变换”。(标志有什么作用?它们作用在于通知OPENGL,这样OPENGL就知道对变换归类,知道顶点坐标和矩阵之间应该“怎么乘”了,也能在编程人员喊“给我把XX变换的矩阵叫来!”的时候,准确给出所需要的。典型的是shader中由opengl提供的gl_ModelViewMatrix,gl_ProjectionMatrix....当然还有gl_TextureMatrix[i]。)
好了,开始变换吧!(以下涉及变换实际顺序与代码操作顺序的倒置,不太清楚的朋友可以参考我写的乱弹OpenGL中的矩阵变换系列呵呵[ZwqxXin自卖广告]。)首先,与以前一样的是从模型空间转到世界空间,没问题!然后,啊,有问题啦!从世界坐标到光源版本的视图空间。问题不是这个转换矩阵怎么求(事实上很简单嘛,单独弄个光源的glLookat再获取此命令生成矩阵),而是上面那个从模型空间转到世界空间的模型变换矩阵怎么求!opengl里它是和视图变换矩阵合在一起的啊!直接求的话实在太委屈了,像往常那样如何?PASS1里不是就实施过一下光源视觉嘛,在那时候获得那个modelview怎么样?那你准备在什么时候去取?代码逻辑跟变换顺序是相反的,于是模型变换的代码会放在最后——而且紧接的就是物体的原始坐标在那儿了,假如物体很多,模型变换错综复杂,那你都搞不清该在哪放置获取矩阵的代码了——很不现实。那么退一步看呢?有没有直接从物体顶点坐标(原始坐标)到光源视觉下该顶点的位置坐标的变换呢?明显没有!
这时候你得好好看图了——路径还有一条:从相机的视图空间,经过世界空间到光源的视图空间!后者前面说了,很容易获得,可前者呢?这可是要求正常的那个视图变换的逆矩阵啊!视图变换矩阵与模型变换矩阵不同,它与后继操作(也就是模型变换)泾渭分明,可在确定“分界线”位置获得。关键是引入求逆!米办法了,去找个OPENGL矩阵类央求个求逆算法回来吧~~(注意是在设定正常相机时候去获得。)右边那些项之间的变换矩阵可轻松获得,于是我们跳到光源版本的屏幕空间吧,它是个平面,Z都被“归”掉了,而X,Y方向范围是[-1,1],缩半后向左上角偏移就有一个[0,1]的纹理坐标啦。等等!我刚才抽的是哪根烟!哪能跳得那么快啊!光源版本的视图空间(Light‘s Eye Space)到光源版本的屏幕空间(Light‘s Screen Space)中间的投影过程是有归一,裁减,透视相除等几个主要操作的,而图中的末端只不过是屏幕空间未进行透视相除(各分量除以w并舍弃z,由流水线完成)前的样子而已(所以也叫裁减空间)!(P.S.我只是学BOB大叔口头禅咋,我不是吸烟哦~)这么说可能更明白点:你看书gluPerspective生成的变换矩阵不都是个4*4矩阵么,不可能让坐标变成2*2的,透视相除要在opengl流水线上做。好了,再说下去就超过本篇主题范围了——知道这里的过程的结果是光源版本的裁减空间(Light‘s Clip Space)就可以了。
但是呢?现在是求“纹理变换矩阵”,很明显要自己做透视相除将上面的结果转化成2*2矩阵啊。当然可以按照某教程那样通过glTexGenfv来直接生成纹理(貌似也可免去求逆了),但是这样shader是处理不到的。因此我们干脆就把上述结果作为gl_TextureMatrix[0]交给shader,让vertex shader做剩下来的工作吧:
vec4 texcoord = gl_TextureMatrix[0] * gl_ModelViewMatrix * gl_Vertex;
shadowTexcoord = texcoord / texcoord.w;
shadowTexcoord = 0.5 * shadowTexcoord +0.5;
vec4 texcoord = gl_TextureMatrix[0] * gl_ModelViewMatrix * gl_Vertex; shadowTexcoord = texcoord / texcoord.w; shadowTexcoord = 0.5 * shadowTexcoord +0.5;
很明显透视相除和偏移后shadowTexcoord还是个 vec4,没有舍弃什么。是这样的,在fragment shader里shadow2DProj获取深度纹理的值,需要的纹理坐标要是个vec4(s,t,p,q)。另外回应一下,上面把gl_TextureMatrix[0] 乘 gl_ModelViewMatrix就能通过前者里那个 相机逆矩阵抵消gl_ModelViewMatrix里那个相机矩阵了,满足图中要求:
texcoord = gl_TextureMatrix[0] * gl_ModelViewMatrix * gl_Vertex
=Light_ProjectionMatrix * Light_ViewMatrix * Camera_ViewInverseMatrix
* gl_ModelViewMatrix * gl_Vertex
=Light_ProjectionMatrix * Light_ViewMatrix * Camera_ViewInverseMatrix
* Camera_ViewMatrix * ModelMatrix * gl_Vertex
=Light_ProjectionMatrix * Light_ViewMatrix * ModelMatrix * gl_Vertex
texcoord = gl_TextureMatrix[0] * gl_ModelViewMatrix * gl_Vertex=Light_ProjectionMatrix * Light_ViewMatrix * Camera_ViewInverseMatrix * gl_ModelViewMatrix * gl_Vertex=Light_ProjectionMatrix * Light_ViewMatrix * Camera_ViewInverseMatrix * Camera_ViewMatrix * ModelMatrix * gl_Vertex=Light_ProjectionMatrix * Light_ViewMatrix * ModelMatrix * gl_Vertex
2.当光被视线斩断
我确实把相机视觉下看到的场景的顶点映射到那张光源视觉下“拍到”的深度纹理图上了。但是那部分在相机中可以看到,但是在光源视觉下看不到的场景怎么办?它们无法在深度纹理图上找到它们的对应部分啊!这是个难题,也许有某些技术可以做得好,但我还没有探究到那里。目前我能确认的:一是把光源位置调得远一点,甚至无限远(辅以远近裁减面调节),这样光源处所看到的场景就更大了,出来的深度图信息更丰富,但是这样的话,光源所看到的场景细节就淡了,无疑得出的阴影锯齿加重;二是不要限定光源只看原点——但是看哪里呢?即使与相机焦点一致,也还是会出现这个问题的;三是把深度图范围弄大点,FBO不是可以做到截出比屏幕大的范围到大纹理里吗?但是光源的视野也就那么点了,还得让流水线的屏幕外裁减功能失效,因此我通过增大FBO纹理效果不明显。没辙了,你看我的demo,调整光源位置(靠近目标点,即减小光源视野,用空格视现)阴影消失,或者出来了一些黑黑的东西,(即该部分没有深度比较)就是这个原因。

更详细截图,包括成功之前的,看这里:
Shadow Map Demo1 -ZwqXin.com
本DEMO使用了shader,需要下载glew库到指定目录,下载见此:OpenGL常用的库
放上本DEMO:shadowmapdemo1byzwqxin.rar
按键:
→ ← ↑ ↓ PageUp 移动光源
鼠标左键下按不放并移动鼠标:旋转视角;鼠标滚轮移动
鼠标右键:自动旋转开关
空格:(默认光源目标点定位于原点)正常模式/射线可见模式/光源目标点定位于与相机焦点一致
P.S.下篇:[Shadow Map阴影贴图技术之探Ⅲ]
本文来源于ZwqXin http://www.zwqxin.com/ , 转载请注明
原文地址:http://www.zwqxin.com/archives/opengl/shadow-map-2.html
这里是ZwqXin关于Shadow Map阴影贴图的OpenGL实现记录的第三辑。在启动新动作之前,总结一下这些天关于Shadow Map的一些琐事,问题的存在。——ZwqXin.com 前文见:
Shadow Map阴影贴图技术之探Ⅰ
Shadow Map阴影贴图技术之探Ⅱ
1.图谈光线与视线的那些破事儿

从Nvidia的CSM paper里要来的一张图。因为我觉得这个问题还是图片说话比较好:你看图中,蓝色线内的是光源“眼中”的场景(far和near在这里无关要紧),黑色那个是视锥,蓝色物体被投影到某树上,我们看得到该影子(树在视锥内)。这当然是理想情况。仔细看看这种理想情况是怎么做出来的?灯光足够远,整个视锥在“光的视野”内。如果蓝色框框向上移动一下看怎么样?如果黑色框框向下移呢?我们能够观察到阴影的部分,永远只有光视野与相机视野的交集。
2.反锯齿的动作
既然如此,那么把光有那么远移那么远好么,最好是无限远产生平行光好么?不好。原因之前说过了,就像你人一样,你越远,看的东西越模糊,乃至形状都分不清了——光也一样,这样的影子实在糟糕。怎样取得光源距离在各方面的平衡呢?我觉得应该恰到好处地具体问题具体分析。有时候你得模拟一个照射大地的太阳,你能让它怎么近呢?(下面讲到的CSM技术是解决此类问题的。)但是一些小场景你就得合理控制了——又通常光源位置都不是说变就变的(譬如房间内的蜡烛),这时候可通过近远裁减面等等适当调节光的“视野”。对光源过远而产生的锯齿,衍生出级种着力于解决这类问题的技术(后述)。另外还有传统的反锯齿技术,譬如4X,16X这些。譬如这里我尝试按OpenGL Shading Language(橙书)13.2做的:
float lookup(float x, float y)
{
float factor = 1.0;
shadowTexcoord = shadowTexcoord + vec4(x,y,0.0,0.0) * epsilon;
float depth = shadow2DProj(shadowmap, shadowTexcoord).r;
depth = clamp(depth, 0.0, 1.0);
if(depth != 1.0)factor = 0.5;
return factor;
}
void main()
{
float mass = 0.0;
mass += lookup( 0.001, 0.001);
mass += lookup( 0.001, -0.001);
mass += lookup(-0.001, 0.001);
mass += lookup(-0.001, -0.001);
if(shadowTexcoord.x >= 0.0 && shadowTexcoord.y >= 0.0
&& shadowTexcoord.x <= 1.0 && shadowTexcoord.y <= 1.0 )
{
gl_FragColor = vec4(gl_Color.rgb* diffuse.rgb * mass*0.25, 1.0);
}
else
{
gl_FragColor = vec4(gl_Color.rgb* diffuse.rgb, 1.0);
}
float lookup(float x, float y){ float factor = 1.0; shadowTexcoord = shadowTexcoord + vec4(x,y,0.0,0.0) * epsilon; float depth = shadow2DProj(shadowmap, shadowTexcoord).r; depth = clamp(depth, 0.0, 1.0); if(depth != 1.0)factor = 0.5; return factor;}void main(){ float mass = 0.0; mass += lookup( 0.001, 0.001); mass += lookup( 0.001, -0.001); mass += lookup(-0.001, 0.001); mass += lookup(-0.001, -0.001); if(shadowTexcoord.x >= 0.0 && shadowTexcoord.y >= 0.0 && shadowTexcoord.x <= 1.0 && shadowTexcoord.y <= 1.0 ) { gl_FragColor = vec4(gl_Color.rgb* diffuse.rgb * mass*0.25, 1.0); } else { gl_FragColor = vec4(gl_Color.rgb* diffuse.rgb, 1.0); }
原理就是ping-pong模式的多次采样取均值——让阴影边界模糊。这当然比难看的锯齿好,但一般要搞高精度的效果才略显好。譬如我上面那样仅仅4次采样:

可能是PICASA的压缩,本来也没这么丑的 - - 。但是你也知道这软阴影不象软阴影,跟人眼睛得了散光看东西一样。
3.穿过透明
我曾经在探Ⅰ讲shadow map好处的时候说过它比Volume有些地方的优势很明显。其中之一就是对待透明物时的问题。其实在Shadow Volume之探系列里我是想实现的,而且初期想以为很简单,谁知道即使拜托Google大神,也没看到有什么内容是关于这个的,可见Volume对这类型的遮光物是先天不足。而Shadow Map,本来以为“接下来努力实现让光线穿过透明物产生真实的阴影吧”,谁知道就那么几分钟就搞好了 - - 。说到底,Volume认真对待每个图元,而Map,管你是人不...不,管你是什么图元模型,一律照杀....其实就是在fragment shader里做alpha test,剔除背景色。
void main()
{
vec4 alphatexcolor = tex2D(alphatex, gl_TexCoord[0].xy);
if( alphatexcolor.x < 0.05 && alphatexcolor.y < 0.05 && alphatexcolor.z < 0.05)
discard;
gl_FragColor = gl_Color * diffuse * alphatexcolor;
}
void main(){ vec4 alphatexcolor = tex2D(alphatex, gl_TexCoord[0].xy); if( alphatexcolor.x < 0.05 && alphatexcolor.y < 0.05 && alphatexcolor.z < 0.05) discard; gl_FragColor = gl_Color * diffuse * alphatexcolor;}
譬如这里是黑色背景的树,于是把接近黑色的的像素剔除,把此shader应用于画树的那部分函数,直接可得结果。怎么样,图元是矩形,阴影不是吧?
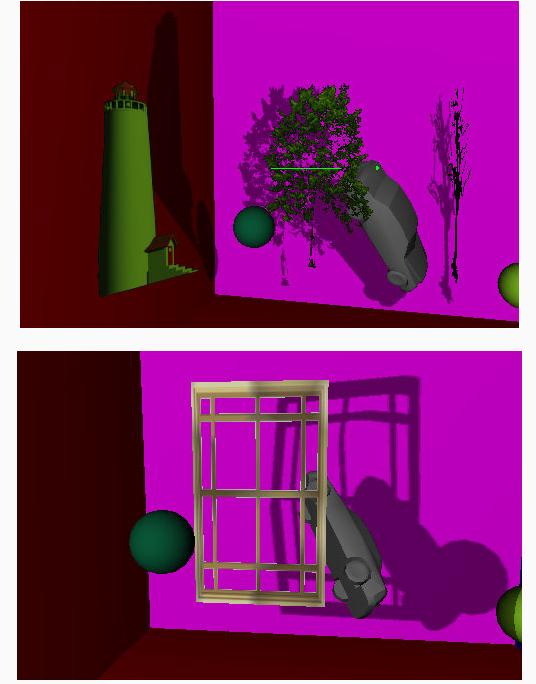
对其他背景色也是一样的。但是最好还是在photoshop里把所有图片背景色转为一样的吧(建议与清屏时那颜色一致,我用的是黑色来glClear)。另外纹理图上多少会残留一点点因颜色容差造成的“碎块”,这时候与屏幕背景色一致的话,用透明就可以消除它们了(这里我没做)。
4. Shadow Map延伸技术
1.PSM():不太了解(事实上所有的都不太了解 - -),不过大概来说,就是为了解决上面提到的“光视野”与“相机视野”的矛盾,通过另类的光源版本投影矩阵“配合”好这两个视锥(硬来,改变光路),让“眼所见即光所见”。副作用当然是光源移动的时候的不连续啦。
2.LiPSM (Light Space Perspective Shadow Map)不同于PSM之处在于它不会“硬来”,而是在光源空间“新建”一个光源视锥(平行于原光路)。这通常是比较直观的图形学解决之道:神不知鬼不觉地偷偷弄一个适合的光源视锥,原来都不影响。影子是根据这个新光源视锥来的——但是在外面,观看场景的我们只看到原来的一个光源,还有物体还有影子——自然而然地被骗了。(有点像Shadow Volume里乱走空间的光源呵呵)
3.TSM(Trapezoidal Shadow Maps )你可以看看这个网址:Anti-aliasing and Continuity with Trapezoidal Shadow Maps,该介绍的都有了,比PSM,比Bounding Box (旧的SM技术),优势从一个视频明显体现!但是......那个,看看算法:Trapezoidal Shadow Maps (TSM) - Recipe, 那个真◆视觉梯形的弄法真是.....囧。世界太可怕了TAT。极高的反锯齿性能,视觉。关键在于把光源投影矩阵替换成那个复杂扭曲的梯形(发现优化技术很多都在于对光源投影矩阵动手脚啊)。
4.CSM(Cascaded Shadow Maps)Cascaded是级联的意思。此方式与前不同,相当于给阴影做LOD。前面说过,这是针对大规模场景光照的阴影技术(太阳普照~),从另一个角度来解决锯齿:通过不同的阴影深度图。你这么理解吧,太阳光下的树的影子,你离它越近,场景应用的深度图越清晰(因为移近平行的太阳光对阴影生成影响不大,而在此距离下“截频”出来的深度图是高精的),你离它越远,当然,场景变大,物体变多,但是这时候用的深度图有必要那么精确吗?于是就换了。这样,控制得好的话,近看远看都不成问题。当然,细节问题有待探讨。

(最后用一张恶搞图结束)
下篇预告:Shadow Map阴影贴图技术之探Ⅳ [CSM]
本文来源于ZwqXin http://www.zwqxin.com/ , 转载请注明
原文地址:http://www.zwqxin.com/archives/opengl/shadow-map-3.html
这里是ZwqXin关于Shadow Map阴影贴图的OpenGL实现记录的第四辑。终于回到了这个节骨眼上,请与我一起进军时尚的Cascaded Shadow Maps(CSM)吧。——ZwqXin.com
Shadow Map阴影贴图技术之探Ⅰ
Shadow Map阴影贴图技术之探Ⅱ
Shadow Map阴影贴图技术之探Ⅲ
上篇(Ⅲ)里的最后最后,提及了几种比较有名的Shadow Map的延展技术,Cascaded Shadow Maps是其中比较近期才出现的,而且它引进了Cascade(级联,层)这个概念,与另一个颇为我们中国人骄傲的名词PSSM(Parallel-split Shadow Maps)中的Parallel-split指的是同一个概念。事实上两者的原理是基本一样的。
它先在我们的视锥上动手脚,用几个与近远平面平行的截面把视锥分成几份(Parallel-split);然后针对每一份,通过修改光源投影矩阵,使之后生成的Shadow Map中只有该份“Splited视锥”里的物体;这样,在pass1阶段就生成了几张针对不同“Splited视锥”的Shadow Maps,在渲染阶段,依据像素深度就可以判断该位置应用哪张Shadow Map了。
这样做的好处在上篇已经讲过了。在距离眼睛近的地方,应用的是分辨率高的阴影图,距离眼睛远的地方则是低分辨率。这样是符合视觉特点的,而且没有什么浪费的地方。
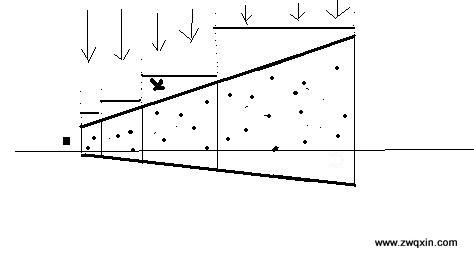
如图,假设光从视锥正上方射下来(其他方向同理),按CSM的意思,应该把光源视觉下的投影面放在图示位置(四条短的水平的线)。这里我把视锥分割成四份,因此需要对应的四张ShadowMap,与人看东西一样,视像面越靠近阴影(假设位于被投影面,图中长水平线),看到的阴影越清晰。反映在生成阴影图阶段,表现为具体caster(被光源直接照射的投射物表面)在光源投影面上占据的范围大。假设阴影图尺寸是固定的(譬如1024*1024),在第一个“Splited视锥”和第四个“Splited视锥”里的投射阴影的物体[投射物]大小也相同(其阴影在实际世界里占地面积必然也相同),则其阴影在阴影图里占的像素数会有很大差别(譬如前者占500,000个,后者可能才占5000个),这就是分辨率的差异。最后把ShdowMap帖在场景里(假设在世界空间下该种投射物的阴影应该占100,000个像素),前者就会比后者效果好很多。(一个是需要进行OverSampling,另一个就得进行UnderSampling。)所以越靠近眼睛的、越小的Splited视锥里的阴影越高“画质”,反之则越粗糙(但比起传统Shadow Map技术也许效果还好一点)——而我们正希望要眼前的事物清晰,远处的事物模糊甚至不表现出影子也可以——CSM(或者说,PSSM)做到了。
重新回头看看技术实现过程。这里有两个主要的技术点,一是“怎么分割视锥”,二是“怎么设置每个小视锥的光源投影矩阵”。
1. Cascade(Split)的准则
从上图和上分析可以看出,“Splited视锥”沿视线的长度(Zfar - Znear)应该越分越大比较合理,指数增长符合这个规律,但指数增长一般太夸张了,所以配合一个线性增长比较好。在PSSM里,这两种分法叫 logarithmic split scheme和the uniform split scheme,前者的表达式是经过科学的推导的,这部分也是CSM/PSSM最数学的部分,在GPU GEMS3里有详细的推导,或者你看PSSM推广人Fan Zhang [HKUST]那篇"Hardware-Accelerated Parallel-Split Shadow Maps." (IF YOU CAN FIND IT)也该有。它从Shadow-Map Aliasing(dp/ds,单位阴影图像素单位对应的屏幕像素)的推导开始,找出能满足使perspective aliasing(由投影缩减效应形成)在各个视锥里均匀分配的分割式。
后者只是一个线性式,但它的调和作用避免了“Splited视锥”的过小与过大,通过一个mix因子混合两式子(我在应用中默认分配logarithmic split scheme的因子是0.75,余者0.25):

// www.ZwqXin.com Cascaded Shadow Maps
void CCascadingSM::ComputeSplits(float strength, float Dis_Near, float Dis_Far)
{
float distance_scale = Dis_Far / Dis_Near;
splitfrust[0].ResightNear(Dis_Near); //开始分割
float partisionFactor = 0.0;
float lerpValue1 = 0.0, lerpValue2 = 0.0;
float SplitsZ = 0.0;
for(int i = 1; i < NumofSplits; ++i)
{
partisionFactor = i / (float)NumofSplits;
lerpValue1 = Dis_Near + partisionFactor * (Dis_Far - Dis_Near);
lerpValue2 = Dis_Near * powf(distance_scale, partisionFactor);
// 分割面的Z值. 1.005f防止前一个子视锥的远裁切面与后一个子视锥的近裁切面冲突
SplitsZ = (1-strength) * lerpValue1 + strength * lerpValue2;
splitfrust[i].ResightNear(SplitsZ * 1.002f);
splitfrust[i-1].ResightFar(SplitsZ);
}
splitfrust[NumofSplits-1].ResightFar(Dis_Far);//结束分割
}
// www.ZwqXin.com Cascaded Shadow Mapsvoid CCascadingSM::ComputeSplits(float strength, float Dis_Near, float Dis_Far){ float distance_scale = Dis_Far / Dis_Near; splitfrust[0].ResightNear(Dis_Near); //开始分割 float partisionFactor = 0.0; float lerpValue1 = 0.0, lerpValue2 = 0.0; float SplitsZ = 0.0; for(int i = 1; i < NumofSplits; ++i) { partisionFactor = i / (float)NumofSplits; lerpValue1 = Dis_Near + partisionFactor * (Dis_Far - Dis_Near); lerpValue2 = Dis_Near * powf(distance_scale, partisionFactor); // 分割面的Z值. 1.005f防止前一个子视锥的远裁切面与后一个子视锥的近裁切面冲突 SplitsZ = (1-strength) * lerpValue1 + strength * lerpValue2; splitfrust[i].ResightNear(SplitsZ * 1.002f); splitfrust[i-1].ResightFar(SplitsZ); } splitfrust[NumofSplits-1].ResightFar(Dis_Far);//结束分割}
2. Crop It !
针对每个光源投影矩阵进行的调整,在CSM/PSSM里称为Crop(这么有诗情画意噶?)。这个过程其实很好理解的,我们在照相的时候,一开始要在CCD液晶屏的画面上把焦点确定吧——Cascaded Shadow Maps技术中的光源就是照相者,光源的视像平面就是屏幕,我们是对每个“Splited视锥”都照一张相,因为照的是casters,所以可以说是照人物相片——把casters所在的“Splited视锥”(对应人物背景)在光源投影空间的中心挪移到视像平面的中心,然后进行光学变焦,使人物背景尽量充满屏幕,从而突出人物——casters,噢,不,应说是shadows。
恩,这是个具有平移和缩放的线性变换——CROP MATRIX,合适地构造它,然后乘在光源投影矩阵前面(形成新的投影矩阵),就能完成匹配投影矩阵匹配“Splited视锥”的任务。假如目前处理第i个分割视锥,生成CropMatrix[i],那么对场景坐标系的变换就是:(CropMatrix[i] * LightProjectMatrix) * LightViewMatrix * ModelMatrix * pos。也可认为(CropMatrix[i] * LightProjectMatrix)是二次投影,因为Crop Matrix实质也是个投影矩阵,而且是个名副其实的Otho正交投影矩阵。
// www.ZwqXin.com Cascaded Shadow Maps
void CCascadingSM::ApplyCropProjectMatrix(CFrustum &frust)
{
CVector3 maxFrustumCoord, minFrustumCoord;
CMatrix16 CurrentMatrix;//当前矩阵
CMatrix16 CropMatrix;//协调光源视野与视锥的Crop Matrix
//光源视图矩阵
glGetFloatv(GL_MODELVIEW_MATRIX, CurrentMatrix.mt);
//生成视锥的AABB特征向量,视锥先经CurrentMatrix变换到光源视图空间
GetFrustumAABBCoords(frust, maxFrustumCoord, minFrustumCoord, &CurrentMatrix);
//计算给Crop Matrix的调整参数
float scaleX = 2.0f/(maxFrustumCoord.x - minFrustumCoord.x);
float scaleY = 2.0f/(maxFrustumCoord.y - minFrustumCoord.y);
float offsetX = -0.5f*(maxFrustumCoord.x + minFrustumCoord.x) * scaleX;
float offsetY = -0.5f*(maxFrustumCoord.y + minFrustumCoord.y) * scaleY;
CropMatrix = CMatrix16(scaleX, 0.0f, 0.0f, 0.0f,
0.0f, scaleY, 0.0f, 0.0f,
0.0f, 0.0f, 1.0f, 0.0f,
offsetX, offsetY, 0.0f, 1.0f );
//CropProjectMatrix(光源投影矩阵 = CropMatrix*ProjectZMatrix)
glLoadIdentity();
glLoadMatrixf(CropMatrix.mt);
//以max_Z和min_Z作为远近裁切面的正投影矩阵
glOrtho(-1.0, 1.0, -1.0, 1.0, -maxFrustumCoord.z, -minFrustumCoord.z );
}
// www.ZwqXin.com Cascaded Shadow Maps void CCascadingSM::ApplyCropProjectMatrix(CFrustum &frust) { CVector3 maxFrustumCoord, minFrustumCoord; CMatrix16 CurrentMatrix;//当前矩阵 CMatrix16 CropMatrix;//协调光源视野与视锥的Crop Matrix //光源视图矩阵 glGetFloatv(GL_MODELVIEW_MATRIX, CurrentMatrix.mt); //生成视锥的AABB特征向量,视锥先经CurrentMatrix变换到光源视图空间 GetFrustumAABBCoords(frust, maxFrustumCoord, minFrustumCoord, &CurrentMatrix); //计算给Crop Matrix的调整参数 float scaleX = 2.0f/(maxFrustumCoord.x - minFrustumCoord.x); float scaleY = 2.0f/(maxFrustumCoord.y - minFrustumCoord.y); float offsetX = -0.5f*(maxFrustumCoord.x + minFrustumCoord.x) * scaleX; float offsetY = -0.5f*(maxFrustumCoord.y + minFrustumCoord.y) * scaleY; CropMatrix = CMatrix16(scaleX, 0.0f, 0.0f, 0.0f, 0.0f, scaleY, 0.0f, 0.0f, 0.0f, 0.0f, 1.0f, 0.0f, offsetX, offsetY, 0.0f, 1.0f ); //CropProjectMatrix(光源投影矩阵 = CropMatrix*ProjectZMatrix) glLoadIdentity(); glLoadMatrixf(CropMatrix.mt); //以max_Z和min_Z作为远近裁切面的正投影矩阵 glOrtho(-1.0, 1.0, -1.0, 1.0, -maxFrustumCoord.z, -minFrustumCoord.z ); }
CropMatrix简直就跟glOrtho生成的矩阵一模一样,功用也一样。只不过这里我没有对Z坐标进行变换,因为把它交给生成光源投影矩阵的glOrtho了(反而它只变换Z坐标)。前面不是说把坐标都变换到光源投影CLip空间后再提取AABB吗,为什么就到光源视图空间就比较了?因为这里是平行光的投影,所以用的是正交投影glOrtho,在glOrtho中没有对X,Y坐标进行变换(看看它的spec就知道了,-1与1为参数是不改变X,Y数值的),所以两个空间下的X,Y坐标是一致的,而CropMatrix正是只变换X,Y坐标,所以实在没必要多此一举。
但有两种情况是“需要多此一举”的。一是光源为点光源且需要透视投影;二是在光源与视锥之间还有其他caster。对第二种情况尤其值得注意。看回我在文章最上面放的自画示意图,有个打了X的地方,那里假设有只bird,那么它会否对地面产生阴影呢?——按照CSM基础理论,不会!因为CropMATRIX修改后的光源投影平面已经越过它了,已经看不见它了——我们只能看见视锥里(更准确说是视锥的AABB包围盒里)的物体所留下的阴影!解决法是把该物件bondingbox在光源视图空间下的最大Z坐标作为上述算法最后的minFrustumCoord.z,使光源投影平面恰在该位置而不再下降。这样做多了些麻烦,而且该“Splited视锥”对应的Shadow Map的分辨率会降低,物体离视锥越远,分辨率下降越严重。所以,如非必要投射那样的物体(或者部分穿出视锥之外的物体)的阴影,不必这样做:
先计算普适意义下的光源投影矩阵和视图矩阵(类似传统SM那样),用它们的积Light-ProjectView把各个小视锥变换到CLIP投影空间,用同样方法得到该空间下的包围盒(特征向量maxFrustumCoord, minFrustumCoord),这里继续计算的Crop矩阵就需要用到Z值了,因为我们要修改其中的minFrustumCoord.z。让它等于-1——OPENGL在CLIP投影空间的最小坐标值。没错,即使该物件在光源正体位置之上,也把它计算入要投影的物件集(casters)里(况且平行光源本来该是无限远而不是在那个虚拟位置上的)。最后依然是:CropMatrix[i] *( LightProjectMatrix * LightViewMatrix) * ModelMatrix * pos。
// www.ZwqXin.com Cascaded Shadow Maps
CVector3 maxFrustumCoord, minFrustumCoord;
//.....
GetFrustumAABBCoords(frust, maxFrustumCoord, minFrustumCoord, &CurrentMV);
minFrustumCoord.z = -1.0f;
//计算给Crop Matrix的调整参数
float scaleX = 2.0f/(maxFrustumCoord.x - minFrustumCoord.x);
float scaleY = 2.0f/(maxFrustumCoord.y - minFrustumCoord.y);
float scaleZ = 2.0f / (maxFrustumCoord.z - minFrustumCoord.z);
float offsetX = -0.5f*(maxFrustumCoord.x + minFrustumCoord.x) * scaleX;
float offsetY = -0.5f*(maxFrustumCoord.y + minFrustumCoord.y) * scaleY;
float offsetZ = -0.5f*(maxFrustumCoord.z + minFrustumCoord.z) * scaleZ;
CropMatrix = CMatrix16(scaleX, 0.0f, 0.0f, 0.0f,
0.0f, scaleY, 0.0f, 0.0f,
0.0f, 0.0f, scaleZ, 0.0f,
offsetX, offsetY, 0.0f, 1.0f );
//....
// www.ZwqXin.com Cascaded Shadow Maps CVector3 maxFrustumCoord, minFrustumCoord; //..... GetFrustumAABBCoords(frust, maxFrustumCoord, minFrustumCoord, &CurrentMV); minFrustumCoord.z = -1.0f; //计算给Crop Matrix的调整参数 float scaleX = 2.0f/(maxFrustumCoord.x - minFrustumCoord.x); float scaleY = 2.0f/(maxFrustumCoord.y - minFrustumCoord.y); float scaleZ = 2.0f / (maxFrustumCoord.z - minFrustumCoord.z); float offsetX = -0.5f*(maxFrustumCoord.x + minFrustumCoord.x) * scaleX; float offsetY = -0.5f*(maxFrustumCoord.y + minFrustumCoord.y) * scaleY; float offsetZ = -0.5f*(maxFrustumCoord.z + minFrustumCoord.z) * scaleZ; CropMatrix = CMatrix16(scaleX, 0.0f, 0.0f, 0.0f, 0.0f, scaleY, 0.0f, 0.0f, 0.0f, 0.0f, scaleZ, 0.0f, offsetX, offsetY, 0.0f, 1.0f ); //....
3. Cast 阴影
通过上面矩阵配合(0,1)映射矩阵之类的生成shadow maps后,这就来到第二PASS了,它与传统Shadow Map(Shadow Map阴影贴图技术之探Ⅰ)一样,只是根据像素深度决定用哪张而已。注意,把视锥分割的是近/远平面,其值是距视点的距离,定义于视图空间——把它变换到眼睛的屏幕CLIP空间,就能在shader里“分割”像素深度,把像素都分到SplitNum个区域里(应用中我取了4个)。好了,接下来你知道怎么用if-else来Cast 阴影图了吧。
// www.ZwqXin.com Cascaded Shadow Maps
//fragment shader中获取当前像素阴影状态:
//shadow_color [阴影factor], 还是1.0[表明不贡献阴影之factor]
const float shadow_color = 0.3;
const float depth_error = 0.005;
//上面提到的那几个分割值,藏在xyz通道了
uniform vec3 frustum_far;
uniform sampler2DArray shadowmap;
vec4 shadeFact()
{
int index = 3;
//决定cascade,应用的shadowMap index
//gl_FragCoord(当前pixel的x,y窗口坐标,z分量为深度)
if(gl_FragCoord.z < frustum_far.x)
{
index = 0;
}
else if(gl_FragCoord.z < frustum_far.y)
{
index = 1;
}
else if(gl_FragCoord.z < frustum_far.z)
{
index = 2;
}
//转换像素位置参量pos, 到光源视觉(Croped)-纹理空间
vec4 shadowTexcoord = gl_TextureMatrix[index] * pos;
//对纹理投影,变换到纹理空间的场景坐标总作为TEXCOORD,这时就得自行为之“透视相除”了
//小声:对正交投影其实是不必的。。。
if(shadowTexcoord.w != 1.0)
{
shadowTexcoord = shadowTexcoord / shadowTexcoord.w;
}
//映射到(0~1)以进行纹理检索
shadowTexcoord = 0.5 * shadowTexcoord + 0.5;
//本像素的位置在当前空间(光源视觉(Croped)-纹理空间)的实际深度
float realDepth = shadowTexcoord.z;
//Texture Array 中以z分量选择纹理Layer(Shadow Map No.i)
shadowTexcoord.z = float(index);
//检索出Shadow Map中对应位置(x,y)的深度值
float depth = texture2DArray(shadowmap, shadowTexcoord.xyz).x;
//当 depth >= realDepth, 该位置所属caster 或 no-shadow领域, 输出阴影分量1.0[无阴影]
//当 depth < realDepth, 该位置所属shadowed领域 , 输出阴影分量0.0[有阴影]
float diff = depth - realDepth;
//为了精度问题,如果差值diff是个很小很小的负量,把该量设定为1.0
//当diff > -0.005(根据应用调节), 认为depth - realDepth >= 0.0[无阴影]
diff = diff / depth_error + 1.0;
return vec4(diff < 0.0 ? shadow_color : 1.0) ;
}
// www.ZwqXin.com Cascaded Shadow Maps//fragment shader中获取当前像素阴影状态://shadow_color [阴影factor], 还是1.0[表明不贡献阴影之factor]const float shadow_color = 0.3;const float depth_error = 0.005;//上面提到的那几个分割值,藏在xyz通道了uniform vec3 frustum_far; uniform sampler2DArray shadowmap;vec4 shadeFact(){ int index = 3; //决定cascade,应用的shadowMap index //gl_FragCoord(当前pixel的x,y窗口坐标,z分量为深度) if(gl_FragCoord.z < frustum_far.x) { index = 0; } else if(gl_FragCoord.z < frustum_far.y) { index = 1; } else if(gl_FragCoord.z < frustum_far.z) { index = 2; } //转换像素位置参量pos, 到光源视觉(Croped)-纹理空间 vec4 shadowTexcoord = gl_TextureMatrix[index] * pos; //对纹理投影,变换到纹理空间的场景坐标总作为TEXCOORD,这时就得自行为之“透视相除”了 //小声:对正交投影其实是不必的。。。 if(shadowTexcoord.w != 1.0) { shadowTexcoord = shadowTexcoord / shadowTexcoord.w; } //映射到(0~1)以进行纹理检索 shadowTexcoord = 0.5 * shadowTexcoord + 0.5; //本像素的位置在当前空间(光源视觉(Croped)-纹理空间)的实际深度 float realDepth = shadowTexcoord.z; //Texture Array 中以z分量选择纹理Layer(Shadow Map No.i) shadowTexcoord.z = float(index); //检索出Shadow Map中对应位置(x,y)的深度值 float depth = texture2DArray(shadowmap, shadowTexcoord.xyz).x; //当 depth >= realDepth, 该位置所属caster 或 no-shadow领域, 输出阴影分量1.0[无阴影] //当 depth < realDepth, 该位置所属shadowed领域 , 输出阴影分量0.0[有阴影] float diff = depth - realDepth; //为了精度问题,如果差值diff是个很小很小的负量,把该量设定为1.0 //当diff > -0.005(根据应用调节), 认为depth - realDepth >= 0.0[无阴影] diff = diff / depth_error + 1.0; return vec4(diff < 0.0 ? shadow_color : 1.0) ;}
最后是放出演示DEMO了吧:请看 [Shadow Map Demo2]

在该日志将展示DEMO并浅谈一下CSM一些小细节的地方,包括caster-receiver-splitedFrustum组合生成的SCREEN DEPENDENT的crop矩阵。最后是这段时间个人学习Shadow技法的小小总结。
本文来源于ZwqXin http://www.zwqxin.com/ , 转载请注明
原文地址:http://www.zwqxin.com/archives/opengl/shadow-map-4.html
再分享一下我老师大神的人工智能教程吧。零基础!通俗易懂!风趣幽默!还带黄段子!希望你也加入到我们人工智能的队伍中来!https://www.cnblogs.com/captainbed
标签:cli 透视投影 影子 pass 了解 存在 line 分辨率 演示
原文地址:https://www.cnblogs.com/skiwnchiwns/p/10163779.html