标签:type l数据库 nic nand proc efi comm import fine
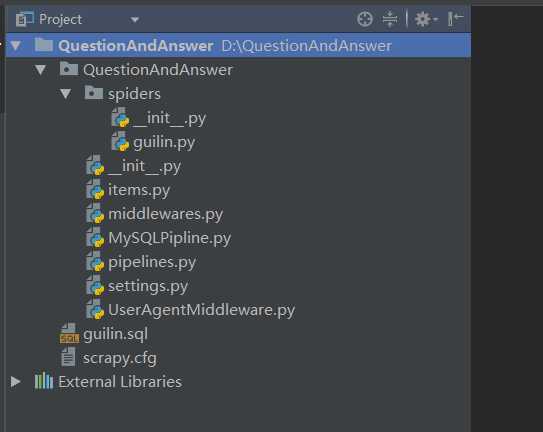
guilin.sql:
CREATE TABLE `guilin_ask` (
`id` INT(11) NOT NULL AUTO_INCREMENT COMMENT ‘主键‘,
`question` VARCHAR(255) DEFAULT NULL COMMENT ‘问题的标题‘,
`full_question` VARCHAR(255) DEFAULT NULL COMMENT ‘问题的详情‘,
`keyword` VARCHAR(255) DEFAULT NULL COMMENT ‘关键字‘,
`ask_time` VARCHAR(255) DEFAULT NULL COMMENT ‘提问时间‘,
`accept_answer` TEXT COMMENT ‘提问者采纳的答案‘,
`recommend_answer` TEXT COMMENT ‘旅游推荐的答案‘,
`agree_answer` TEXT COMMENT ‘赞同数最高的答案‘,
PRIMARY KEY (`id`),
UNIQUE KEY `question` (`question`)
) ENGINE=INNODB DEFAULT CHARSET=utf8 COMMENT=‘桂林_问答表‘
guilin.py:
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from QuestionAndAnswer.items import QuestionandanswerItem
from pyquery import PyQuery as pq
class GuilinSpider(scrapy.Spider):
name = ‘guilin‘
allowed_domains = [‘you.ctrip.com‘]
def start_requests(self):
# 重写start_requests方法
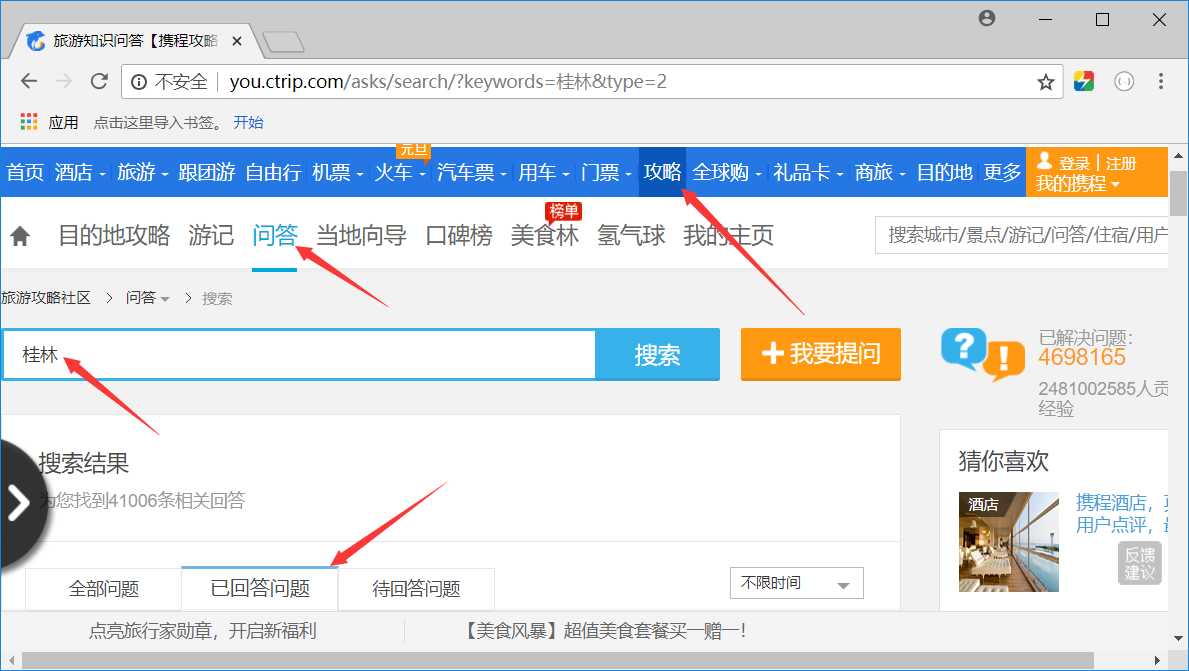
ctrip_url = "http://you.ctrip.com/asks/search/?keywords=%e6%a1%82%e6%9e%97&type=2"
# 携程~攻略~问答~桂林~已回答问题
yield Request(ctrip_url, callback=self.list_page)
def list_page(self, response):
result = pq(response.text)
# 调用pyquery.PyQuery
result_list = result(".cf")
# 问题列表
question_urls = []
# 问题链接列表
for ask_url in result_list.items():
question_urls.append(ask_url.attr("href"))
while None in question_urls:
question_urls.remove(None)
# 去除None
for url in question_urls:
yield response.follow(url, callback=self.detail_page)
result.make_links_absolute(base_url="http://you.ctrip.com/")
# 把相对路径转换成绝对路径
next_link = result(".nextpage")
next_url = next_link.attr("href")
# 下一页
if next_url is not None:
# 如果下一页不为空
yield scrapy.Request(next_url, callback=self.list_page)
def detail_page(self, response):
detail = pq(response.text)
question_frame = detail(".detailmain")
# 问答框
for i_item in question_frame.items():
ask = QuestionandanswerItem()
ask["question"] = i_item(".ask_title").text()
ask["full_question"] = i_item("#host_asktext").text()
ask["keyword"] = i_item(".asktag_oneline.cf").text()
ask["ask_time"] = i_item(".ask_time").text().strip("发表于")
ask["accept_answer"] = i_item(".bestanswer_con > div > p.answer_text").text()
ask["recommend_answer"] = i_item(".youyouanswer_con > div > p.answer_text").text()
ask["agree_answer"] = i_item("#replyboxid > ul > li:nth-child(1) > div > p.answer_text").text()
yield ask
items.py:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class QuestionandanswerItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
question = scrapy.Field()
# 问题的标题
full_question = scrapy.Field()
# 问题的详情
keyword = scrapy.Field()
# 关键字
ask_time = scrapy.Field()
# 提问时间
accept_answer = scrapy.Field()
# 提问者采纳的答案
recommend_answer = scrapy.Field()
# 旅游推荐的答案
agree_answer = scrapy.Field()
# 赞同数最高的答案
MySQLPipline.py:
from pymysql import connect
class MySQLPipeline(object):
def __init__(self):
self.connect = connect(
host=‘192.168.1.108‘,
port=3306,
db=‘scrapy‘,
user=‘root‘,
passwd=‘Abcdef@123456‘,
charset=‘utf8‘,
use_unicode=True)
# MySQL数据库
self.cursor = self.connect.cursor()
# 使用cursor()方法获取操作游标
def process_item(self, item, spider):
self.cursor.execute(
"""select * from guilin_ask WHERE question = %s""",
item[‘question‘])
# 是否有重复问题
repetition = self.cursor.fetchone()
if repetition:
pass
# 丢弃
else:
self.cursor.execute(
"""insert into guilin_ask(
question, full_question, keyword, ask_time, accept_answer, recommend_answer, agree_answer)
VALUE (%s, %s, %s, %s, %s, %s, %s)""",
(item[‘question‘],
item[‘full_question‘],
item[‘keyword‘],
item[‘ask_time‘],
item[‘accept_answer‘],
item[‘recommend_answer‘],
item[‘agree_answer‘]
))
# 执行sql语句,item里面定义的字段和表字段一一对应
self.connect.commit()
# 提交
return item
# 返回item
def close_spider(self, spider):
self.cursor.close()
# 关闭游标
self.connect.close()
# 关闭数据库连接
标签:type l数据库 nic nand proc efi comm import fine
原文地址:https://www.cnblogs.com/yjlch1016/p/10166481.html