标签:headers install verify 定义 测试 分布式 cti locust __name__
Locust是一款易于使用的分布式用户负载测试工具。它用于对网站(或其他系统)进行负载测试,并确定系统可以处理多少并发用户。
这个想法是,在测试期间,一群蝗虫(Locust)会攻击你的网站。您定义了每个蝗虫Locust(或测试用户)的行为,并且实时地从Web UI监视群集过程。这将有助于您在让真正的用户进入之前进行测试并识别代码中的瓶颈。
Locust完全基于事件,因此可以在一台计算机上支持数千个并发用户。与许多其他基于事件的应用程序相比,它不使用回调。相反,它通过协程(gevent)机制使用轻量级过程。每个蝗虫蜂拥到你的网站实际上是在自己的进程内运行(或者是greenlet,这是正确的)。这允许您在Py??thon中编写非常富有表现力的场景,而不会使代码复杂化。
** gevent是第三方库,通过greenlet实现协程。greenlet是python的并行处理的一个库。 python 有一个非常有名的库叫做 stackless ,用来做并发处理, 主要是弄了个叫做tasklet的微线程的东西, 而greenlet 跟stackless的最大区别是greenlet需要你自己来处理线程切换, 就是说,你需要自己指定现在执行哪个greenlet再执行哪个greenlet。**
Locust支持Python 2.7, 3.4, 3.5, and 3.6的版本,小编的环境是python3.6直接用pip安装就行 pip install locustio
报错
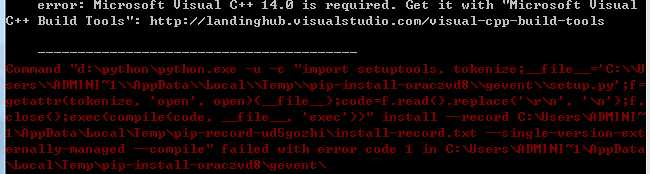
下载安装Microsoft visual c++14.0  ,安装完成后,重新安装locust
,安装完成后,重新安装locust
locust里面请求是基于requests的,每个方法请求和requests差不多,请求参数、方法、响应对象和requests一样的使用,之前学过requests库的,这里就非常简单了
# 保存为demo.py
# coding:utf-8
from locust import HttpLocust,TaskSet,task
class BlogDemo(TaskSet):
‘‘‘用户行为:打开我的博客首页demo‘‘‘
@task(1)
def open_blog(self):
# 定义requests的请求头
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}
r = self.client.get("/yoyoketang", headers=header, verify=False)
print(r.status_code)
assert r.status_code == 200
class websitUser(HttpLocust):
task_set = BlogDemo
min_wait = 3000 # 单位毫秒
max_wait = 6000 # 单位毫秒
if __name__ == "__main__":
import os
os.system("locust -f demo.py --host=https://www.cnblogs.com")代码注解:
新建一个类BlogDemo(TaskSet),继承TaskSet,该类下面写一些准备请求的行为(访问的接口)
里面的self.client调用get和post方法,跟requests是一样的
@task装饰该方法表示为用户行为。括号里面参数表示该行为挑选执行的权重,数值越大,执行频率越高,不设置默认是1
WebsiteUser()类用于设置性能测试。
task_set :指向一个定义了的用户行为类。
min_wait :用户执行任务之间等待时间的下界,单位:毫秒。
max_wait :用户执行任务之间等待时间的上界,单位:毫秒。
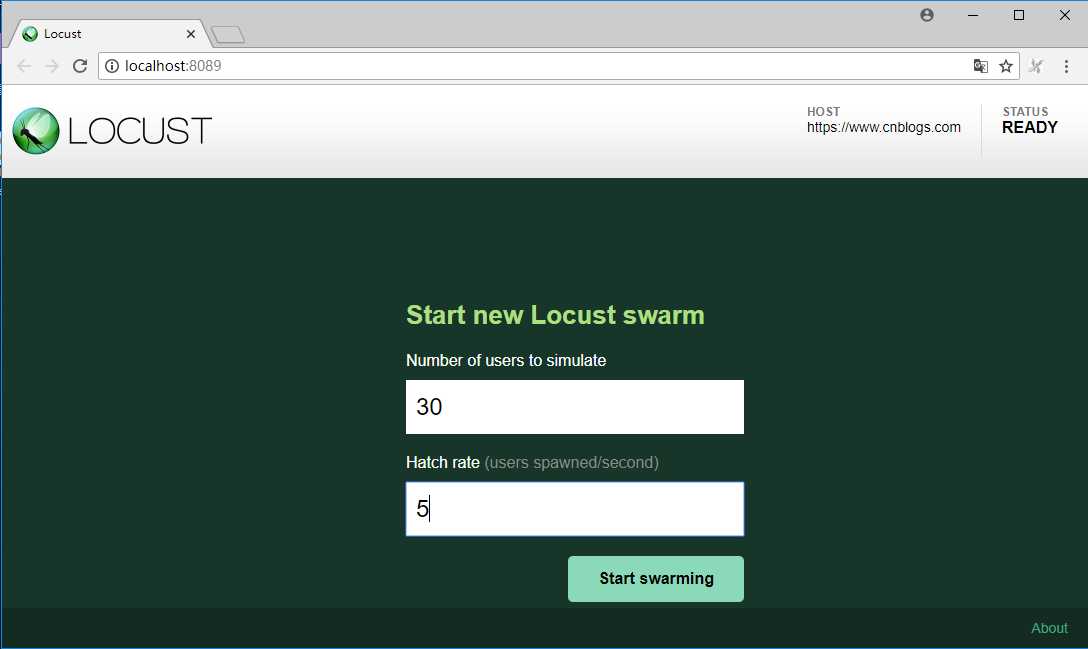
启动locust可以直接在pycharm里面执行上面的代码,运行后编辑器出现两行
[2018-09-12 23:23:57,500] DESKTOP-HJ487C8/INFO/locust.main: Starting web monitor at *:8089
[2018-09-12 23:23:57,500] DESKTOP-HJ487C8/INFO/locust.main: Starting Locust 0.9.0
也可以通过cmd执行
$ locust -f demo.py --host=https://www.cnblogs.com
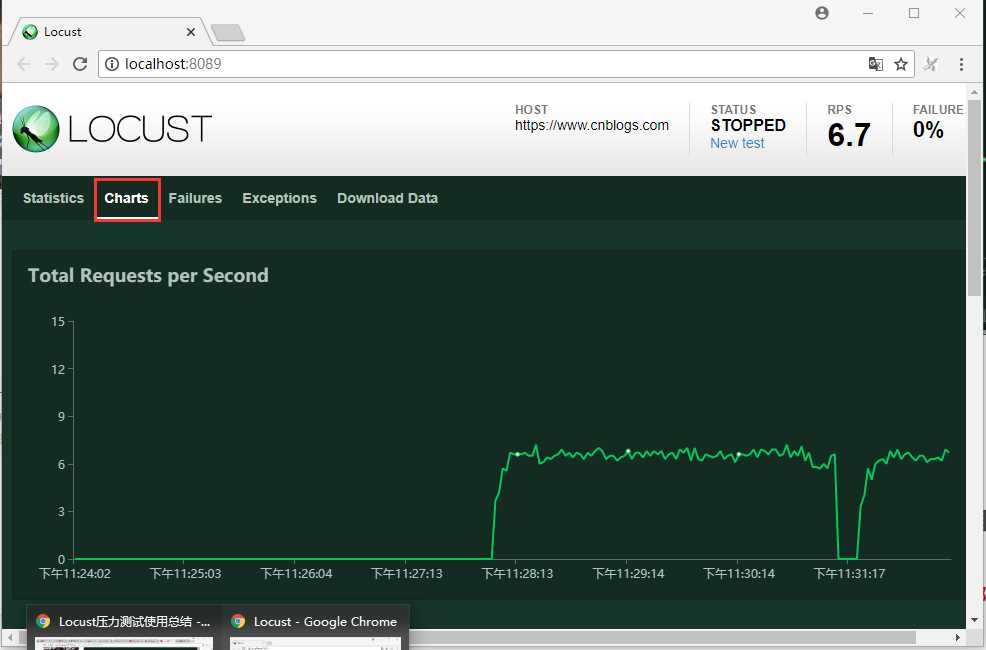
三个图标分别是
有很多网站不登录的话,是无法访问到里面的页面的,这就需要先登录了
实现场景:先登录(只登录一次),然后访问页面->我的地盘页->产品页->项目页
下面是一个简单的locustfile.py的简单示例:
from locust import HttpLocust, TaskSet
def login(l):
l.client.post("/login", {"username":"ellen_key", "password":"education"})
def logout(l):
l.client.post("/logout", {"username":"ellen_key", "password":"education"})
def index(l):
l.client.get("/")
def profile(l):
l.client.get("/profile")
class UserBehavior(TaskSet):
tasks = {index: 2, profile: 1}
def on_start(self):
login(self)
def on_stop(self):
logout(self)
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 5000
max_wait = 9000这里我们定义了许多Locust任务,它们是带有一个参数(Locust类实例)的普通Python callables 。这些任务收集在tasks属性的TaskSet类下 。然后我们有一个代表用户的 类,我们在其中定义模拟用户在执行任务之间应该等待多长时间,以及哪个 类应该定义用户的“行为”。 类可以继承HttpLocust、TaskSet、TaskSet
HttpLocust类从继承 Locust的类,并把它添加一个客户端属性,它是的一个实例 HttpSession,可用于使HTTP请求。
另一种我们可以声明任务的方法,通常是更方便,就是使用 @task装饰器。以下代码与上述代码相同:
from locust import HttpLocust, TaskSet, task
class UserBehavior(TaskSet):
def on_start(self):
""" on_start is called when a Locust start before any task is scheduled """
self.login()
def on_stop(self):
""" on_stop is called when the TaskSet is stopping """
self.logout()
def login(self):
self.client.post("/login", {"username":"ellen_key", "password":"education"})
def logout(self):
self.client.post("/logout", {"username":"ellen_key", "password":"education"})
@task(2)
def index(self):
self.client.get("/")
@task(1)
def profile(self):
self.client.get("/profile")
class WebsiteUser(HttpLocust):
task_set = UserBehavior
min_wait = 5000
max_wait = 9000在Locust类(以及HttpLocust 因为它是一个子类),也可以让一个在指定最小和最大等待时间毫秒,每个模拟用户之间的任务执行(min_wait和MAX_WAIT)以及其他用户的行为。默认情况下,时间是在min_wait和max_wait之间统一随机选择的,但是可以通过将wait_function设置为任意函数来使用任何用户定义的时间分布。例如,对于指数分布的等待时间平均为1秒:
import random
class WebsiteUser(HttpLocust):
task_set = UserBehaviour
wait_function = lambda self: random.expovariate(1)*1000
标签:headers install verify 定义 测试 分布式 cti locust __name__
原文地址:https://www.cnblogs.com/youtiaoge/p/10168302.html