标签:ima 集中 子集 控制 求和 limits 之间 ilo com
集成学习通过将多个学习器进行结合,常可获得比单一学习器显著优越的泛化性能。
要获得好的集成,个体学习器应“好而不同”,即个体学习器要有一定的准确性,即学习器不能太坏,并且要有多样性,即学习器间具有差异。

接下来介绍两种集成方式,同时生成的并行化方法,以及串行的序列化方法。
Bagging是一种并行式的集成学习方法,即基学习器的训练之间没有前后顺序可以同时进行,使用“有放回”采样的方式选取训练集,对于包含n个样本的训练集,进行n次有放回的随机采样操作,从而得到m个样本的采样集,这样训练集中有接近36.8%的样本没有被采到。按照相同的方式重复进行,我们就可以采集到T个包含n个样本的数据集,从而训练出T个基学习器,最终对这T个基学习器的输出进行结合。
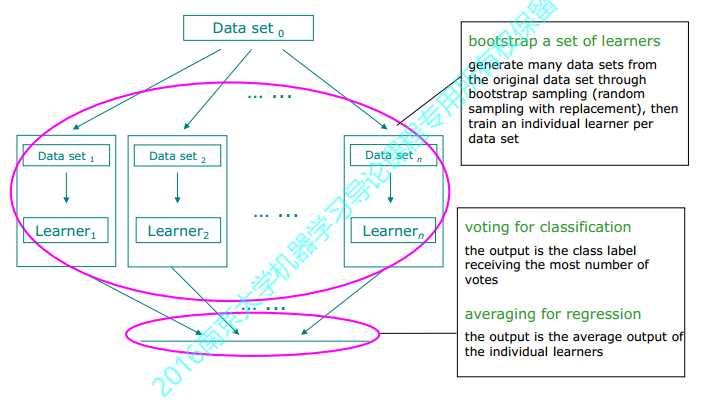
随机森林(Random Forest)是Bagging的一个拓展体,它在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。具体来说,传统决策树在选择划分属性时是当前结点的属性集合d中选择一个最优属性;而在RF中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分。这里的参数k控制了随机性的引入程度:若令k=d,则基决策树的构建与传统决策树相同;若k=1,则是随机选择一个属性用于划分;一般情况下,推荐值k=log2d。
随机森林简单、容易实现、计算开销小,令人惊奇的是, 它在很多现实任务中展现出强大的性能,被誉为"代表集成学习 技术水平的方法"可以看出,随机森林对 Bagging 只做了小改动,但是与 Bagging中基学习器的"多样性"仅通过样本扰动(通过对初始训练集采样)而来不同,随机森林中基学习器的多样性不仅来自样本扰动,还来自属性扰动,这就使得最终集成的泛化性能可通过个体学习器之间差异度的增加而进一步提升。
Boosting的基本思想是先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练,样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注,尽可能纠正这些错误,一直向下串行直至产生需要的T个基学习器,Boosting最终对这T个学习器进行加权结合。
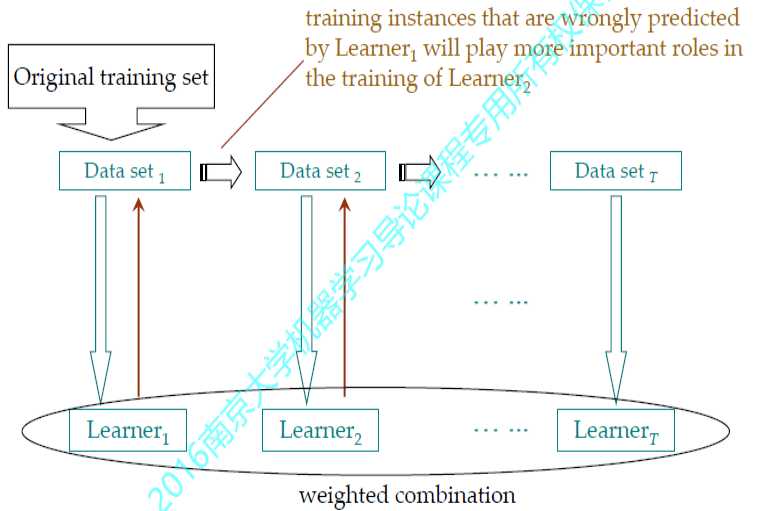
Adaboost算法
对每一个学习器$h_{m}$,针对训练集$D_{m}$
计算错误率$\varepsilon = \frac{{未正确分类的样本数目}}{{所有样本数目}}$
计算权重$\alpha_m = \frac{1}{2}\ln \left( {\frac{{1 - \varepsilon }}{\varepsilon }} \right)$
调整$D_{m}$中的每一个样本$D_i^{m}$的权重为$D_i^{m+1}$,给下一个学习器$h_{m+1}$使用:
样本被正确分类的权重为,$D_i^{m + 1} = \frac{{D_i^m{e^{ - \alpha }}}}{{Sum(D)}}$
样本被错误分类的权重为,$D_i^{m + 1} = \frac{{D_i^m{e^{ \alpha }}}}{{Sum(D)}}$
最终学习器集成为m个学习器的加权求和$H(x) = \sum\limits_{m = 1}^M {{\alpha _m}{h_m}(x)} $
标签:ima 集中 子集 控制 求和 limits 之间 ilo com
原文地址:https://www.cnblogs.com/yijuncheng/p/10171130.html