标签:资料 开始学习 官方 兴趣 输入 运算 zookeeper 时间 交流
一、大数据是什么?大数据,big data,《大数据》一书对大数据这么定义,大数据是指不能用随机分析法(抽样调查)这样捷径,而采用所有数据进行分析处理。
这句话至少传递两种信息:
1、大数据是海量的数据
2、大数据处理无捷径,对分析处理技术提出了更高的要求
欢迎加入大数据交流群:658558542 一起吹水交流学习
二、大数据的处理流程
下图是数据处理流程: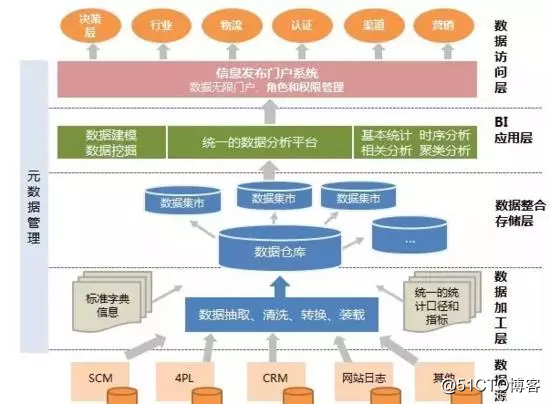
欢迎加入大数据交流群:658558542 一起吹水交流学习
1、底层是数以千亿计的数据源,数据源可以是SCM(供应链数据),4PL(物流数据),CRM(客户数据),网站日志以及其他的数据
2、第二层是数据加工层,数据工程师对数据源按照标准的统计口径和指标对数据进行抽取、清洗、转化、装载(整个过程简称ELT)
3、第三层是数据仓库,加工后的数据流入数据仓库,进行整合和存储,形成一个又一个数据集市。
数据集市,指分类存储数据的集合,即按照不同部门或用户的需求存储数据。
4、第四层是BI(商业智能),按照业务需求,对数据进行分析建模、挖掘、运算,输出统一的数据分析平台
5、第五层是数据访问层,对不同的需求方开放不同的数据角色和权限,以数据驱动业务。
大数据的量级,决定了大数据处理及应用的难度,需要利用特定的技术工具去处理大数据。
欢迎加入大数据交流群:658558542 一起吹水交流学习
三、大数据处理技术
以最常使用的Hadoop为例:
Hadoop是Apache公司开发的一个开源框架,它允许在整个集群使用简单编程模型计算机的分布式环境存储并处理大数据。
集群是指,2台或2台以上服务器构建节点,提供数据服务。单台服务器,无法处理海量的大数据。服务器越多,集群的威力越大。
Hadoop类似于一个数据生态圈,不同的模块各司其职。下图是Hadoop官网的生态图。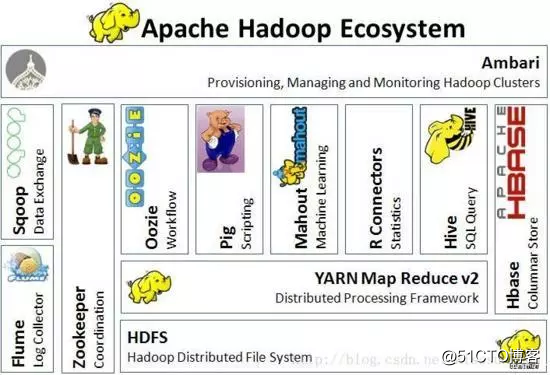
欢迎加入大数据交流群:658558542 一起吹水交流学习
Hadoop的LOGO是一只灵活的大象。关于LOGO的来源,网上众说纷纭,有人说,是因为大象象征庞然大物,指代大数据,Hadoop让大数据变得灵活。而官方盖章,LOGO来源于创始人Doug Cutting的孩子曾为一个大象玩具取名hadoop。
从上图可以看出,Hadoop的核心是HDFS,YARN和Map Reduce,下面和大家讲一讲,几个主要模块的含义和功能。
1、HDFS(分布式文件存储系统)
数据以块的形式,分布在集群的不同节点。在使用HDFS时,无需关心数据是存储在哪个节点上、或者是从哪个节点从获取的,只需像使用本地文件系统一样管理和存储文件系统中的数据。
2、Map Reduce(分布式计算框架)
分布式计算框架将复杂的数据集分发给不同的节点去操作,每个节点会周期性的返回它所完成的工作和最新的状态。大家可以结合下图理解Map Reduce原理: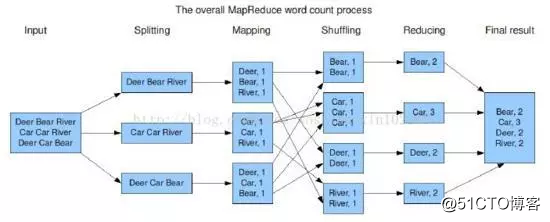
欢迎加入大数据交流群:658558542 一起吹水交流学习
计算机要对输入的单词进行计数:
如果采用集中式计算方式,我们要先算出一个单词如Deer出现了多少次,再算另一个单词出现了多少次,直到所有单词统计完毕,将浪费大量的时间和资源。
如果采用分布式计算方式,计算将变得高效。我们将数据随机分配给三个节点,由节点去分别统计各自处理的数据中单词出现的次数,再将相同的单词进行聚合,输出最后的结果。
3、YARN(资源调度器)
相当于电脑的任务管理器,对资源进行管理和调度。
4、HBASE(分布式数据库)
HBase是非关系型数据库(Nosql),在某些业务场景下,数据存储查询在Hbase的使用效率更高。
关于关系型数据库和菲关系型数据库的区别,会在以后的文章进行详述。
5、HIVE(数据仓库)
HIVE是基于Hadoop的一个数据仓库工具,可以用SQL的语言转化成Map Reduce任务对hdfs数据的查询分析。HIVE的好处在于,使用者无需写Map Reduce任务,只需要掌握SQL即可完成查询分析工作。
6、 Spark(大数据计算引擎)
Spark是专为大规模数据处理而设计的快速通用的计算引擎
7、Mahout(机器学习挖掘库)
Mahout是一个可扩展的机器学习和数据挖掘库
8、Sqoop
Sqoop可以将关系型数据库导入Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中
除上述模块外,Hadoop还有Zookeeper、Chukwa等多种模块,因为是开源的,所以未来还有出现更多更高效的模块,大家感兴趣可以上网了解。
通过Hadoop强大的生态圈,完成大数据处理流程。
在不久的将来,多智时代一定会彻底走入我们的生活,有兴趣入行未来前沿产业的朋友,可以留心多智时代,及时获取人工智能、大数据、云计算和物联网的前沿资讯和基础知识,让我们一起携手,引领人工智能的未来!
为了帮助大家让学习变得轻松、高效,给大家免费分享一大批资料,帮助大家在成为大数据工程师,乃至架构师的路上披荆斩棘。在这里给大家推荐一个大数据学习交流圈:658558542 欢迎大家进×××流讨论,学习交流,共同进步。
当真正开始学习的时候难免不知道从哪入手,导致效率低下影响继续学习的信心。
但最重要的是不知道哪些技术需要重点掌握,学习时频繁踩坑,最终浪费大量时间,所以有有效资源还是很有必要的。
最后祝福所有遇到瓶疾且不知道怎么办的大数据程序员们,祝福大家在往后的工作与面试中一切顺利。
标签:资料 开始学习 官方 兴趣 输入 运算 zookeeper 时间 交流
原文地址:http://blog.51cto.com/14145734/2334760