标签:void 控制 操作 介绍 oid 行存储 read 迁移 反序列化
一、简介
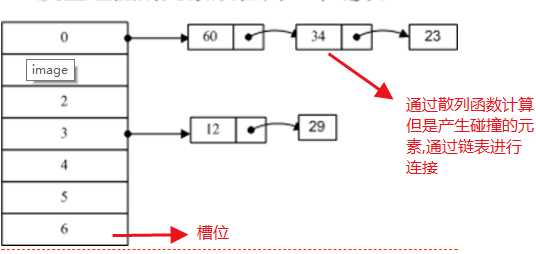
Redis中的Hash字典相当于C#中的Hashtable,是一种无序字典,内存存储了很对的键值对,实现上和Hashtable一样,都是"数组+链表"二维结构,都是对关键字(键值)进行散列操作,讲关键字散列到Hashtable中的某一个槽位中去,这个过程中如果发生了碰撞,散列函数可能将不同的关键字散列到Hashtable中的同一个槽位中去,通过"链表的方式"进行连接。
后续可能会写一个分类的关于C#中常用算法的文章,但这里不想介绍太多.
不同的是.Redis中Hash(字典的值)只能是字符串,C#中为Hashtable为object

另外关于Hashtable和List等类型,如果你阅读源码,当它们的实际容量达到初始设置的时候,一般都会创建一个新的对象,list中的原先的两倍,然后将原先的元素复制到新的对象中,这个过程如果里面的元素超级多,那么这个开销非常大,Hashtable也是如此,Hashtable中的这个过程专业术语叫rehash,而Redis为了避免这个开销,采用了"渐近式的"rhash操作,"渐进"式rehash操作会在rehash的同时,保留新旧两个hash结构,查询时会同时查询这两个hash对象,接受在后续的定时任务中循序渐进的将旧hash的内容一点点的迁移到新的hash对象中去.当迁移完成,原先的hash结构会被弃用.对应的内存会被回收.
二、Hash(字典)的用途
hash结构可以用来存储用户信息,当然字符串也可以,但是他和字符串的区别如下:
(1)、如果使用字符串存储,我们需要以用户Id为键,然后将用户所有的信息序列化成字符串存到Redis中,如果用户的信息很多,且如果有些业务我们只需要用户的部分信息,那我们不得不将用户所有的信息取过来,然后反序列化,将业务需要的数据传递过去,这个过程,Redis和客户端的网络请求流量很客观,当然访问量少不需要考虑这些问题,但是如果访问量大的话,你懂的
(2)、如果使用Hash结构存储,那么我们可以用户结构的单个字段进行存储,当我们需要用户信息时,就可以进行部分读取,节省网络流量.
(3)、当然Hash也有缺点,他的存储消耗要高于字符串.
三、实战
centeros7中启动Redis

还是接着前面随笔的代码进行扩展.
C#控制台:
给RedisClient.cs文件扩展如下几个方法:
/// <summary> /// 异步可批量设置Hash(字典) /// </summary> /// <param name="key"></param> /// <param name="entries"></param> /// <returns></returns> public static async Task HashSetAsync(RedisKey key, HashEntry[] entries) { var db = GetDatabase(); await db.HashSetAsync(key, entries); } /// <summary> /// 异步根据键获取值 /// </summary> /// <param name="key"></param> /// <returns></returns> public static async Task<RedisValue[]> HashValuesAsync(RedisKey key) { var db = GetDatabase(); return await db.HashValuesAsync(key); } /// <summary> /// 异步根据键获取键值对 /// </summary> /// <param name="key"></param> /// <returns></returns> public static async Task<HashEntry[]> HashGetAllAsync(RedisKey key) { var db = GetDatabase(); return await db.HashGetAllAsync(key); } /// <summary> /// 根据键和和键值对的键获取某个对应的值 /// </summary> /// <param name="key"></param> /// <param name="field"></param> /// <returns></returns> public static async Task<RedisValue> HashGetAsync(RedisKey key,RedisValue field) { var db = GetDatabase(); return await db.HashGetAsync(key, field); }
注:这里还提供了删除Hash集合和给对应的Filed加1的操作,但是个人觉得应用场景不多,一般都是每天跑后台服务持久化到数据库中对数据库进行操作,比较好,所以这里就没有扩展.
Program.cs代码如下:
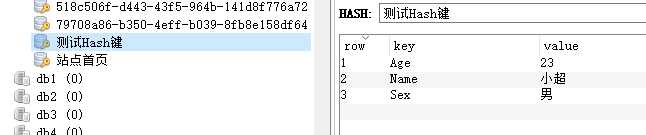
class Program { static Program() { //链式配置Redis AppConfiguration.Current.ConfigureRedis<RedisConfig>(); } static void Main(string[] args) { StringSetGetAsync(); Console.ReadKey(); } static async void StringSetGetAsync() { var key = "测试Hash键"; var age = new KeyValuePair<RedisValue, RedisValue>("Age", 23); var name = new KeyValuePair<RedisValue, RedisValue>("Name", "小超"); var sex = new KeyValuePair<RedisValue, RedisValue>("Sex", "男"); try { await RedisClient.HashSetAsync(key,new HashEntry[] { age,name, sex }); var entries=await RedisClient.HashGetAllAsync(key); //根据键获取键值对 foreach (var item in entries) { Console.WriteLine($"键:{item.Name},值:{item.Value}"); } //根据键获取值,如果不需要获取键 Console.WriteLine("只获取值,不获取键的操作"); var values= await RedisClient.HashValuesAsync(key); foreach (var value in values) { Console.WriteLine($"{value}"); } //根据键和和键值对集合的键获取某个对应的值 Console.WriteLine("根据键和和键值对集合的键获取某个对应的值的操作"); var fieldValue = await RedisClient.HashGetAsync(key,"Name"); Console.WriteLine($"获取键为:{key}下的键值对集合中的键为Name的值:{fieldValue}"); } catch (Exception) { //记录日志 Console.WriteLine("Redis,使用异常"); } } class UserInfo { internal string Name { get; set; } internal int Age { get; set; } } }

标签:void 控制 操作 介绍 oid 行存储 read 迁移 反序列化
原文地址:https://www.cnblogs.com/GreenLeaves/p/10171741.html