标签:分享图片 包括 edit 老版本 远程 客户端 十分 参数 了解
设计思想
分而治之:将大文件、大批量文件,分布式放在大量服务器上,以便于采取分而治之的方式对海量数据进行预算分析;
在大数据系统中的作用:为各类分布式运算框架(如:MapReduce,Spark等)提供数据存储服务
重要概念:文件切块,副本存放,元数据
HDFS架构
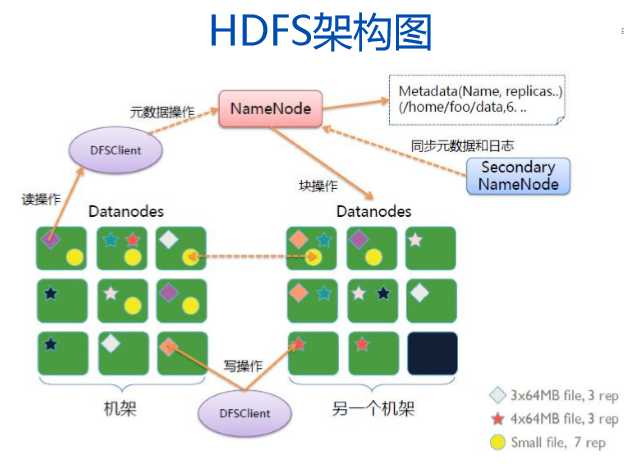
HDFS各节点
NameNode是HDFS的主节点,负责元数据的管理以及客户端对文件的访问。管理数据块的复制,它周期性地从集群中的每个DataNode接收心跳信号和块状态报告(Blockreport)
DataNode是HDFS的从节点,负责具体数据的读写,数据的存储。
数据块在DataNode以文件存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据(包括数据块的长度,快数据的效验以及时间戳)
DataNode启动向NameNode注册,通过后,周期性(1小时)的向NameNode上报告所有块信息。心跳是每三秒一次,心跳返回结果带有NameNode给该DataNode的命令(如复制块数据到另一台服务器,或删除某个数据块。如果超过十分钟没有收到某个DataNode的心跳,则认为该节点不可用。
SecondaryNameNode:负责元数据的同步
Client(客户端): 负责数据读写请求的发起
文件:
HDFS中的文件是分块存储(block),块的大小可以通过配置参数(dfs.blocksize)来规定,默认大小在Hadoop2.X版本中是128M,老版本是64M,,每个块有多个副本存储在不同的机器上,副本数可在文件生成时指定(默认3)
NameNode 负责文件元数据的操作,DataNode负责处理文件内容的读写请求。
数据块存放在哪些DataNode上由 NameNode来控制,根据全局情况做出块放置决定,读取文件时NameNode尽量让用户先读取最近的副本,降低带块消耗和读取时延。
数据块损坏处理:当DataNode读取块的时候,它会计算checksum,如果计算后的checksum与block创建时值不一样,说明该block已损坏,则认为该节点不可用,客户端会读取其它DataNode上的block,NameNode标记该block已经损坏,然后复制其他节点的block达到预期设置的文件备份数(默认每个块存储三份,存储在不同的DataNode节点上)。DataNode在其文件创建三周后验证其checksum。
NameNode启动过程:简述
1.加载fsimage和edits文件,生成新的fsimage和一个空的edits文件
2.等待DataNode注册和发送心跳
3.DataNode启动,向NameNode注册,发送心跳报告、块报告
4.NameNode离开安全模式。
NameNode启动过程:详解
1、Name启动的时候首先将fsimage(镜像)载入内存,并执行(replay)编辑日志editlog的的各项操作;
2、一旦在内存中建立文件系统元数据映射,则创建一个新的fsimage文件(这个过程不需 SecondaryNameNode) 和一个空的editlog;
3、在安全模式下,各个datanode会向namenode发送块列表的最新情况;
4、此刻namenode运行在安全模式。即NameNode的文件系统对于客服端来说是只读的。(显示目录,显示文 件内容等。写、删除、重命名都会失败);
5、NameNode开始监听RPC和HTTP请求
解释RPC:RPC(Remote Procedure Call Protocol)——远程过程通过协议,它是一种通过网络从远程计算机程序 上请求服务,而不需要了解底层网络技术的协议;
6、系统中数据块的位置并不是由namenode维护的,而是以块列表形式存储在datanode中;
7、在系统的正常操作期间,namenode会在内存中保留所有块信息的映射信息。
标签:分享图片 包括 edit 老版本 远程 客户端 十分 参数 了解
原文地址:https://www.cnblogs.com/ken-kqj/p/10175659.html