标签:spl hung ati lock 信息收集 font 注册 eth The
Android系统中,有硬件WatchDog用于定时检测关键硬件是否正常工作,类似地,在framework层有一个软件WatchDog用于定期检测关键系统服务是否发生死锁事件。
watchdog的源码很简单,主要有两个功能
1监控system_server中几个关键的锁,原理就是在android_fg线程中尝试加锁
2监控几个常用线程的执行时间,原理就是在这几个线程中执行任务
在SystemServer.startOtherServices()方法进行初始化
system_server进程启动的过程中初始化WatchDog,主要进行三个动作:
1.创建Watchdog对象
public class Watchdog extends Thread { //所有的HandlerChecker对象组成的列表,HandlerChecker对象类型 final ArrayList<HandlerChecker> mHandlerCheckers = new ArrayList<>(); ... private Watchdog() { super("watchdog"); //将前台线程加入队列 mMonitorChecker = new HandlerChecker(FgThread.getHandler(), "foreground thread", DEFAULT_TIMEOUT); mHandlerCheckers.add(mMonitorChecker); //将主线程加入队列 mHandlerCheckers.add(new HandlerChecker(new Handler(Looper.getMainLooper()), "main thread", DEFAULT_TIMEOUT)); //将ui线程加入队列 mHandlerCheckers.add(new HandlerChecker(UiThread.getHandler(), "ui thread", DEFAULT_TIMEOUT)); //将i/o线程加入队列 mHandlerCheckers.add(new HandlerChecker(IoThread.getHandler(), "i/o thread", DEFAULT_TIMEOUT)); //将display线程加入队列 mHandlerCheckers.add(new HandlerChecker(DisplayThread.getHandler(), "display thread", DEFAULT_TIMEOUT)); addMonitor(new BinderThreadMonitor()); } }
Watchdog继承于Thread,创建的线程名为”watchdog”。mHandlerCheckers队列包括、 主线程,fg, ui, io, display线程的HandlerChecker对象。
2.HandlerChecker对象
public final class HandlerChecker implements Runnable { private final Handler mHandler; //Handler对象 private final String mName; //线程描述名 private final long mWaitMax; //最长等待时间 //记录着监控的服务 private final ArrayList<Monitor> mMonitors = new ArrayList<Monitor>(); private boolean mCompleted; //开始检查时先设置成false private Monitor mCurrentMonitor; private long mStartTime; //开始准备检查的时间点 HandlerChecker(Handler handler, String name, long waitMaxMillis) { mHandler = handler; mName = name; mWaitMax = waitMaxMillis; mCompleted = true; } }
HandlerChecker继承自Runnable对象,里面维护着监控服务Monitor对象列表,使用Watchdog.addMonitor方法将服务监听者加入列表
addMonitor(new BinderThreadMonitor());
这里监控Binder线程, 将monitor添加到HandlerChecker的成员变量mMonitors列表中。将BinderThreadMonitor对象加入该线程。
private static final class BinderThreadMonitor implements Watchdog.Monitor { public void monitor() { Binder.blockUntilThreadAvailable(); } }
blockUntilThreadAvailable最终调用的是IPCThreadState,监控是否有可用的binder进程。
3.Watchdog start
当调用Watchdog.getInstance().start()时,则进入线程“watchdog”的run()方法, 该方法分成两部分:
4.Watchdog run
public void run() { boolean waitedHalf = false; while (true) { final ArrayList<HandlerChecker> blockedCheckers; final String subject; final boolean allowRestart; int debuggerWasConnected = 0; synchronized (this) { long timeout = CHECK_INTERVAL; //CHECK_INTERVAL=30s for (int i=0; i<mHandlerCheckers.size(); i++) { HandlerChecker hc = mHandlerCheckers.get(i); //执行所有的Checker的监控方法, 每个Checker记录当前的mStartTime[见小节3.2] hc.scheduleCheckLocked(); } if (debuggerWasConnected > 0) { debuggerWasConnected--; } long start = SystemClock.uptimeMillis(); //通过循环,保证执行30s才会继续往下执行 while (timeout > 0) { if (Debug.isDebuggerConnected()) { debuggerWasConnected = 2; } try { wait(timeout); //触发中断,直接捕获异常,继续等待. } catch (InterruptedException e) { Log.wtf(TAG, e); } if (Debug.isDebuggerConnected()) { debuggerWasConnected = 2; } timeout = CHECK_INTERVAL - (SystemClock.uptimeMillis() - start); } //评估Checker状态【见小节3.3】 final int waitState = evaluateCheckerCompletionLocked(); if (waitState == COMPLETED) { waitedHalf = false; continue; } else if (waitState == WAITING) { continue; } else if (waitState == WAITED_HALF) { if (!waitedHalf) { //首次进入等待时间过半的状态 ArrayList<Integer> pids = new ArrayList<Integer>(); pids.add(Process.myPid()); //输出system_server和3个native进程的traces【见小节4.2】 ActivityManagerService.dumpStackTraces(true, pids, null, null, NATIVE_STACKS_OF_INTEREST); waitedHalf = true; } continue; } ... //进入这里,意味着Watchdog已超时【见小节4.1】 } ... } } public static final String[] NATIVE_STACKS_OF_INTEREST = new String[] { "/system/bin/mediaserver", "/system/bin/sdcard", "/system/bin/surfaceflinger" };
该方法主要功能:
由此,可见当触发一次Watchdog, 则必然会调用两次AMS.dumpStackTraces, 也就是说system_server和3个Native进程的traces 的traces信息会输出两遍,且时间间隔超过30s.
5.scheduleCheckLocked
public final class HandlerChecker implements Runnable { ... public void scheduleCheckLocked() { if (mMonitors.size() == 0 && mHandler.getLooper().getQueue().isPolling()) { mCompleted = true; //当目标looper正在轮询状态则返回。 return; } if (!mCompleted) { return; //有一个check正在处理中,则无需重复发送 } mCompleted = false; mCurrentMonitor = null; // 记录当下的时间 mStartTime = SystemClock.uptimeMillis(); //发送消息,插入消息队列最开头, 见下方的run()方法 mHandler.postAtFrontOfQueue(this); } public void run() { final int size = mMonitors.size(); for (int i = 0 ; i < size ; i++) { synchronized (Watchdog.this) { mCurrentMonitor = mMonitors.get(i); } //回调具体服务的monitor方法 mCurrentMonitor.monitor(); } synchronized (Watchdog.this) { mCompleted = true; mCurrentMonitor = null; } } }
该方法主要功能:
向Watchdog的监控线程的Looper池的最头部执行该HandlerChecker.run()方法, 在该方法中调用monitor(),执行完成后会设置mCompleted = true.
那么当handler消息池处理当前的消息, 导致迟迟没有机会执行monitor()方法, 则会触发watchdog.
其中postAtFrontOfQueue(this),该方法输入参数为Runnable对象,根据消息机制, 最终会回调HandlerChecker中的run方法,该方法会循环遍历所有的Monitor接口,具体的服务实现该接口的monitor()方法。
可能的问题,如果有其他消息不断地调用postAtFrontOfQueue()也可能导致watchdog没有机会执行;或者是每个monitor消耗一些时间,累加起来超过1分钟造成的watchdog. 这些都是非常规的Watchdog.
Watchdog处理流程
public void run() { while (true) { synchronized (this) { ... //获取被阻塞的checkers 【见小节4.1.1】 blockedCheckers = getBlockedCheckersLocked(); // 获取描述信息 【见小节4.1.2】 subject = describeCheckersLocked(blockedCheckers); allowRestart = mAllowRestart; } EventLog.writeEvent(EventLogTags.WATCHDOG, subject); ArrayList<Integer> pids = new ArrayList<Integer>(); pids.add(Process.myPid()); if (mPhonePid > 0) pids.add(mPhonePid); //第二次以追加的方式,输出system_server和3个native进程的栈信息【见小节4.2】 final File stack = ActivityManagerService.dumpStackTraces( !waitedHalf, pids, null, null, NATIVE_STACKS_OF_INTEREST); //系统已被阻塞1分钟,也不在乎多等待2s,来确保stack trace信息输出 SystemClock.sleep(2000); if (RECORD_KERNEL_THREADS) { //输出kernel栈信息【见小节4.3】 dumpKernelStackTraces(); } //触发kernel来dump所有阻塞线程【见小节4.4】 doSysRq(‘l‘); //输出dropbox信息【见小节4.5】 Thread dropboxThread = new Thread("watchdogWriteToDropbox") { public void run() { mActivity.addErrorToDropBox( "watchdog", null, "system_server", null, null, subject, null, stack, null); } }; dropboxThread.start(); try { dropboxThread.join(2000); //等待dropbox线程工作2s } catch (InterruptedException ignored) { } IActivityController controller; synchronized (this) { controller = mController; } if (controller != null) { //将阻塞状态报告给activity controller, try { Binder.setDumpDisabled("Service dumps disabled due to hung system process."); //返回值为1表示继续等待,-1表示杀死系统 int res = controller.systemNotResponding(subject); if (res >= 0) { waitedHalf = false; continue; //设置ActivityController的某些情况下,可以让发生Watchdog时继续等待 } } catch (RemoteException e) { } } //当debugger没有attach时,才杀死进程 if (Debug.isDebuggerConnected()) { debuggerWasConnected = 2; } if (debuggerWasConnected >= 2) { Slog.w(TAG, "Debugger connected: Watchdog is *not* killing the system process"); } else if (debuggerWasConnected > 0) { Slog.w(TAG, "Debugger was connected: Watchdog is *not* killing the system process"); } else if (!allowRestart) { Slog.w(TAG, "Restart not allowed: Watchdog is *not* killing the system process"); } else { Slog.w(TAG, "*** WATCHDOG KILLING SYSTEM PROCESS: " + subject); //遍历输出阻塞线程的栈信息 for (int i=0; i<blockedCheckers.size(); i++) { Slog.w(TAG, blockedCheckers.get(i).getName() + " stack trace:"); StackTraceElement[] stackTrace = blockedCheckers.get(i).getThread().getStackTrace(); for (StackTraceElement element: stackTrace) { Slog.w(TAG, " at " + element); } } Slog.w(TAG, "*** GOODBYE!"); //杀死进程system_server【见小节4.6】 Process.killProcess(Process.myPid()); System.exit(10); } waitedHalf = false; } }
Watchdog检测到异常的信息收集工作:
收集完信息后便会杀死system_server进程。此处allowRestart默认值为true, 当执行am hang操作则设置不允许重启(allowRestart =false), 则不会杀死system_server进程.
将所有执行时间超过1分钟的handler线程或者monitor都记录下来.
Blocked in handler,意味着相应的线程处理当前消息时间超过1分钟;Blocked in monitor,意味着相应的线程处理当前消息时间超过1分钟,或者monitor迟迟拿不到锁;对于触发watchdog时,生成的dropbox文件的tag是system_server_watchdog,内容是traces以及相应的blocked信息。
当杀死system_server进程,从而导致zygote进程自杀,进而触发init执行重启Zygote进程,这便出现了手机framework重启的现象。
总结
Watchdog是一个运行在system_server进程的名为”watchdog”的线程::
mHandlerCheckers记录所有的HandlerChecker对象的列表,包括foreground, main, ui, i/o, display线程的handler;mHandlerChecker.mMonitors记录所有Watchdog目前正在监控Monitor,所有的这些monitors都运行在foreground线程。Watchdog监控:
以下情况,即使触发了Watchdog,也不会杀掉system_server进程:
Watchdog监控的线程有:
(默认地DEFAULT_TIMEOUT=60s,调试时才为10s方便找出潜在的ANR问题)
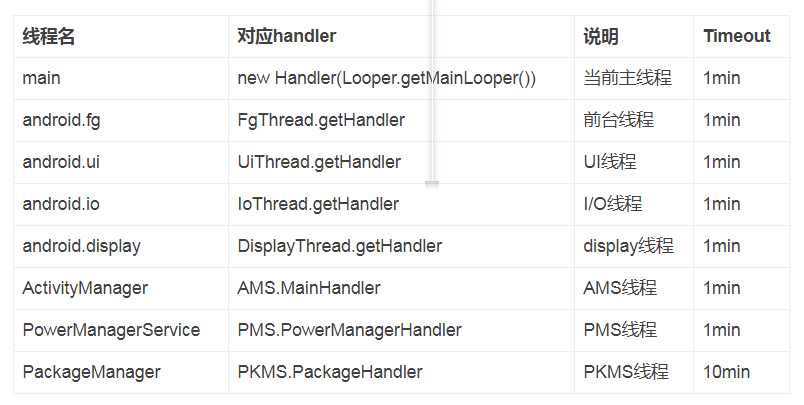
目前watchdog会监控system_server进程中的以上8个线程:
能够被Watchdog监控的系统服务都实现了Watchdog.Monitor接口,并实现其中的monitor()方法。运行在android.fg线程, 系统中实现该接口类主要有:
watchdog在check过程中出现阻塞1分钟的情况,则会输出:
标签:spl hung ati lock 信息收集 font 注册 eth The
原文地址:https://www.cnblogs.com/krislight1105/p/10180514.html