标签:并行 nal ef6 将不 滤波 关系 smooth 填充 normal
文章来源: https://zhuanlan.zhihu.com/p/50369448
从这几年的分割结果来看,基于空洞卷积的分割方法效果要好一些,为此,拿出两天时间来重新思考下空洞卷积问题。
- . -语义分割创新该怎么做呢。
空洞卷积(Dilated/Atrous Convolution),广泛应用于语义分割与目标检测等任务中,语义分割中经典的deeplab系列与DUC对空洞卷积进行了深入的思考。目标检测中SSD与RFBNet,同样使用了空洞卷积。
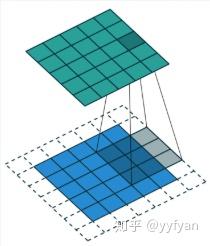
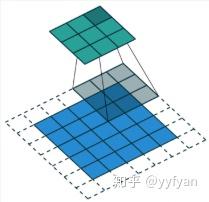
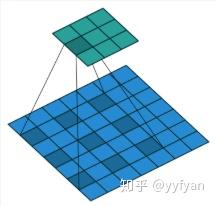
标准卷积与空洞卷积在实现上基本相同,标准卷积可以看做空洞卷积的特殊形式。看到这,空洞卷积应该不那么陌生了。。
空洞卷积有什么作用呢?
从这里可以看出,空洞卷积可以任意扩大感受野,且不需要引入额外参数,但如果把分辨率增加了,算法整体计算量肯定会增加。
说了这么多有关感受野的话,感受野究竟怎么计算呢?其实和标准卷积是一致的。
空洞卷积实际卷积核大小:
K=k+(k-1)(r-1),k为原始卷积核大小,r为空洞卷积参数空洞率;
以三个r=2的3*3/s1空洞卷积为例计算感受野:
K=k+(k-1)(r-1)=3+2*1=5
R=1+4+4+4=13
而语义分割由于需要获得较大的分辨率图,因此经常在网络的最后两个stage,取消降采样操作,之后采用空洞卷积弥补丢失的感受野。
以语义分割中常使用的VGG和ResNet50为例,计算其空洞前与空洞后的感受野。
VGG16:将FC6层使用7*7卷积替换,其他不变,此版本我们称为VGG_Conv,根据deeplabv1的设置,我们使用DeepLab-CRF-7x7,即取消pool4和pool5的降采样操作,改为了3*3/s1,同时将 conv5_1-conv5_3使用r=2的空洞卷积。FC的空洞率r=4。
VGG_Conv:R=1+6)*2+2+2+2)*2+2+2+2)*2+2+2+2)*2+2+2)*2+2+2=404
DeepLab-CRF-7x7:R=1+24)+2+4+4+4)+2+2+2+2)*2+2+2+2)*2+2+2)*2+2+2=412
两者和感受野近似相等,从deeplab实验结果可以看出,感受野不一定和之前完全一样,但感受野大了效果会好一些。表中结果和自己计算的不一样,不知道表中感受野怎么计算的。。

结论:空洞前与空洞后感受野可以不一致,但空洞后的感受野不要小于之前的,这样其实是不影响网络精调的,因为参数没有变。恍然大悟啊!
是的,空洞卷积是存在理论问题的,论文中称为gridding,其实就是网格效应/棋盘问题。因为空洞卷积得到的某一层的结果中,邻近的像素是从相互独立的子集中卷积得到的,相互之间缺少依赖。
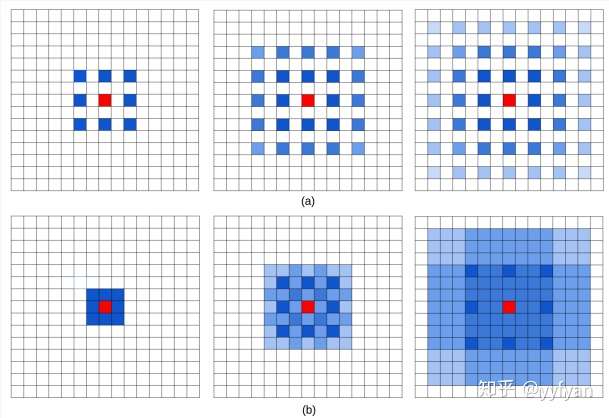
通过图a解释了空洞卷积存在的问题,从左到右属于top-bottom关系,三层卷积均为r=2的dilatedConv,可以看出最上层的红色像素的感受野为13且参与实际计算的只有75%,很容易看出其存在的问题。
使用HDC的方案解决该问题,不同于采用相同的空洞率的deeplab方案,该方案将一定数量的layer形成一个组,然后每个组使用连续增加的空洞率,其他组重复。如deeplab使用rate=2,而HDC采用r=1,r=2,r=3三个空洞率组合,这两种方案感受野都是13。但HDC方案可以从更广阔的像素范围获取信息,避免了grid问题。同时该方案也可以通过修改rate任意调整感受野。

如果特征map有比空洞率更高频的内容,则grid问题更明显。
提出了三种方法:
Removing max pooling:由于maxpool会引入更高频的激活,这样的激活会随着卷积层往后传播,使得grid问题更明显。

Adding layers:在网络最后增加更小空洞率的残参block, 有点类似于HDC。
Removing residual connections:去掉残参连接,防止之前层的高频信号往后传播。
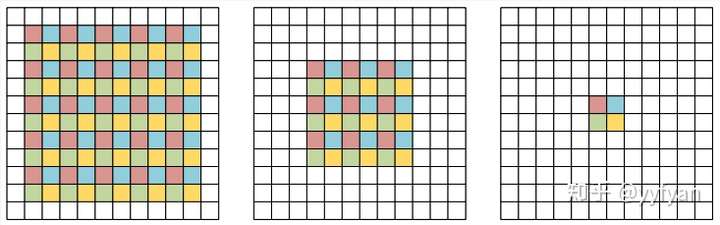
空洞卷积的分解观点,在原始特征图上周期性采样形成4组分辨率降低的特征图,然后使用原始的空洞卷积参数(去掉了空洞0)分别进行卷积,之后将卷积的结果进行上采样组合。从该分解观点可以看出,卷积前后的4个组之间没有相互依赖,使得收集到不一致的局部信息。
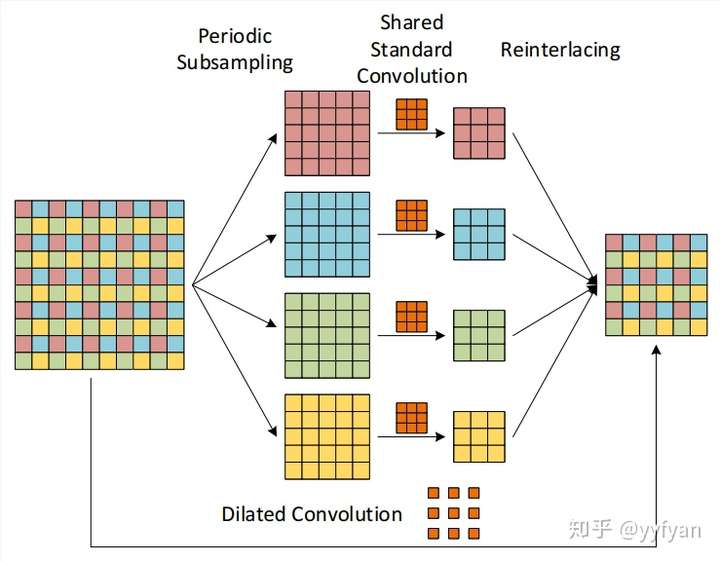
从上面分解的观点出发:
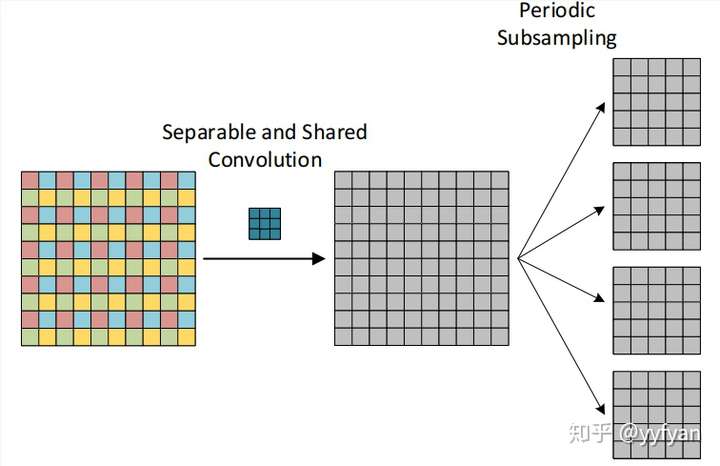
(1) 在最后生成的4组卷积结果之后,经过一层组交错层,类似于ShuffleNet,使得每组结果能进行相互交错,相互依赖,以此解决局部信息不一致的问题。
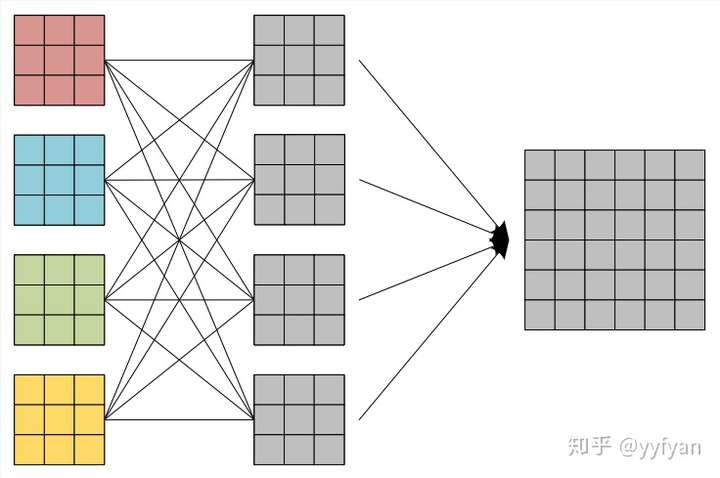
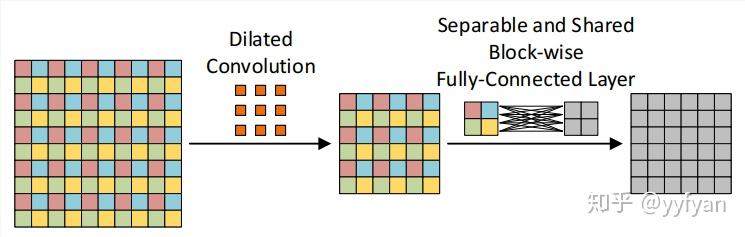
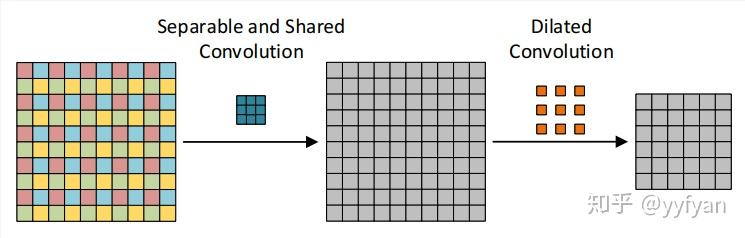
(2) 第二种方法为在空洞卷积之前进行局部信息依赖,即增加一层卷积操作,卷积利用了分离卷积,并且所有通道共享参数。
deeplabv3在v2基础上进一步探索空洞卷积,分别研究了级联ASPP与并联ASPP两种结构。

deeplabv3不同于deeplabv2,在resnet101基础上级联了更深的网络,随着深度的增加,使用了不同的空洞率的卷积,这些卷积保证分辨率不降低的情况下,感受野可以任意控制,一般让空洞率成倍增加。同时使用了Multigrid策略,在同一个blocks的不同层使用分层的空洞率,如2,4,8,而不是都使用2,这样使得感受野相比原来的有所增加。但这样同样会存在grid问题。
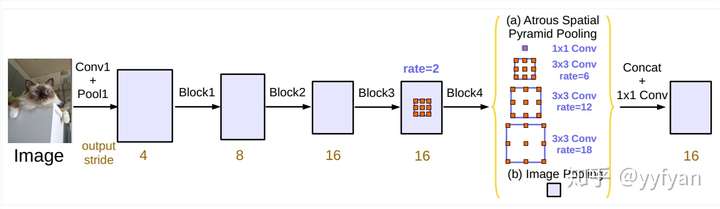
ASPP存在的问题,当使用的空洞率增大时,有效的滤波参数数量逐渐减小。极端的,当r等于特征图大小时,该卷积没有捕获整幅图像的上下文信息,而是退化为1*1卷积。
解决方案:增加图像级特征,使用全局池化获取图像全局信息,而其他部分的卷积为了捕获多尺度信息,这里的卷积不同于deeplabv2,加了batch normalization。
ESPNet利用分解卷积的思想,先用1*1卷积将通道数降低减少计算量,后面再加上基于空洞卷积的金字塔模型,捕获多尺度信息。
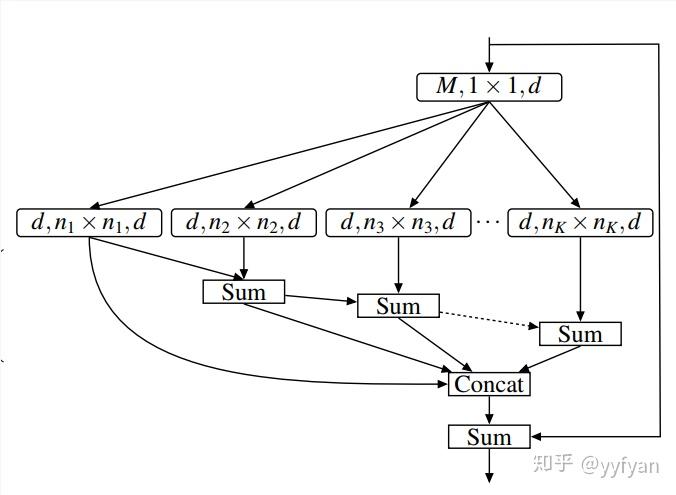
之前的方法都是通过引入新的计算量,学习新的参数来解决grid问题。而这里直接使用了特征分层的思想直接将不同rate的空洞卷积的输出分层sum,其实就是将不同的感受野相加,弥补了空洞带来的网格效应。从结果上看效果不错。

训练技巧:
所有卷积后都使用BN和PReLU,很多实时分割小网络都使用了PReLU;
使用Adam训练,很多小网络使用这个;
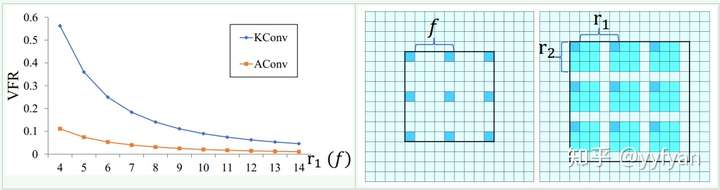
使用Kronecker convolution来解决空洞卷积局部信息丢失问题,以r1=4、r2=3为例,KConv将每个标准卷积的元素都乘以一个相同的矩阵,该矩阵由0,1组成,这样参数量是不增加的。该矩阵为:
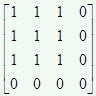
这样每个元素乘以矩阵后变为上面右图所示的图。因此,可以看出r1控制空洞的数量,也即扩大了感受野,而r2控制的是每个空洞卷积忽视的局部信息。当r2=1时,其实就是空洞卷积,当r2=r1=1时就是标准卷积。
总体效果mIOU提升了1%左右。
除此之外,提出了一个TFA模块,利用树形分层结构进行多尺度与上下文信息整合。结构简单,但十分有效,精度提升4-5%。
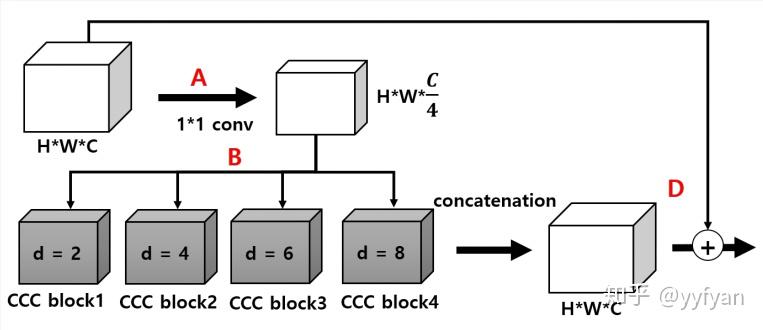
针对实时语义分割提出的网络结构,深度分离卷积与空洞卷积的组合,在ESPNet上做的实验。并且说明简单的组合会带来精度的降低,由于局部信息的丢失。为此,在深度分离空洞卷积之前,使用了两级一维分离卷积捕获局部信息。
网络结构上与ESPNet保持一致,其中,并行分支结果直接Cat,不需要后处理,每个分支不需要bn+relu。消融实验表明,在一维卷积之间加入BN+PReLU,精度会增加1.4%。
标签:并行 nal ef6 将不 滤波 关系 smooth 填充 normal
原文地址:https://www.cnblogs.com/kk17/p/10181971.html