标签:速度 基于 集成 color virtual 实现 数据库设计 数据库 存在
集群的核心意义只有一个:保证一个节点出现了问题之后,其他的节点可以继续提供服务使用。
Redis基础部分讲解过主从配置:对于主从配置可以有两类:一主二从,层级关系。开发者一主二从是常用的手段。
Redis的主从配置是所有Redis集群的一个基础。但是只是依靠主从依然无法实现高可用的配置。
Redis集群有以下两种方案
1)keepalived+twemproxy+HAProxy+sentinel
对redis集群而言,首先在主从的基础上发展出了一个叫哨兵的处理机制,所谓的哨兵的处理机制指的是,当我三台主机的master节点出现了问题之后,会自动的在两个slave节点下重新退选举出一个新的master节点,这样就可以保证原master出现问题之后,redis数据依然存在有主从的配置。
但是哨兵机制也只是针对于一种单主机的配置形式。因为不可能只使用一台主机来实现我们redis的配置。而推特网站发布了一个代理机制。可以有效的实现数据的分片存储。即:根据不同算法 实现不同主机的分片存储。
以保证负载均衡,同时可以结合keepalivedh和HAProxy组件实现twemproxy的高可用。
2)Redis Cluster
Redis在后来的版本发展之中也退出了一个自己的redis Cluster集群配置,利用这样的配置可以不用自己来通过配置文件实现主从关系的实现,而直接通过命令完成。
哨兵机制简介
只要是进行高可用的架构部署,那么就必须保证多节点,在Redis里面使用了主从模式可以多节点配置,但是传统的主从模式设计 一旦master主机出现问题之后,两台Slave主机无法提供正常的工作支持,列如:Slave主机为只读主机,而且如果要想继续提供支持,那么至少应该通过剩余的几台Slave里面去推选出一个新的Master,并且最为重要的是:这个新的Master能够被用户的程序找到。
如果要想进行哨兵机制的实现,一定需要具备有如下的几个特点:
sentinel的功能
1)监控Monitoring
sentinel时刻监控着redis master-slave是否正常运行;
2)通知Notification
sentinel可以通过api来通知管理员,被监控的redis master-slave出现了问题。
3)自动故障转移Automatic failover
当redis master出现故障不可用状态,sentinel会开始一次故障转移,将其中一个salve提升为一个新的master,将其他salve重新配置使用新的master同步,并使用Redis的服务器应用程序连接时收到使用新的地址连接。
4)配置提供者Configuration provider
sentinel作为在集群中的权威来源,客户端连接到sentinel来获取某个服务的当前Redis主服务器的地址和其他信息。当故障发生转移时,Sentinel会报告新地址(更改哨兵文件对应的配置内容)。
通常一台主机运行三个哨兵,并且该哨兵运行的端口不同,但是这三个哨兵都要去监控同一个master的地址。(找到了master就等于找到了所有的slave)
twemproxy分片处理
不管你电脑性能多好,只要你运行了Redis,那么就有可能造成一种非常可怕的局面:你电脑的内存将立刻被占满,而且一台Redis数据库的性能终归是有限制的。
TwemProxy是一个专门为了这种nosql数据库设计的一款代理工具软件,这个工具软件最大的特征是可以实现数据的分片处理。所为的分片指的是根据一定的算法将要保存的数据保存到不同的节点之中。
twemProxy整合sentinel
Twemproxy如果要与Redis集成使用的是Redis的Master节点,因为只有Master节点才具有写功能。
一旦某一个Master被干掉了,则一定要重新选举出一个新的Master节点,但是这个时候会出现有一个问题:twemproxy所使用的配置文件时单独存在的。哨兵选举完成后,需要更新配置文件
如果要想保证所有的Redis集群高可用设计,需要单独准备一个shell脚本与所有的哨兵机制一起使用。 两步操作:1.、更改redis_master.conf文件(twemproxy的配置文件) 2、重新启动twemproxy进程
HAProxy与twemproxy集成
Twemproxy主要功能在于数据的分片处理,而且会发现在整个Redis集群里面必须通过twemProxy,于是这个时候就有可能造成一种问题你后面Redis集群一定会速度爆快,因为一堆的redis数据库。但是所有的性能都卡在了代理上
解决办法:用HAProxy做twemproxy的代理。
HAProxy是一个开源的,高性能的,基于TCP第四层和http第七应用层的千万级高并发负载均衡软件;
为了保证HAProxy的高可用设计,所以应该设计有两套的HAProxy的代理主机,但是现在就出现了一个问题,如果现在提供了两套的HAProxy主机,用户应该怎么访问?需要记住两个地址吗。
用户访问Keepalived虚拟IP,Keepalived访问主(备)HAProxy
Keepalived是一个基于VRRP协议来实现的服务高可用方案,可用利用其来避免IP单点故障,类似的工具还有heartbeat,pacemaker。但是它一般不会单独出现,而是与其他负载均衡技术(如lvs,nginx,haproxy)一起工作来达到集群高可用。
VRRP协议全称Virtual Router Redundancy Protocol,即虚拟路由冗余协议。
以下是keepalived+twemproxy+HAProxy+sentinel的整个架构图(小人是指哨兵)
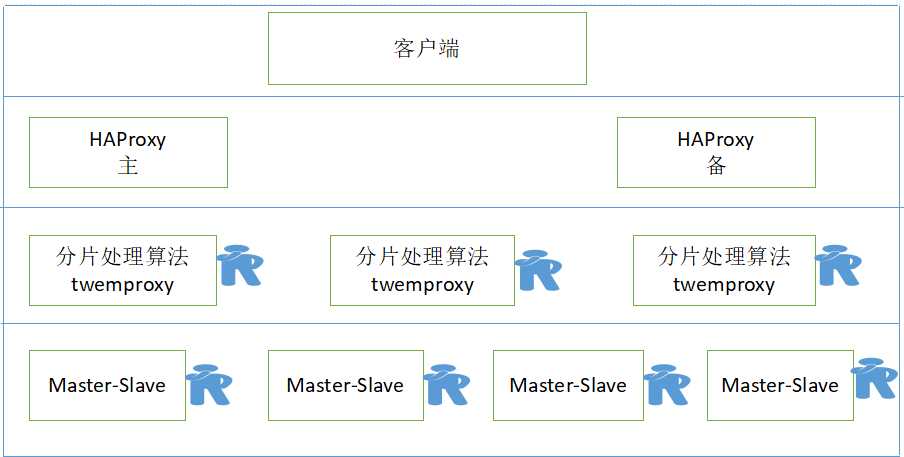
以上Redis集群作为项目的部署环境,需要追加twemproxy代理做分片,而后使用HAProxy做twemproxy的负载均衡,而后使用Keepalived作为HAProxy的vip技术,但是这样的设计成本太高。
redis-cluster,直接使用redis就可以实现所谓的分片,高可用。
redis-cluster设计的时候考虑到了去中心化,中间件,因为中心点的存在导致了性能的瓶颈,解决一个问题 会解决第二个 第三个问题。。。
redis-cluster中每一个redis的服务它都可以具备分片,都可以具备集群的功能。
也就是说集群中的每个节点都是平等的关系,每个节点都保存各自的数据和整个集群的状态。每个节点都和其它所有节点连接,而且这些连接保持活跃。
这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
redis-cluster选举(容错)
选举过程是集群中所有master参与,如果半数以上master节点与master节点通信超过设置时间(cluster-node-timeout),认为当前master节点挂掉。
当我发现某一台主机的master挂掉了,我们从新选举一个salve当做master(整个过程中把哨兵避免了,不需要修改哨兵的配置文件了)
这样可以去掉所有的代理层组件,由Redis自己来完成,这就是redis-cluster的设计方案。
标签:速度 基于 集成 color virtual 实现 数据库设计 数据库 存在
原文地址:https://www.cnblogs.com/ssskkk/p/10162651.html