标签:数据 import image das 结果 特征 embed plt 实例
实例要求:以sklearn库自带的iris数据集为例,使用sklearn估计器构建K-Means聚类模型,并且完成预测类别功能以及聚类结果可视化。
实例代码:
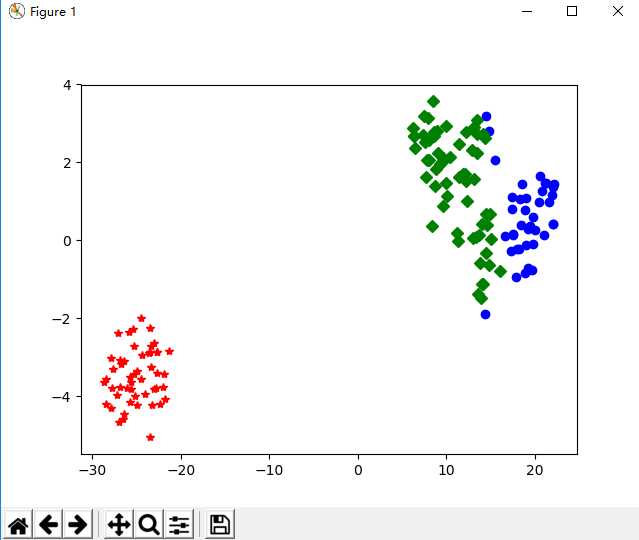
import pandas as pd import matplotlib.pyplot as plt from sklearn.datasets import load_iris from sklearn.preprocessing import MinMaxScaler from sklearn.cluster import KMeans from sklearn.manifold import TSNE ‘‘‘ 构建K-Means模型 ‘‘‘ iris = load_iris() iris_data = iris[‘data‘] # 提取数据集中的数据 iris_target = iris[‘target‘] # 提取数据集中的标签 iris_names = iris[‘feature_names‘] # 提取特征名 scale = MinMaxScaler().fit(iris_data) # 训练规则 iris_dataScale = scale.transform(iris_data) # 应用规则 kmeans = KMeans(n_clusters=3,random_state=123).fit(iris_dataScale) # 构建并训练模型 print(‘构建的K-Means模型为:\n‘,kmeans) result = kmeans.predict([[1.5,1.5,1.5,1.5]]) print(‘花瓣花萼长度宽度全为1.5的鸢尾花预测类别为:‘,result[0]) ‘‘‘ 聚类结果可视化 ‘‘‘ tsne = TSNE(n_components=2,init=‘random‘,random_state=177).fit(iris_data) # 使用TSNE进行数据降维,降成两维 df = pd.DataFrame(tsne.embedding_) # 将原始数据转换为DataFrame df[‘labels‘] = kmeans.labels_ # 将聚类结果存储进df数据表中 df1 = df[df[‘labels‘]==0] df2 = df[df[‘labels‘]==1] df3 = df[df[‘labels‘]==2] # fig = plt.figure(figsize=(9,6)) # 绘制图形 设定空白画布,并制定大小 plt.plot(df1[0],df1[1],‘bo‘,df2[0],df2[1],‘r*‘,df3[0],df3[1],‘gD‘) plt.show() # 显示图片
实例结果:
构建的K-Means模型为:

花瓣预测结果:
![]()
聚类结果可视化:
标签:数据 import image das 结果 特征 embed plt 实例
原文地址:https://www.cnblogs.com/xiaoyh/p/10187195.html