标签:min done base names pat masters led pen quota
官方的in-place upgrade直接在线升级,但问题是只能一个一个版本的升无法做到跨版本升级,如果一次跨越多个版本,并且集群规模比较大的化,就需要花费很长的时间了。
实际生产过程中因为是分布式环境,所以机器量一般都比较大,官方升级模式有一个好处就是始终能够对外提供服务。
问题是连续升级的时间消耗比较长,而且容易出问题。而这篇文章的方法是,直接安装新的集群模式,同时将原有的旧节点覆盖成新的版本。
基于每个project备份
[root@master ~]# oc get all -n myproject NAME DOCKER REPO TAGS UPDATED is/tomcat docker-registry.default.svc:5000/myproject/tomcat 8-slim 4 minutes ago NAME REVISION DESIRED CURRENT TRIGGERED BY dc/tomcat 1 1 1 config,image(tomcat:8-slim) NAME DESIRED CURRENT READY AGE rc/tomcat-1 1 1 1 3m NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD routes/tomcat tomcat-myproject.app.example.com tomcat 8080-tcp None NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE svc/tomcat 172.30.66.175 <none> 8080/TCP 3m NAME READY STATUS RESTARTS AGE po/tomcat-1-6c3s0 1/1 Running 0 3m
[root@master ~]# oc get -o yaml --export all > project.yaml [root@master ~]# ls anaconda-ks.cfg project.yaml tomcat.tar
[root@master ~]# for object in rolebindings serviceaccounts secrets imagestreamtags podpreset cms egressnetworkpolicies rolebindingrestrictions limitranges resourcequotas pvcs templates cronjobs statefulsets hpas deployments replicasets poddisruptionbudget endpoints > do > oc get -o yaml --export $object > $object.yaml > done the server doesn‘t have a resource type "cms" the server doesn‘t have a resource type "pvcs" the server doesn‘t have a resource type "hpas" [root@master ~]# ls anaconda-ks.cfg egressnetworkpolicies.yaml limitranges.yaml pvcs.yaml rolebindings.yaml templates.yaml cms.yaml endpoints.yaml poddisruptionbudget.yaml replicasets.yaml secrets.yaml tomcat.tar cronjobs.yaml hpas.yaml podpreset.yaml resourcequotas.yaml serviceaccounts.yaml deployments.yaml imagestreamtags.yaml project.yaml rolebindingrestrictions.yaml statefulsets.yaml
比如3.11, 加入一个fresh机器作为新的master节点
原有节点需要完成的工作包括:
在原来的node1.example.com, node2.example.com中进行如下操作,如果不删除配置将无法产生csr的请求
rm -rf /etc/origin/node/*
vi /etc/origin/node/resolv.conf # nameserver updated by /etc/NetworkManager/dispatcher.d/99-origin-dns.sh # Generated by NetworkManager search cluster.local example.com nameserver 192.168.56.113
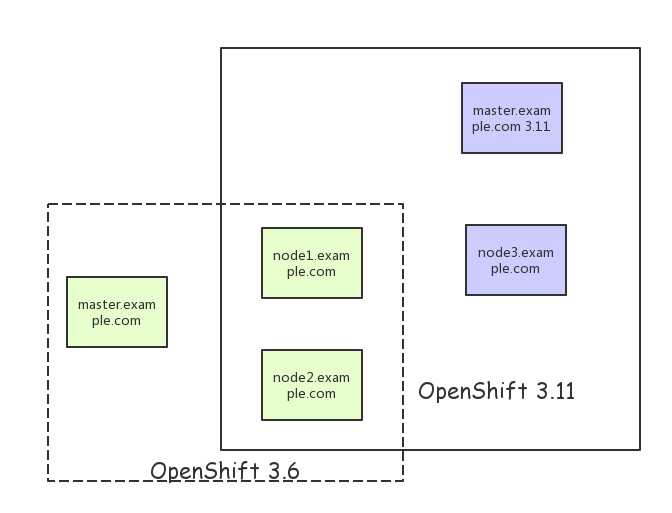
192.168.56.113 master.example.com 192.168.56.104 node1.example.com 192.168.56.105 node2.example.com 192.168.56.115 node3.example.com 192.168.56.115 registry.example.com
地址里面,node1,node2是3.6的版本,而node3是新节点。
ssh-copy-id root@node1.example.com
ssh-copy-id root@node2.example.com
master配置
master.example.com中的/etc/ansible/hosts文件
[root@master ~]# cat /etc/ansible/hosts [OSEv3:children] masters nodes etcd # Set variables common for all OSEv3 hosts [OSEv3:vars] # SSH user, this user should allow ssh based auth without requiring a password ansible_ssh_user=root # If ansible_ssh_user is not root, ansible_become must be set to true #ansible_become=true openshift_deployment_type=openshift-enterprise openshift_image_tag=v3.11.16 openshift_pkg_version=-3.11.16 openshift_master_default_subdomain=apps.example.com openshift_docker_options="--selinux-enabled --insecure-registry 172.30.0.0/16 --log-driver json-file --log-opt max-size=50M --log-opt max-file=3 --insecure-registry registry.example.com --add-registry registry.example.com" oreg_url=registry.example.com/openshift3/ose-${component}:${version} openshift_examples_modify_imagestreams=true openshift_metrics_install_metrics=true openshift_logging_install_logging=false openshift_logging_es_nodeselector={"node-role.kubernetes.io/infra": "true"} openshift_enable_service_catalog=false ansible_service_broker_install=false # uncomment the following to enable htpasswd authentication; defaults to DenyAllPasswordIdentityProvider openshift_master_identity_providers=[{‘name‘: ‘htpasswd_auth‘, ‘login‘: ‘true‘, ‘challenge‘: ‘true‘, ‘kind‘: ‘HTPasswdPasswordIdentityProvider‘}] openshift_disable_check="disk_availability,docker_image_availability,memory_availability,docker_storage,package_version" # host group for masters [masters] master.example.com # host group for etcd [etcd] master.example.com # host group for nodes, includes region info [nodes] master.example.com openshift_node_group_name=‘node-config-master‘ node1.example.com openshift_node_group_name=‘node-config-infra‘ node2.example.com openshift_node_group_name=‘node-config-compute‘ node3.example.com openshift_node_group_name=‘node-config-compute‘
资源问题,不安装log,service catalog什么的了。
运行部署
ansible-playbook -vv /usr/share/ansible/openshift-ansible/playbooks/deploy_cluster.yml
验证安装
[root@master openshift-ansible]# oc get nodes NAME STATUS ROLES AGE VERSION master.example.com Ready master 44m v1.11.0+d4cacc0 node1.example.com Ready infra 40m v1.11.0+d4cacc0 node2.example.com Ready compute 40m v1.11.0+d4cacc0 node3.example.com Ready compute 40m v1.11.0+d4cacc0
$ oc new-project <projectname> 导入镜像(如果镜像仓库没修改就不用了) $ oc create -f project.yaml $ oc create -f secret.yaml $ oc create -f serviceaccount.yaml $ oc create -f pvc.yaml $ oc create -f rolebindings.yaml
备份和恢复参考
https://docs.openshift.com/container-platform/3.11/day_two_guide/project_level_tasks.html
标签:min done base names pat masters led pen quota
原文地址:https://www.cnblogs.com/ericnie/p/10193480.html