标签:password day 执行 技术 hba tls match apache mys
思路同我之前的博客的思路 https://www.cnblogs.com/symkmk123/p/10197467.html
但是数据是从web访问的数据
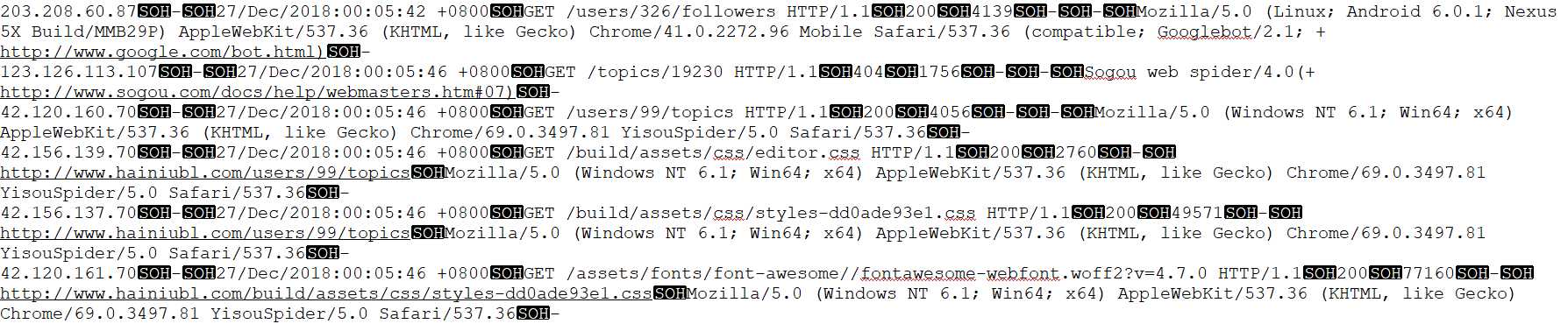
观察数据的格式,我们主要分析第四个字段的数据.发现有.css , .jpg .png等等等无效的数据.
通过观察数据发现有效数据都不带 . , 所以第一次过滤写入avro总表里的数据一次过滤后的有效数据,不包含 .css , .jpg , .png 这样的数据
同时count持久化到mysql
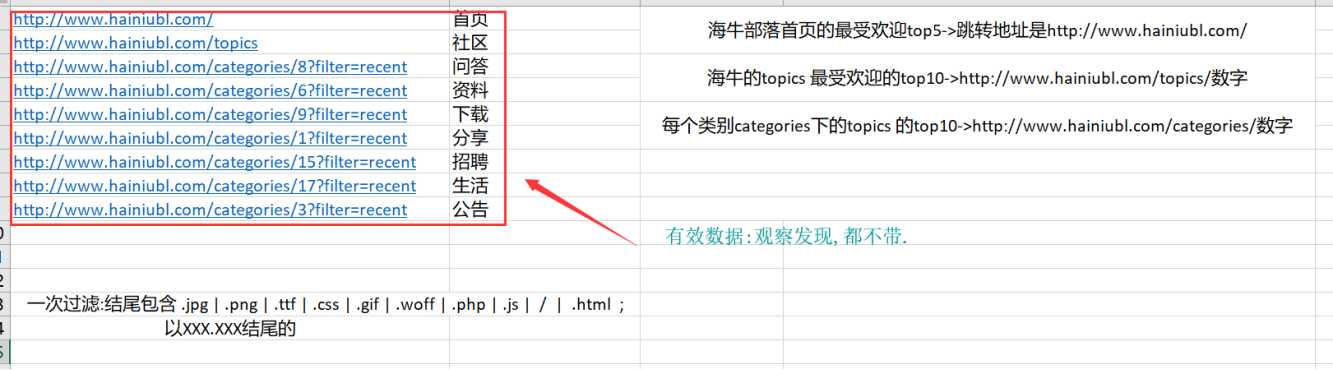
通过观察发现这个需求的有效url是 /topics/数字的 所以在第一次过滤的数据的基础上的正则就是

这种保留下来的也只是/topics/数字这种格式,方便用 hql统计结果
上代码
//Text2Avro package mrrun.hainiuetl; import java.io.IOException; import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Date; import java.util.Locale; import org.apache.avro.Schema; import org.apache.avro.generic.GenericData; import org.apache.avro.generic.GenericRecord; import org.apache.avro.mapred.AvroKey; import org.apache.avro.mapreduce.AvroJob; import org.apache.avro.mapreduce.AvroKeyOutputFormat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Counter; import org.apache.hadoop.mapreduce.CounterGroup; import org.apache.hadoop.mapreduce.Counters; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import mrrun.base.BaseMR; public class Text2Avro extends BaseMR { public static Schema schema = null; public static Schema.Parser parse = new Schema.Parser(); public static class Text2AvroMapper extends Mapper<LongWritable, Text, AvroKey<GenericRecord>, NullWritable> { @Override protected void setup(Mapper<LongWritable, Text, AvroKey<GenericRecord>, NullWritable>.Context context) throws IOException, InterruptedException { //根据user_install_status.avro文件内的格式,生成指定格式的schema对象 schema = parse.parse(Text2Avro.class.getResourceAsStream("/hainiu.avro")); } @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { String line = value.toString(); String[] splits = line.split("\001"); if(splits == null || splits.length != 10){ System.out.println("=============="); System.out.println(value.toString()); context.getCounter("etl_err", "bad line num").increment(1L); return; } // System.out.println(util.getIpArea("202.8.77.12")); String uip1 = splits[0]; String uip =IPUtil.getip(uip1); String datetime = splits[2]; StringBuilder sb=new StringBuilder(datetime); SimpleDateFormat sdf=new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss",Locale.ENGLISH); String sy=sb.toString(); Date myDate = null; try { myDate = sdf.parse(sy); } catch (ParseException e) { // TODO Auto-generated catch block e.printStackTrace(); } SimpleDateFormat sdf2=new SimpleDateFormat("yyyyMMddHHmmss"); //System.out.println(myDate); String format = sdf2.format(myDate); //GET /categories/8?filter=recent&page=12 HTTP/1.1 String url1 = splits[3]; StringBuilder sb2=new StringBuilder(url1); String url = sb2.toString(); String method=""; String top=""; String top1=""; String http=""; if(url!=null) { String[] s = url.split(" "); if(s.length==3) { method=s[0]; http=s[2]; top1=s[1]; if(top1.contains(".")) { context.getCounter("etl_err", "no line num").increment(1L); return; } else { top=top1; } } } String status1 = splits[4]; String status2 = splits[5]; String post = splits[6]; String from = splits[7]; String usagent1 = splits[8]; StringBuilder sb3=new StringBuilder(usagent1); String usagent = sb3.toString(); //根据创建的Schema对象,创建一行的对象 GenericRecord record = new GenericData.Record(Text2Avro.schema); record.put("uip", uip); record.put("datetime", format); record.put("method", method); record.put("http", http); record.put("top", top); record.put("from", from); record.put("status1", status1); record.put("status2", status2); record.put("post", post); record.put("usagent", usagent); context.getCounter("etl_good", "good line num").increment(1L); System.out.println(uip+" "+format+" "+top+" "+from+" "+post+" "+usagent+" "+status1+" "+status2+" "+http); context.write(new AvroKey<GenericRecord>(record), NullWritable.get()); } } @Override public Job getJob(Configuration conf) throws IOException { // // 开启reduce输出压缩 // conf.set(FileOutputFormat.COMPRESS, "true"); // // 设置reduce输出压缩格式 // conf.set(FileOutputFormat.COMPRESS_CODEC, SnappyCodec.class.getName()); Job job = Job.getInstance(conf, getJobNameWithTaskId()); job.setJarByClass(Text2Avro.class); job.setMapperClass(Text2AvroMapper.class); job.setMapOutputKeyClass(AvroKey.class); job.setMapOutputValueClass(NullWritable.class); // 无reduce job.setNumReduceTasks(0); //设置输出的format job.setOutputFormatClass(AvroKeyOutputFormat.class); //根据user_install_status.avro文件内的格式,生成指定格式的schema对象 schema = parse.parse(Text2Avro.class.getResourceAsStream("/hainiu.avro")); //设置avro文件的输出 AvroJob.setOutputKeySchema(job, schema); FileInputFormat.addInputPath(job, getFirstJobInputPath()); FileOutputFormat.setOutputPath(job, getJobOutputPath(getJobNameWithTaskId())); return job; } @Override public String getJobName() { return "etltext2avro"; } }
//Avro2Orc_topic10 package mrrun.hainiuetl; import java.io.IOException; import java.util.regex.Matcher; import java.util.regex.Pattern; import org.apache.avro.Schema; import org.apache.avro.generic.GenericRecord; import org.apache.avro.mapred.AvroKey; import org.apache.avro.mapreduce.AvroJob; import org.apache.avro.mapreduce.AvroKeyInputFormat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hive.ql.io.orc.CompressionKind; import org.apache.hadoop.hive.ql.io.orc.OrcNewOutputFormat; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Writable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import mrrun.base.BaseMR; import mrrun.util.OrcFormat; import mrrun.util.OrcUtil; public class Avro2Orc_topic10 extends BaseMR { public static Schema schema = null; public static Schema.Parser parse = new Schema.Parser(); public static class Avro2OrcMapper extends Mapper<AvroKey<GenericRecord>, NullWritable, NullWritable, Writable>{ OrcUtil orcUtil = new OrcUtil(); @Override protected void setup(Context context) throws IOException, InterruptedException { orcUtil.setWriteOrcInspector(OrcFormat.etlorcSchema_topic10); } @Override protected void map(AvroKey<GenericRecord> key, NullWritable value,Context context) throws IOException, InterruptedException { //得到一行的对象 GenericRecord datum = key.datum(); String uip = (String) datum.get("uip"); String datetime = (String) datum.get("datetime"); //String method = (String) datum.get("method"); //String http = (String) datum.get("http"); String top1 = (String) datum.get("top"); String top=""; String regex="/topics/\\d+"; Pattern pattern=Pattern.compile(regex); Matcher matcher=pattern.matcher(top1); if(matcher.find()) { top=matcher.group(); } else { context.getCounter("etl_err", "notopics line num").increment(1L); return; } //orcUtil.addAttr(uip,datetime,method,http,uid,country,status1,status2,usagent); orcUtil.addAttr(uip,datetime,top); Writable w = orcUtil.serialize(); context.getCounter("etl_good", "good line num").increment(1L); System.out.println(uip+" "+top); context.write(NullWritable.get(), w); } } @Override public Job getJob(Configuration conf) throws IOException { //关闭map的推测执行,使得一个map处理 一个region的数据 conf.set("mapreduce.map.spedulative", "false"); //设置orc文件snappy压缩 conf.set("orc.compress", CompressionKind.SNAPPY.name()); //设置orc文件 有索引 conf.set("orc.create.index", "true"); Job job = Job.getInstance(conf, getJobNameWithTaskId()); job.setJarByClass(Avro2Orc_topic10.class); job.setMapperClass(Avro2OrcMapper.class); job.setMapOutputKeyClass(NullWritable.class); job.setMapOutputValueClass(Writable.class); // 无reduce job.setNumReduceTasks(0); job.setInputFormatClass(AvroKeyInputFormat.class); //根据user_install_status.avro文件内的格式,生成指定格式的schema对象 schema = parse.parse(Avro2Orc_topic10.class.getResourceAsStream("/hainiu.avro")); AvroJob.setInputKeySchema(job, schema); job.setOutputFormatClass(OrcNewOutputFormat.class); FileInputFormat.addInputPath(job, getFirstJobInputPath()); FileOutputFormat.setOutputPath(job, getJobOutputPath(getJobNameWithTaskId())); return job; } @Override public String getJobName() { return "etlAvro2Orc_topic10"; } }
//Text2AvroJob package mrrun.hainiuetl; import java.text.SimpleDateFormat; import java.util.Date; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.mapreduce.Counter; import org.apache.hadoop.mapreduce.CounterGroup; import org.apache.hadoop.mapreduce.Counters; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.jobcontrol.ControlledJob; import org.apache.hadoop.mapreduce.lib.jobcontrol.JobControl; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import mrrun.util.JobRunResult; import mrrun.util.JobRunUtil; public class Text2AvroJob extends Configured implements Tool{ @Override public int run(String[] args) throws Exception { //获取Configuration对象 Configuration conf = getConf(); //创建任务链对象 JobControl jobc = new JobControl("etltext2avro"); Text2Avro avro = new Text2Avro(); //只需要赋值一次就行 avro.setConf(conf); ControlledJob orcCJob = avro.getControlledJob(); Job job = orcCJob.getJob(); job.waitForCompletion(true); JobRunResult result = JobRunUtil.run(jobc); result.setCounters("etl1", orcCJob.getJob().getCounters()); result.print(true); Counters counterMap = result.getCounterMap("etl1"); CounterGroup group1 = counterMap.getGroup("etl_good"); CounterGroup group2 = counterMap.getGroup("etl_err"); Counter good = group1.findCounter("good line num"); Counter bad = group2.findCounter("bad line num"); System.out.println("\t\t"+good.getDisplayName()+" = "+good.getValue()); System.out.println("\t\t"+bad.getDisplayName()+" = "+bad.getValue()); System.out.println("=======+++++++++===="); Date date=new Date(); SimpleDateFormat sdf3=new SimpleDateFormat("yyyyMMdd"); String format2 = sdf3.format(date); Results results=new Results(); long bad_num = bad.getValue(); long good_num = good.getValue(); long total_num=bad_num+good_num; results.setBad_num(bad_num); results.setGood_num(good_num); results.setTotal_num(total_num); results.setDay(format2); double d=bad_num*1.0/total_num*1.0; results.setBad_rate(d); System.out.println((double)((double)bad_num/(double)total_num)); DAO dao=new DAO(); if(dao.getday(format2)!=null) { Results getday = dao.getday(format2); Long bad_num2 = getday.getBad_num(); Long good_num2 = getday.getGood_num(); Long total_num2 = getday.getTotal_num(); getday.setDay(format2); getday.setBad_num(bad_num2+bad_num); getday.setGood_num(good_num2+good_num); getday.setTotal_num(total_num2+total_num); double badrate=(bad_num2+bad_num)*1.0/(total_num2+total_num)*1.0; getday.setBad_rate(badrate); dao.update(getday); } else { dao.insert(results); } jobc.addJob(orcCJob); return 0; } public static void main(String[] args) throws Exception { // -Dtask.id=1226 -Dtask.input.dir=/tmp/avro/input_hainiuetl -Dtask.base.dir=/tmp/avro System.exit(ToolRunner.run(new Text2AvroJob(), args)); } }
放一个
直接放代码
yitiaolong.sh #!/bin/bash source /etc/profile mmdd=`date -d 1‘ days ago‘ +%m%d` yymm=`date -d 1‘ days ago‘ +%Y%m` dd=`date -d 1‘ days ago‘ +%d` /usr/local/hive/bin/hive -e "use suyuan09;alter table etlavrosy add IF NOT EXISTS partition(month=‘${yymm}‘,day=‘${dd}‘);" /usr/local/hive/bin/hive -e "use suyuan09;alter table hainiuetltopics10_orc add IF NOT EXISTS partition(month=‘${yymm}‘,day=‘${dd}‘);" /usr/local/hive/bin/hive -e "use suyuan09;alter table hainiuetlcategories10_orc add IF NOT EXISTS partition(month=‘${yymm}‘,day=‘${dd}‘);" /usr/local/hive/bin/hive -e "use suyuan09;alter table hainiuetlspider_orc add IF NOT EXISTS partition(month=‘${yymm}‘,day=‘${dd}‘);" /usr/local/hive/bin/hive -e "use suyuan09;alter table hainiuetlip_orc add IF NOT EXISTS partition(month=‘${yymm}‘,day=‘${dd}‘);" /usr/local/hive/bin/hive -e "use suyuan09;alter table hainiuetlindex5_orc add IF NOT EXISTS partition(month=‘${yymm}‘,day=‘${dd}‘);" #3-4运行mr hdfs_path1=/user/hainiu/data/hainiuetl/input/${yymm}/${dd} avro_path1=/user/suyuan09/hainiuetl/hainiuavro/${yymm}/${dd} `/usr/local/hadoop/bin/hadoop jar /home/suyuan09/etl/hainiu/jar/181210_hbase-1.0.0-symkmk123.jar etltext2avro -Dtask.id=${mmdd} -Dtask.input.dir=${hdfs_path1} -Dtask.base.dir=${avro_path1}` #orctopics10mr.sh avro_path2=/user/suyuan09/hainiuetl/hainiuavro/${yymm}/${dd}/etltext2avro_${mmdd}/part-*.avro orc_path2=/user/suyuan09/hainiuetl/orctopics10/${yymm}/${dd} `/usr/local/hadoop/bin/hadoop jar /home/suyuan09/etl/hainiu/jar/181210_hbase-1.0.0-symkmk123.jar etlavro2orc_topic10 -Dtask.id=${mmdd} -Dtask.input.dir=${avro_path2} -Dtask.base.dir=${orc_path2}` #orccategories10mr.sh avro_path3=/user/suyuan09/hainiuetl/hainiuavro/${yymm}/${dd}/etltext2avro_${mmdd}/part-*.avro orc_path3=/user/suyuan09/hainiuetl/orccategories10/${yymm}/${dd} `/usr/local/hadoop/bin/hadoop jar /home/suyuan09/etl/hainiu/jar/181210_hbase-1.0.0-symkmk123.jar etlavro2orc_categories10 -Dtask.id=${mmdd} -Dtask.input.dir=${avro_path3} -Dtask.base.dir=${orc_path3}` #orcspidermr.sh avro_path4=/user/suyuan09/hainiuetl/hainiuavro/${yymm}/${dd}/etltext2avro_${mmdd}/part-*.avro orc_path4=/user/suyuan09/hainiuetl/orcspider/${yymm}/${dd} `/usr/local/hadoop/bin/hadoop jar /home/suyuan09/etl/hainiu/jar/181210_hbase-1.0.0-symkmk123.jar etlavro2orc_spider -Dtask.id=${mmdd} -Dtask.input.dir=${avro_path4} -Dtask.base.dir=${orc_path4}` #orcipmr.sh avro_path5=/user/suyuan09/hainiuetl/hainiuavro/${yymm}/${dd}/etltext2avro_${mmdd}/part-*.avro orc_path5=/user/suyuan09/hainiuetl/orcip/${yymm}/${dd} `/usr/local/hadoop/bin/hadoop jar /home/suyuan09/etl/hainiu/jar/181210_hbase-1.0.0-symkmk123.jar etlavro2orc_ip -Dtask.id=${mmdd} -Dtask.input.dir=${avro_path5} -Dtask.base.dir=${orc_path5}` #orcindex5mr.sh avro_path6=/user/suyuan09/hainiuetl/hainiuavro/${yymm}/${dd}/etltext2avro_${mmdd}/part-*.avro orc_path6=/user/suyuan09/hainiuetl/orcindex5/${yymm}/${dd} `/usr/local/hadoop/bin/hadoop jar /home/suyuan09/etl/hainiu/jar/181210_hbase-1.0.0-symkmk123.jar etlavro2orc_index5 -Dtask.id=${mmdd} -Dtask.input.dir=${avro_path6} -Dtask.base.dir=${orc_path6}` #把orc挪到分区目录 #orc2etl.sh /usr/local/hadoop/bin/hadoop fs -cp hdfs://ns1/user/suyuan09/hainiuetl/orctopics10/${yymm}/${dd}/etlAvro2Orc_topic10_${mmdd}/part-* hdfs://ns1/user/suyuan09/etlorc/hainiuetltopics10_orc/month=${yymm}/day=${dd} /usr/local/hadoop/bin/hadoop fs -cp hdfs://ns1/user/suyuan09/hainiuetl/orccategories10/${yymm}/${dd}/etlAvro2Orc_categories10_${mmdd}/part-* hdfs://ns1/user/suyuan09/etlorc/hainiuetlcategories10_orc/month=${yymm}/day=${dd} /usr/local/hadoop/bin/hadoop fs -cp hdfs://ns1/user/suyuan09/hainiuetl/orcspider/${yymm}/${dd}/etlAvro2Orc_spider_${mmdd}/part-* hdfs://ns1/user/suyuan09/etlorc/hainiuetlspider_orc/month=${yymm}/day=${dd} /usr/local/hadoop/bin/hadoop fs -cp hdfs://ns1/user/suyuan09/hainiuetl/orcindex5/${yymm}/${dd}/etlAvro2Orc_index5_${mmdd}/part-* hdfs://ns1/user/suyuan09/etlorc/hainiuetlindex5_orc/month=${yymm}/day=${dd} /usr/local/hadoop/bin/hadoop fs -cp hdfs://ns1/user/suyuan09/hainiuetl/orcip/${yymm}/${dd}/etlAvro2Orc_ip_${mmdd}/part-* hdfs://ns1/user/suyuan09/etlorc/hainiuetlip_orc/month=${yymm}/day=${dd} #自动从hive到mysql脚本 #hive2data.sh /usr/local/hive/bin/hive -e "use suyuan09;select t.top,t.num from(select top,count(*) num from hainiuetlindex5_orc group by top) t sort by t.num desc limit 5;" > /home/suyuan09/etl/hainiu/orc2mysql/myindex5${yymmdd} /usr/local/hive/bin/hive -e "use suyuan09;select t.top,t.num from(select top,count(*) num from hainiuetltopics10_orc group by top) t sort by t.num desc limit 10;" > /home/suyuan09/etl/hainiu/orc2mysql/mytopics10${yymmdd} /usr/local/hive/bin/hive -e "use suyuan09;select t.top,t.num from(select top,count(*) num from hainiuetlcategories10_orc group by top) t sort by t.num desc limit 10;" > /home/suyuan09/etl/hainiu/orc2mysql/mycategories10${yymmdd} /usr/local/hive/bin/hive -e "use suyuan09;select t.uip,t.num from(select uip,count(*) num from hainiuetlip_orc group by uip) t sort by t.num desc;" > /home/suyuan09/etl/hainiu/orc2mysql/myip${yymmdd} /usr/local/hive/bin/hive -e "use suyuan09;select t.usagent,t.num from(select usagent,count(*) num from hainiuetlspider_orc group by usagent) t sort by t.num desc;" > /home/suyuan09/etl/hainiu/orc2mysql/myspider${yymmdd} #data->mysql脚本 #data2mysql.sh #mysql -h 172.33.101.123 -P 3306 -u tony -pYourPassword -D YourDbName <<EOF /bin/mysql -h192.168.88.195 -p3306 -uhainiu -p12345678 -Dhainiutest <<EOF LOAD DATA LOCAL INFILE "/home/suyuan09/etl/hainiu/orc2mysql/mytopics10${yymmdd}" INTO TABLE suyuan09_etl_orctopics10mysql FIELDS TERMINATED BY ‘\t‘; LOAD DATA LOCAL INFILE "/home/suyuan09/etl/hainiu/orc2mysql/mycategories10${yymmdd}" INTO TABLE suyuan09_etl_orccategories10mysql FIELDS TERMINATED BY ‘\t‘; LOAD DATA LOCAL INFILE "/home/suyuan09/etl/hainiu/orc2mysql/myindex5${yymmdd}" INTO TABLE suyuan09_etl_orcindex5mysql FIELDS TERMINATED BY ‘\t‘; LOAD DATA LOCAL INFILE "/home/suyuan09/etl/hainiu/orc2mysql/myspider${yymmdd}" INTO TABLE suyuan09_etl_orcspidermysql FIELDS TERMINATED BY ‘\t‘; LOAD DATA LOCAL INFILE "/home/suyuan09/etl/hainiu/orc2mysql/myip${yymmdd}" INTO TABLE suyuan09_etl_orcipmysql FIELDS TERMINATED BY ‘\t‘; EOF
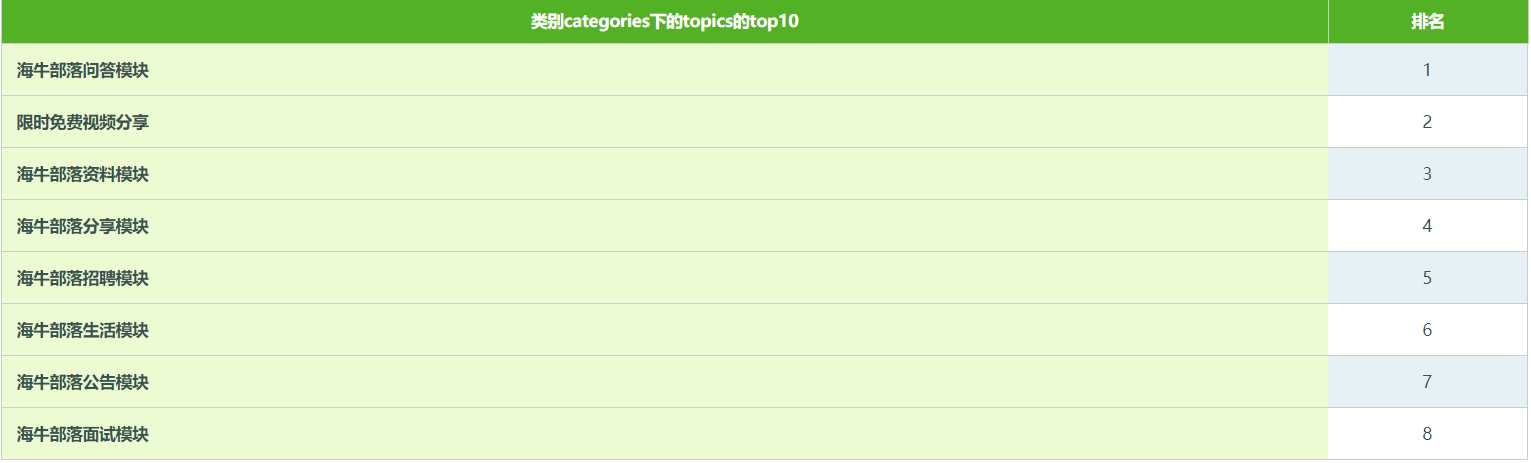

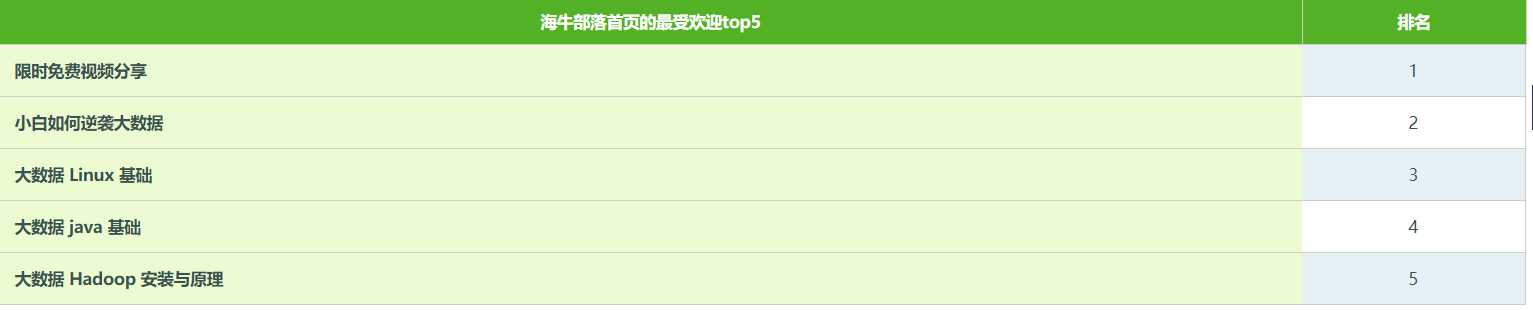
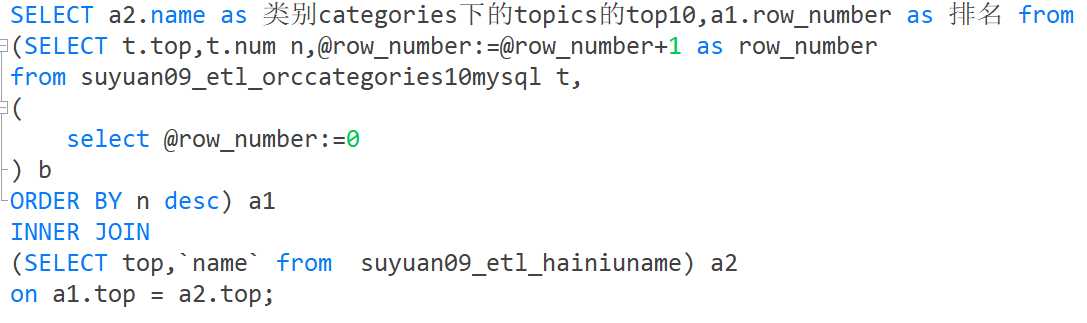
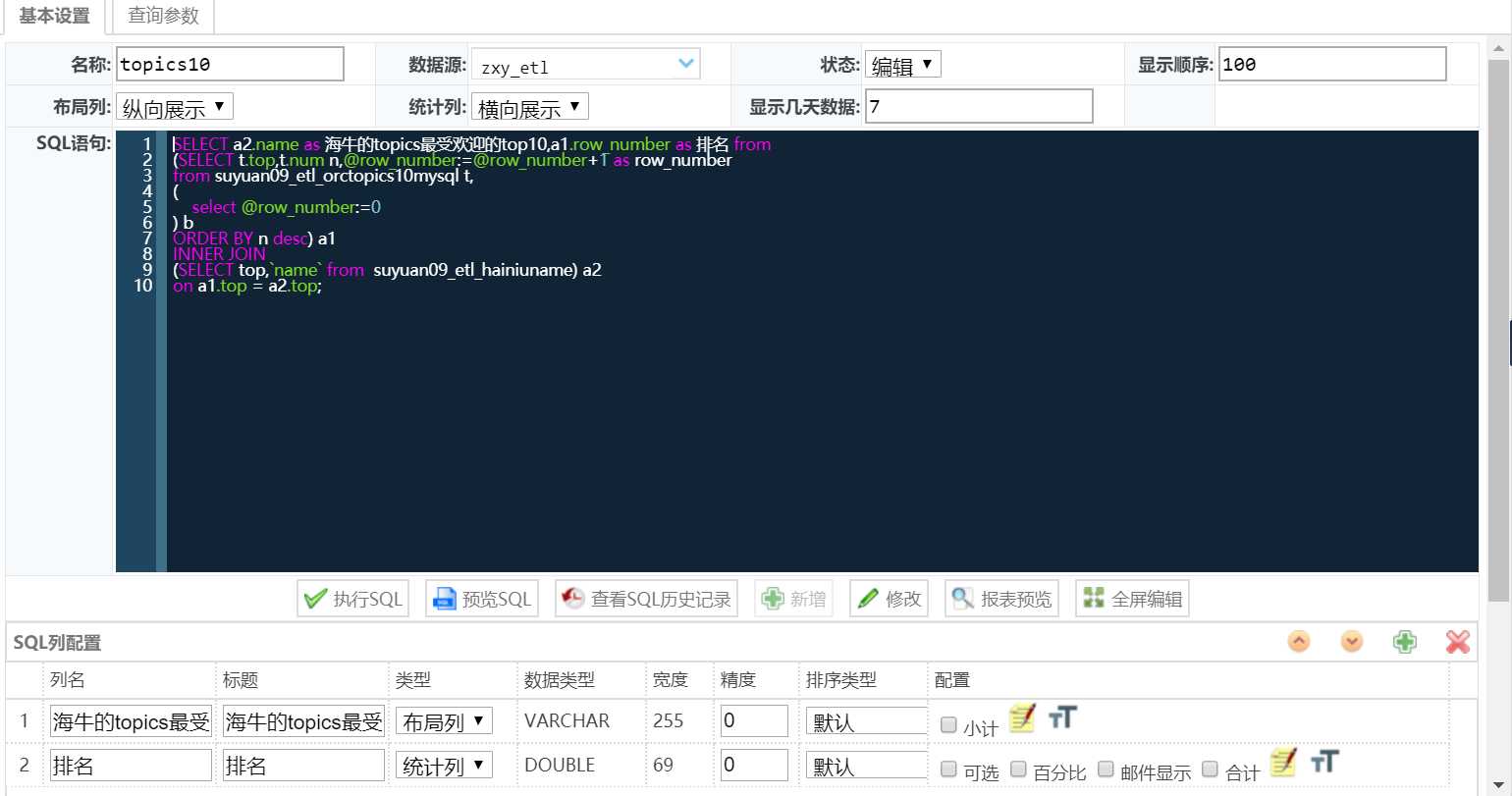
其中 mysql没有自带排序函数,自己写一个
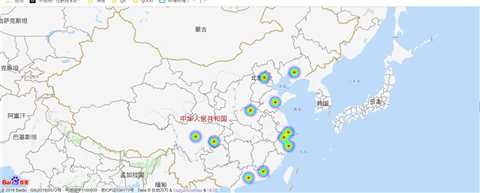
热力图参考之前我之前的博客 https://www.cnblogs.com/symkmk123/p/9309322.html
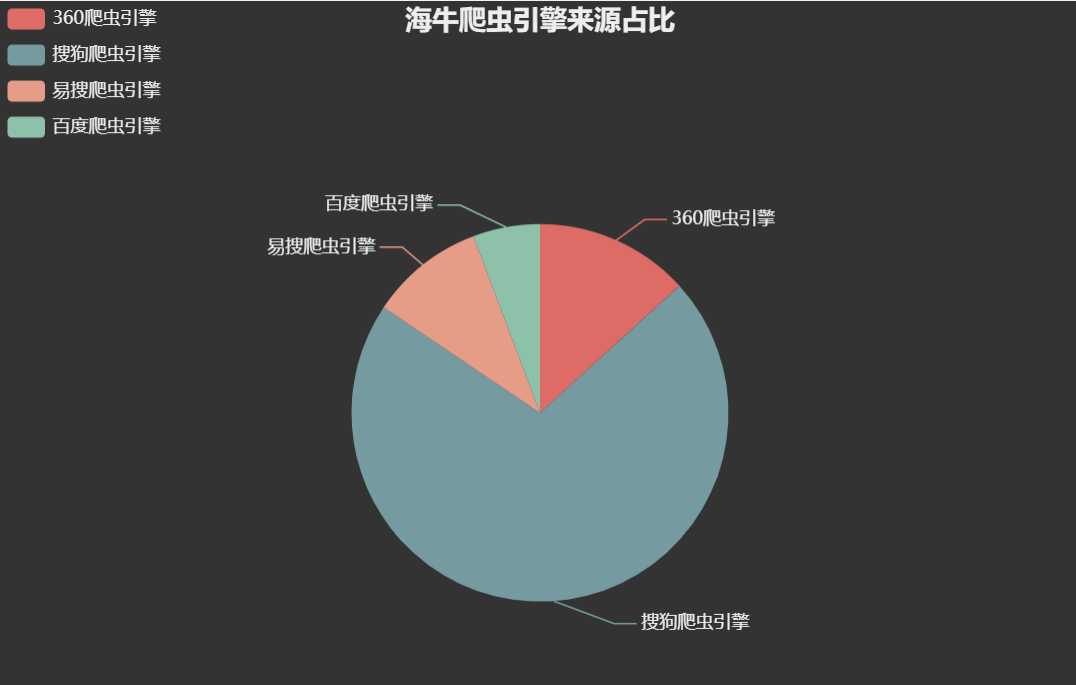
图表也参考我之前的博客 https://www.cnblogs.com/symkmk123/p/9010514.html
ETL项目2:大数据清洗,处理:使用MapReduce进行离线数据分析并报表显示完整项目
标签:password day 执行 技术 hba tls match apache mys
原文地址:https://www.cnblogs.com/symkmk123/p/10197633.html