标签:贪婪 match 意思 span 代码 对象 分组 多个 扩展
?. 正则表达式
正则表达式,一个让人爱恨难分的东西,会的人,希望所有代码都是用正则表达。不懂的人,会想世界上怎么会有这种语言。但是有些地方使用正则的确是方便,例如,验证手机号,邮箱身份证等。再加以扩展,还可以做爬虫。开始学起来(http://tool.chinaz.com/regex/ 可以去这个网站,进行测试,看看自己写的正则对不对)。
1. 字符组
字符组很简单?[]括起来. 在[]中出现的内容会被匹配. 例如:[abc] 匹配a或b或c如果字符组中的内容过多还可以使?- , 例如: [a-z] 匹配a到z之间的所有字? [0-9]匹配所有阿拉伯数字。
思考: [a-zA-Z0-9]匹配的是什么?
2. 简单元字符
基本的元字符. 这个东??上?搜??堆. 但是常?的就那么?个:
. 匹配除换?符以外的任意字符
\w 匹配字?或数字或下划线 \s 匹配任意的空?符 \d 匹配数字 \n 匹配?个换?符 \t 匹配?个制表符 \b 匹配?个单词的结尾 ^ 匹配字符串的开始 $ 匹配字符串的结尾 \W 匹配?字?或数字或下划线 \D 匹配?数字 \S 匹配?空?符 a|b 匹配字符a或字符b () 匹配括号内的表达式,也表示?个组 [...] 匹配字符组中的字符 [^...] 匹配除了字符组中字符
3. 量词
我们到?前匹配的所有内容都是单??字符号. 那如何?次性匹配很多个字符呢,我们要?到量词
* 重复零次或更多次
+ 重复?次或更多次
? 重复零次或?次
{n} 重复n次
{n,} 重复n次或更多次
{n,m} 重复n到m次
4. 惰性匹配和贪婪匹配
在量词中的*, +,{} 都属于贪婪匹配. 就是尽可能多的匹配到结果.
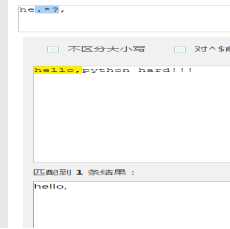
上面就是在chinaz上验证的结果,正则表达式是:”he.*?,”,这个表达式的意思是,he开始,然后点表示不管是啥都要,接着是*,表示尽可能多的选择,接着是?,表示的是,尽可能少的选择,最后要以“,”结束,如果没有这个逗号,那么选择后的结果就是he了。可以尝试一下。
(1).*表示的就是贪婪匹配,要尽可能多的匹配
(2).*?表示的就是惰性匹配,尽可能少的匹配
5. 分组
在正则中使?()进?分组. 比如. 我们要匹配?个相对复杂的?份证号. ?份证号分成两种. 老的?份证号有15位. 新的?份证号有18位. 并且新的?份证号结尾有可能是x.看一个正 则表达式:
^([1-9]\d{16}[0-9x]|[1-9]\d{14})$
6. 转义
在正则表达式中, 有很多有特殊意义的是元字符, ?如\n和\s等,如果要在正则中匹配正常的"\n"?不是"换?符"就需要对"\"进?转义, 变成‘\\‘.在python中, ?论是正则表达式, 还
是待匹配的内容, 都是以字符串的形式出现的, 在字符串中\也有特殊的含义, 本身还需要转义. 所以如果匹配?次"\n", 字符串中要写成‘\\n‘, 那么正则?就要写成
?. re模块
re模块是python提供的?套关于处理正则表达式的模块. 核?功能有四个:
1. findall 查找所有. 返回list
lst = re.findall("m", "mai le fo leng")
print(lst) # [‘m‘]
lst = re.findall(r"\d+", "5点之前. 你要写完5000字")
print(lst) # [‘5‘, ‘5000‘]
2. search 会进?匹配. 如果匹配到了第?个结果. 就会返回这个结果. 如果匹配不上,search返回的则是None。
ret = re.search(r‘\d‘, ‘5点之前. 你要写完5000字‘).group() print(ret) # 5
3. match 只能从字符串的开头进?匹配
ret = re.match(‘a‘, ‘abc‘).group() print(ret) # a
4.finditer 和findall差不多. 只不过这时返回的是迭代器
it = re.finditer("m", "mai le fo leng")
for el in it:
print(el.group()) # 依然需要分组
5.其他操作
ret = re.split(‘[ab]‘, ‘qwerafjbcd‘) # 先按‘a‘分割得到‘qwer‘和‘fjbcd‘,在对‘qwer‘和‘fjbcd‘分别按‘b‘分割
print(ret) # [‘qwer‘, ‘fj‘, ‘cd‘]
ret = re.sub(r"\d+", "_sd_", "aaa250bbb250ccc250ddd38") # 把字符串中的数字换成__sd__
print(ret) # aaa_sd_bbb_sd_ccc_sd_ddd_sd_
ret = re.subn(r"\d+", "_sd_", "aaa250bbb250ccc250ddd38") # 将数字替换成‘__sd__‘,返回元组(替换的结果,替换了多少次)
print(ret) # (‘aaa_sd_bbb_sd_ccc_sd_ddd_sd_‘, 4)
obj = re.compile(r‘\d{3}‘) # 将正则表达式编译成为?个 正则表达式对象, 规则要匹配的是3个数字
ret = obj.search(‘abc123eeee‘) # 正则表达式对象调?search, 参数为待匹配的字符串
print(ret.group()) # 结果: 123
6. 两个坑
注意: 在re模块中和我们在线测试?具中的结果可能是不?样的.
ret = re.findall(‘www.(baidu|abc).com‘, ‘www.abccom‘) print(ret) # [‘abc‘] 这是因为findall会优先把匹配结果组?内容返回,如果想要匹配结果,取消权限即可 ret = re.findall(‘www.(?:baidu|abc).com‘, ‘www.abc.com‘) print(ret) # [‘www.abc.com‘]
这里的“?:”作用是,取消单独获取某些匹配的内容的权限。其实,如果没有必要,可以直接把“baidu|abc”外层的小括号去掉即可。之所以有这个的存在,也是有道理的。看下面的图:
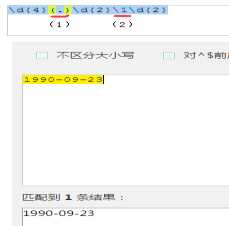
在最上面的正则表达式中,(2)处会跟着(1)的变化而变化,某种情况下(1)这里不需要了,所以就用“?:”给屏蔽掉。
标签:贪婪 match 意思 span 代码 对象 分组 多个 扩展
原文地址:https://www.cnblogs.com/asia-yang/p/10197888.html