标签:coding fail 故障 配额 运维监控 head ganglia back 完全
Kubernetes集群包含有节点代理kubelet和Master组件(APIs, scheduler, etc),一切都基于分布式的存储系统
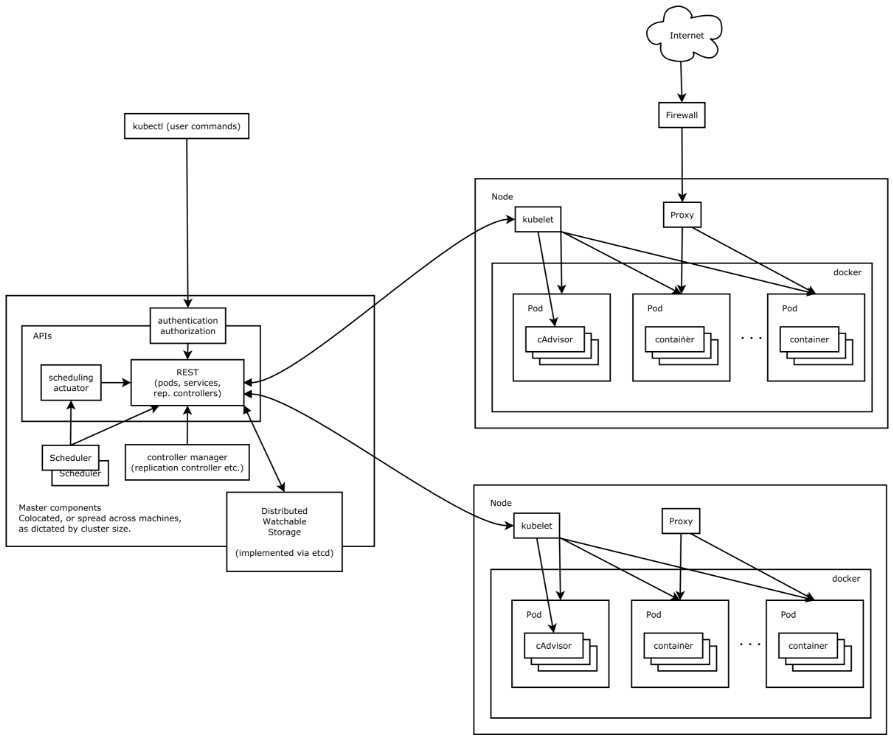
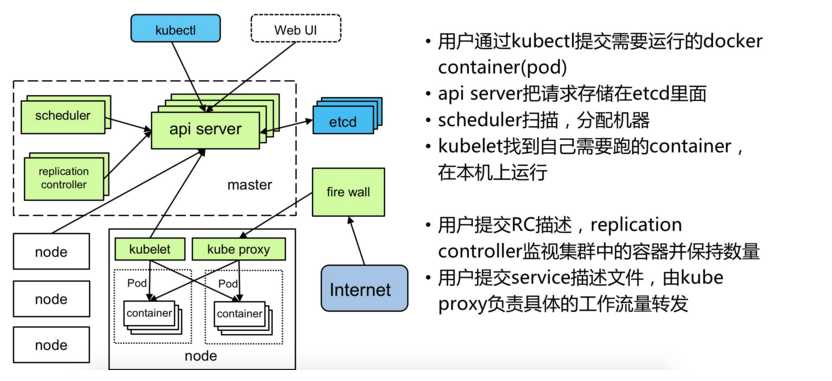
以下是摘自 凌风探梅的总结
Kubernetes主要由以下几个核心组件组成:
# yaml格式的pod定义文件完整内容:
apiVersion: v1 #必选,版本号,例如v1
kind: Pod #必选,Pod
metadata: #必选,元数据
name: string #必选,Pod名称
namespace: string #必选,Pod所属的命名空间
labels: #自定义标签
- name: string #自定义标签名字
annotations: #自定义注释列表
- name: string
spec: #必选,Pod中容器的详细定义
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [Always | Never | IfNotPresent] #获取镜像的策略 Alawys表示下载镜像 IfnotPresent表示优先使用本地镜像,否则下载镜像,Nerver表示仅使用本地镜像
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: volumestring #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口号名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存清楚,容器启动的初始可用数量
livenessProbe: #对Pod内个容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方法有exec、httpGet和tcpSocket,对一个容器只需设置其中一种方法即可
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged:false
restartPolicy: [Always | Never | OnFailure]#Pod的重启策略,Always表示一旦不管以何种方式终止运行,kubelet都将重启,OnFailure表示只有Pod以非0退出码退出才重启,Nerver表示不再重启该Pod
nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上,以key:value的格式指定
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork:false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: columestring #共享存储卷名称 (volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secre对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string
Node
复制控制器(Replication Controller,RC)
Replication Controller用来管理Pod的副本,保证集群中存在指定数量的Pod副本,是实现弹性伸缩、动态扩容和滚动升级的核心。
随后可以通过Label Selector(标签选择器)查询和筛选拥有某些Label的资源对象,Kubernetes通过这种方式实现了类似SQL的简单又通用的对象查询机制
1.kube-Controller进程通过资源对象RC上定义Label Selector来筛选要监控的Pod副本的数量,从而实现副本数量始终符合预期设定的全自动控制流程
2.kube-proxy进程通过Service的Label Selector来选择对应的Pod,自动建立起每个Service岛对应Pod的请求转发路由表,从而实现Service的智能负载均衡
3.通过对某些Node定义特定的Label,并且在Pod定义文件中使用Nodeselector这种标签调度策略,kuber-scheduler进程可以实现Pod”定向调度“的特性
Label
Label是Replication Controller和Service运行的基础,二者通过Label来进行关联Node上运行的Pod。
Service
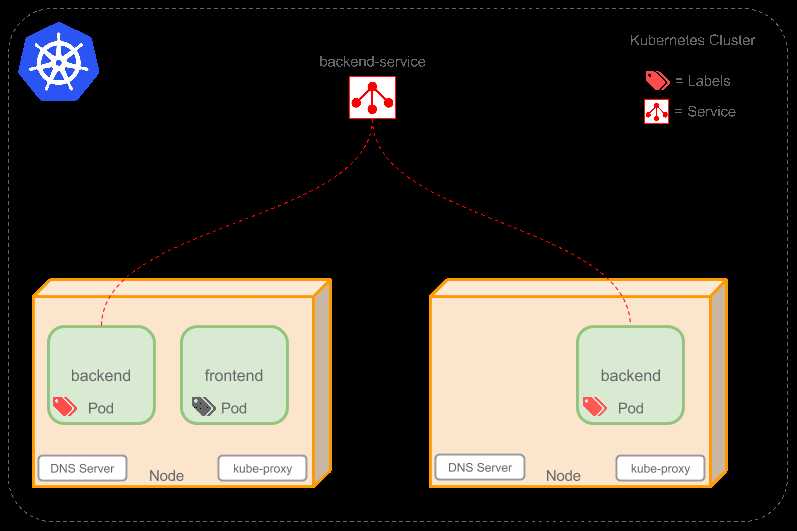
Service是定义一系列Pod以及访问这些Pod的策略的一层抽象。Service通过Label找到Pod组
2个后台Pod,定义后台Service的名称为‘backend-service’,
lable选择器为(tier=backend, app=myapp)。backend-service 的Service会完成如下两件重要的事情:
1.会为Service创建一个本地集群的DNS入口,因此前端Pod只需要DNS查找主机名为 ‘backend-service’,就能够解析出前端应用程序可用的IP地址。
2.现在前端已经得到了后台服务的IP地址,但是它应该访问2个后台Pod的哪一个呢?Service在这2个后台Pod之间提供透明的负载均衡,会将请求分发给其中的任意一个(如下面的动画所示)。通过每个Node上运行的代理(kube-proxy)完成.
Deployment
Deployment为Pod和Replica Set(下一代Replication Controller)提供声明式更新,只需要在Deployment中描述你想要的目标状态是什么,Deployment controller就会帮你将Pod和Replica Set的实际状态改变到你的目标状态
一个典型的用例如下:
Ingress
service和pod的IP仅可在集群内部访问。集群外部的请求需要通过负载均衡转发到service在Node上暴露的NodePort上,然后再由kube-proxy将其转发给相关的Pod。而Ingress就是为进入集群的请求提供路由规则的集合
Ingress可以给service提供集群外部访问的URL、负载均衡、SSL终止、HTTP路由等。为了配置这些Ingress规则,集群管理员需要部署一个Ingress controller,它监听Ingress和service的变化,并根据规则配置负载均衡并提供访问入口。
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: test
spec:
rules:
- host: foo.bar.com
http:
paths:
- path: /foo
backend:
serviceName: s1
servicePort: 80
- path: /bar
backend:
serviceName: s2
servicePort: 80
Volume
Secrets
echo -n "root" | base64 cm9vdA==
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
password: MWYyZDFlMmU2N2Rm
username: YWRtaW4=
创建好secret之后,有两种方式来使用它:
将Secret挂载到Volume中
apiVersion: v1
kind: Pod
metadata:
labels:
name: db
name: db
spec:
volumes:
- name: secrets
secret:
secretName: mysecret 创建的secrect名字
containers:
- image: gcr.io/my_project_id/pg:v1
name: db
volumeMounts:
- name: secrets
mountPath: "/etc/secrets"
readOnly: true
ports:
- name: cp
containerPort: 5432
hostPort: 5432
将Secret导出到环境变量中
env:
- name: WORDPRESS_DB_USER
valueFrom:
secretKeyRef:
name: mysecret
key: username
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
ConfigMap 容器应用的配置管理
ConfigMap可以通过多种方式在Pod中使用,比如设置环境变量、设置容器命令行参数、在Volume中创建配置文件等。
创建一个配置文件 并将配置引入pod
apiVersion: v1 kind: ConfigMap metadata: name: cm-appvars data: key-serverxml: <?xml Version=‘1.0‘encoding=‘utf-8‘?> <Server port="8005"shutdown="SHUTDOWN"> ..... </service> </Server> key-loggingproperties: "handlers=lcatalina.org.apache.juli.FileHandler, ...."
volumeMounts:
- name: serverxml #引用volume名
mountPath:/configfiles #挂载到容器内部目录
configMap:
name: cm-test-appconfigfile #使用configmap定义的的cm-appconfigfile
items:
- key: key-serverxml #将key=key-serverxml
path: server.xml #value将server.xml文件名进行挂载
- key: key-loggingproperties #将key=key-loggingproperties
path: logging.properties #value将logging.properties文件名进行挂载
健康检查的三种方式

spec:
containers:
- name: tomcat
image: grc.io/google_containers/tomcat
args: 配置一个命令,健康检查执行
-/bin/sh
- -c
-echo ok >/tmp.health;sleep10; rm -fr /tmp/health;sleep600
livenessProbe:
exec:
command:
-cat
-/tmp/health
initianDelaySeconds:15
timeoutSeconds:1
livenessProbe:
tcpSocket:
port: 80
initianDelaySeconds:30
timeoutSeconds:1
livenessProbe:
httpGet:
path:/_status/healthz
port: 80
initianDelaySeconds:30
timeoutSeconds:1
initialDelaySeconds:启动容器后首次监控检查的等待时间,单位秒
timeouSeconds:健康检查发送请求后等待响应的超时时间,单位秒。当发生超时就被认为容器无法提供服务无,该容器将被重启
NodeSelector:定向调度
给node打上标签 kubectl label nodes k8s-node-1 label1=test
nodeSelector:
label1: test
kubectl get namespaces
kubectl create namespace new-namespace
kubectl get pods -l label名 -n namespace名
kubectl scale deployment nginx-deployment --replicas 10 扩容
kubectl set image deployment/nginx-deployment nginx=nginx:1.9.1 更新镜像部署
kubectl edit deployment/nginx-deployment
kubectl create -f deployment.yaml文件 -n 命名空间
kubectl delete pods pods名称
kubectl get svc -n 名称 -o 样式 | 附加范围
kubectl delete pods,services -l name=myLabel(标签) --include-uninitialized(包含尚未初始化的)
kubectl exec -it pod名 /bin/bash -n 命名空间
kubectl rollout history deployment/deployment名称 -n --revision=版本号 查看提交历史
kubectl rollout history deployment/deployment名称 -n
kubectl rollout undo deployment/deployment名称 --to-revision=版本号 -n
kubectl rolling-update redis-master --image=redis-master:2.0 升级内部镜像
kubectl get pods --show-labels
kubectl rollout status deployment/nginx-deployment 监控回撤状态
kubectl describe deployment 部署名 -n 空间 查看详细
kubectl set resources deployment nginx -c=nginx --limits=cpu=200m,memory=512Mi
kubectl get deployment pod名 -o yaml -n 查看部署文件
创建环境变量 将常量参数写入其中
kubectl create configmap env-config --from-literal=log_level=INFO
kubectl logs volume-pod -c busybox
标签:coding fail 故障 配额 运维监控 head ganglia back 完全
原文地址:https://www.cnblogs.com/mxz1994/p/10196946.html
