标签:文件夹 时间 读取 线程 基于 type 消息 分享 长度
1. Kafka的经典架构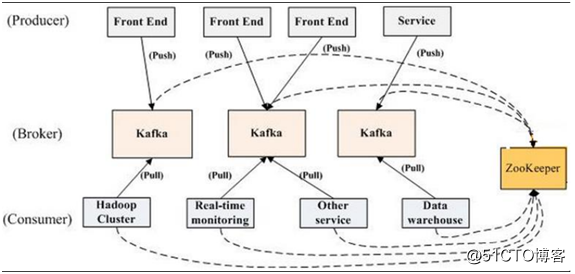
Kafka是LinkedIn 用于日志处理的分布式消息队列,同时支持离线和在线日志处理。
Kafka 对消息保存时根据 Topic 进行归类。
发送消息者就是Producer,消息的发布描述为Producer
消息接受者就是 Consumer,消息的订阅描述为 Consumer
每个 Kafka 实例称为 Broker,将中间的存储阵列称作 Broker(代理),Broker也是kafka集群的节点
kafka集群包括一个或者多个服务器,这种服务器被称为brker。
broker也就是中间的存储队列的节点实例。我们将消息发布者称为:Produce,将消息的订阅者称为:Consumer,将中间的存储阵列称为broker。
每条发布到kafka集群的消息都有一个类别,这个类别被成为Tpoic。物理上不同的topic的消息分开存储,逻辑上一个topic的消息虽然保存与一个或者多个broker中。但用户只需要指定消费的topic,即生产或者消费数据的客户端不需要关心数据存储与何处。
kafka中发布订阅的对象就是topic。为每一个数据类型创建一个topic,把向topic发布消息的客户端称为producer,从topic订阅消息的客户端称为consumer,producer和consumer可以同时从多个topic读写数据。一个kafka集群由一个或者多个broker服务器组成。他负责持久化和备份具体的kafka消息。
topic就是数据的主题,是数据记录发布的地方,可以用来区分业务系统。kafka中的topics总是多订阅者模式,一个topic可以拥有一个或者多个消费者来订阅它的数据。
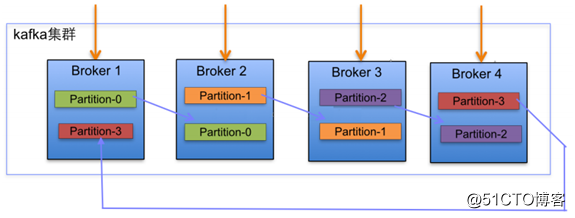
partition是物理的概念,每一个topic包含一个或者多个partition。
topic的分区策略(针对写数据的时候进行分区):
- 轮询:顺序分发,仅针对于message没有key的时候。
- Hash分区:在message有key的情况下,(key.hash%分区个数)。如果在增加分区的时候,partition里面的message不会重新进行分配,随着数据的继续写入,这个新的分区才会参与load balance。
topic的分区逻辑存储方式: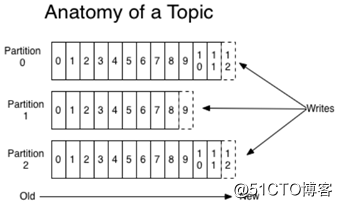
topic 会分成一个或多个 partition,每个 partiton 相当于是一个 子 queue。在物理结构上,每个 partition 对应一个物理的目录(文件夹),文件夹命名是 [topicname][partition][序号],一个 topic 可以有无数多的 partition,根据业务需求和数据量 来设置。在 kafka 配置文件中可随时更高 num.partitions 参数来配置更改 topic 的 partition 数 量,在创建 Topic 时通过参数指定 parittion 数量。Topic 创建之后通过 Kafka 提供的工具也可以修改 partiton 数量。分区中存放着数据本身和数据的index下标。在向partition写入数据的时候,是顺序写入的,每一个数据写入的时候都会有一个类似下标的东西(index),随着数据的写入而增长。partition也是集群负载均衡的基本单位。
总结:
- 一个topic的partition数量大于等于broker的数量,可以提高吞吐率。
- 同一个partition的Replica尽量分散到不同的机器上,高可用。
- kafka的分区数:(1|2|3 + 0.95) * broker数量
负责主动发布消息到kakfa broker(push)
kafka消息的保存策略:每个 Topic 被分成多个 partition(区)。每条消息在 partition 中的位置称为 offset(偏移量),类型为 long 型数字。消息即使被消费了,也不会被立即删除, 而是根据 broker 里的设置(基于时间存储或者基于大小),保存一定时间后再清除,比如 log 文件设置存储两天,则两天后, 不管消息是否被消费,都清除。
消息消费者,向kafkabroker读取消息的客户端。(pull)
消费消息的策略:(使用的是roundrabin算法):如果有4个分区,现在有三个消费者线程,那么这个三个线程一人分一个分区消费,最后一个分区以轮询的方式,发送给第一个线程消费,如果此时又多加入一个线程,那么就会将第4个分区就分给新加入的线程消费,如果有一个线程退出,那么第三个和第四个分区也会以轮询的方式,发送给第一个线程和第二个线程消费。(kafka内部自动维护这个负载均衡)。
消费的原则:一个consumer对一个partition中的一条数据只需要消费一次,每一个consumer组维护一个下标文件,叫做offset,这个offset用于记录当前的consumer组消费数据的下标,每进行消费一条数据,当前的offset就会递增1(offset之前的数据,都表示已经消费过的数据)。
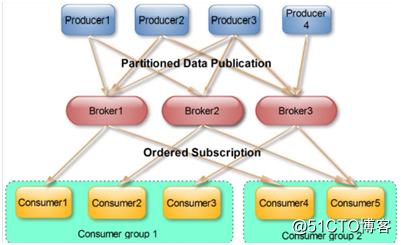
一个consumer group 包含多个consumer,这个是预先在配置文件中配置好的。各个consumer可以组成一个租,partition中的每一个message只能被一个组中的一个consumer进行消费,其他的consumer不能消费同一个topic中同一个分区的数据,不同组的consumer可以消费同一个topic的同一个分区的数据。
广播和单播:
广播:所有的consumer每一个consumer划分一组
单播:所有的consumer划分一组(一组中只允许一个消费)
对于kafka消费的总结:
- 一个分区只能被一个消费者组中的一个成员消费
- 一个成员可以消费一个topic的多个分区
- 一个 Topic 中的每个 Partition 只会被一个“Consumer group”中的一个 Consumer 消费
- 一个成员还可以消费另外一个topic的分区
在kafka文件存储找中,同一个topic下有多个partition,每一个partition为一个目录,partition命名规则为:topic 名称+有序序号,第一个partition序号从0开始,序号最大值为partitions数量-1,partition物理上由多个segment组成,每一个segment存储着多个message信息(默认是:1G),而每一个message是由一个key-value和一个时间戳组成。
segment文件的生命周期由服务器配置参数决定:默认的是168个小时后删除。
segment由两大部分组成: index file 和 data file,这2个文件一一对应,成对出现,后缀".index"和".log"分别表示为 segment 索引文件、数据文件。
segment的命名规则:partion 全局的第一个 segment 从 0 开始,后续每个 segment 文件名为上一个 segment 文件最后一条消息的 offset 值。数值最大为 64 位 long 大小,19 位数字字符长度,没有数字用 0 填充。(每一个partition都是如此)
segment的index file: 索引文件存储大量元数据,数据文件存储大量消息,索引文件中元数据指向对应数据文件中 message 的物理偏移地址。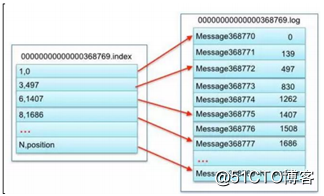
segment的data file: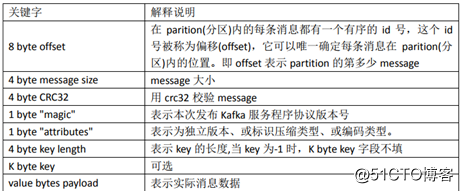
kafka读取数据的查找message的步骤:
以读取 offset=368776 的 message,需要通过下面 2 个步骤查找。
第一步:00000000000000000000.index,表示最开始的文件,起始偏移量(offset)为 0,00000000000000368769.index 的消息量起始偏移量为 368770 = 368769 + 1,00000000000000737337.index 的起始偏移量为 737338=737337 + 1,其他后续文件依次类推。以起始偏移量命名并排序这些文件,只要根据 offset 二分查找文件列表,就可以快速定 位到具体文件。当 offset=368776 时定位到 00000000000000368769.index 和对应 log 文件。
第二步:当 offset=368776 时,依次定位到 00000000000000368769.index 的元数据物理位置和 00000000000000368769.log 的物理偏移地址,然后再通过 00000000000000368769.log 顺序查找直到 offset=368776 为止。查找的时候是通过相对偏移量,在.index文件中有两列(序列,地址),其中序列是相对偏移量:序列=查找的message的偏移量-当前文件的起始偏移量 ,然后根据序列对应的地址,找到相应的位置上的数据message。
标签:文件夹 时间 读取 线程 基于 type 消息 分享 长度
原文地址:http://blog.51cto.com/14048416/2337234