标签:class color 高效 shanghai 空格 使用字符串 常见 most pytho
正则表达式
正则表达式,又称规则表达式。是计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个规则的文本。以往对字符数据处理时通常使用字符串函数,当我们了解正则表达式后,会发现正则表达式简单高效。正则表达式在不同的语言中使用方法不同,本质上区别不大。在Python语言中使用正则时需要导入模块re,下面内容主要概述基本使用方法。
re.match 从字符串的起始位置匹配一个模式,如果起始位置没有匹配成功match()就返回none;如果匹配成功就返回匹配对象Match Object,然后可以通过对象具有的方法group()提前字符串匹配的部分。
re.match(pattern, string, flags=0)
pattern:匹配的正则表达式
string:要匹配的字符串
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等
import re s = "love Python3" result = re.match("lov", s) print(result) print(result.group()) output: <re.Match object; span=(0, 3), match=‘lov‘> lov
常见匹配字符
单字符匹配
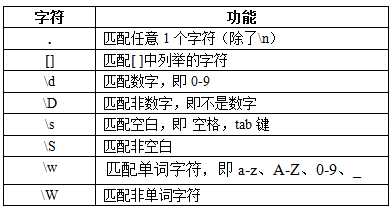
>>> re.match(".","abc").group() ‘a‘ >>> re.match("[aA]","abc").group() ‘a‘ >>> re.match("[0-9]","123abc").group() ‘1‘ >>> re.match("今天\d号","今天3号").group() ‘今天3号‘
匹配多个字符的相关格式---表数量

>>> re.match("[A-Za-z]*","Shanghai").group() ‘Shanghai‘ >>> re.match("[A-Za-z]+\w","Shanghai_55").group() ‘Shanghai_‘ >>> re.match("[A-Za-z]+\w*","Shanghai_55").group() ‘Shanghai_55‘ #匹配0-99 >>> re.match("[1-9]?[0-9]","99").group() ‘99‘ >>> re.match("\w{6}","1343a_de454").group() ‘1343a_‘ >>> re.match("\w{6,9}","1343a_de454").group() ‘1343a_de4‘ >>> re.match("\w{6,}","1343a_de454").group() ‘1343a_de454‘
边界匹配

>>> re.match(".*\\bllo\\b","he llo world").group() ‘he llo‘ >>> re.match(r".*\bllo\b","he llo world").group() ‘he llo‘
在正则表达式中“\”通常作为转义字符出现,如单词边界分隔符"\b",在使用时需要双\\。如果出现多个反斜杠岂不是很麻烦,可能造成漏写,因此Python里的原生字符串很好地解决了这个问题,即在字符串前面使用r,这样写出来的表达式更加直观了。
>>> re.match(r".*\bllo\b","hello world").group() Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: ‘NoneType‘ object has no attribute ‘group‘ >>> re.match(r".*\bllo\b","he lloworld").group() Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: ‘NoneType‘ object has no attribute ‘group‘
\b匹配单词边界,要求匹配的字符要么位于首端、末端或者字符两端空格。
>>> re.match(r".*llo\B","lloh").group() ‘llo‘ >>> re.match(r".*\Bllo\B","helloh").group() ‘hello‘ >>> re.match(r".*\Bllo\B","hello").group() Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: ‘NoneType‘ object has no attribute ‘group‘ >>> re.match(r".*\Bllo","llo").group() Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: ‘NoneType‘ object has no attribute ‘group‘
\B匹配非单词边界,要求匹配的字符不能位于首端、末端或者有空格。
匹配分组

#匹配0-100 >>> re.match(r"[1-9]?\d$|100","92").group() ‘92‘ #匹配分组 >>> re.match("([^-]*)-(\d+)","0761-3601110").group() ‘0761-3601110‘ >>> re.match("([^-]*)-(\d+)","0761-3601110").groups() (‘0761‘, ‘3601110‘) >>> re.match("([^-]*)-(\d+)","0761-3601110").group(1) ‘0761‘ >>> re.match("([^-]*)-(\d+)","0761-3601110").group(2) ‘3601110‘
分组匹配:<html><h1>www.baidu.cn</h1></html>
>>> s = "<html><h1>www.baidu.cn</h1></html>" >>> re.match(r"<(\w*)><(\w*)>.*</\2></\1>",s).group() ‘<html><h1>www.baidu.cn</h1></html>‘
前后标签一致可以使用分组(),第一个分组为1,第二个为2,依次类推。
>>> s = "<html><h2>www.baidu.cn</h2></html>" >>> re.match(r"<(?P<lab1>\w*)><(?P<lab2>\w*)>.*</(?P=lab2)></(?P=lab1)>",s).group() ‘<html><h2>www.baidu.cn</h2></html>‘
?P定义分组别名name,?P=为使用分组别名。当使用的分组较多时,用\number不够直观可能会出错,使用分组别名替代\number更加直观可以避免混乱。
标签:class color 高效 shanghai 空格 使用字符串 常见 most pytho
原文地址:https://www.cnblogs.com/jsnhdream/p/10201175.html