标签:空白 跳过 左右 单个字符 ima 语法规则 技术 正则表达 命名
在Java中,借助于String类的一系列方法,我们已经可以对字符串做简单的处理:比如求子串、查找字符、格式化字符串、字符串替换等等。正则表达式则提供了更为强大的对字符串的处理操作,是一种强大而灵活的文本处理工具。
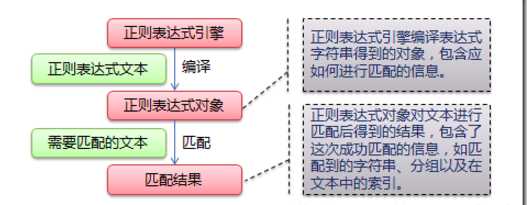
正则表达式对文本的匹配流程如下图所示:
简单的说,正则表达式就是以特定的语法规则描述一个字符串:如果待匹配文本的内容符合正则表达式的内容,则匹配成功;否则匹配失败。
正则表达式的语法
正则表达式的语法主要分为:单个字符、字符集、逻辑操作符、捕获组、数量词、边界匹配符等若干部分。
一、单个字符
1、一般的字符:这里的字符包括字母(大小写)、数字、符号等,语法原则是匹配自身。比如正则表达式为“abc”,那么有且只能是“abc”文本才能匹配成功。
2、任意字符.:.字符语法原则是与任意字符匹配。比如正则文本“a.c”可以匹配“axc”文本。
3、转义字符\:使后面的一个字符具有特定的意义。语法原则与一般的转义字符用法一致,比如"a\.c"则只能与“a.c”匹配。
二、字符集
1、一般字符集[...]:注意,字符集并不表示一个集合全部内容,表示的是这个集合中的任一一个元素的含义。比如,"[abc]"表达的含义与"abc"完全不同,前者表达abc中任一一个字符的含义。一般字符集的语法规则是方括号[ ]内显示地表达元素集合:可以选择逐一列出,如[abcde];还可以选择用-符号表示范围,比如[a-z]表示小写英文字母的集合中的任意一个字符。特别地,如果范围比较分散而元素又太多了不好一一列举,可以取集合中补集的概念,在[ ]中开始位置用^表示“排除”、“取反”、“取补集”的含义,比如[^abc]表示除了abc以外的任意一个字符。
2、预定义字符集:为了方便使用,不需要每次都需要自己用[...]语法表示,正则表达式引擎预先提供了一些字符集,主要有:
①\d:相当于“[0-9]”,即数字字符。
②\s:相当于“[\t\r\n\f]”,即空白字符。
③\w:相当于"[a-zA-Z0-9]",即单词字符。
④以上三种字符集,分别取补集,为了方便记忆用对应大写字母表达,即得到\D(非数字字符) \S(非空白字符) \W(非单词字符)等字符集。
切记:无论是一般字符集[...]还是预定义字符集,表达的都是“一个”字符的概念:一个字符集合中任意一个字符!
三、逻辑操作符
逻辑操作符指的是,如果一个正则表达式中既有字符又有字符集还有其他的语法元素时,这些元素之间的逻辑关系是怎样的。主要有:
1、XY:顺序结构,Y跟在X后面,所以语法原则是先检查X,如果匹配再检查Y。
2、X|Y:“或”关系,左右两个表达式只需要满足一个即表示文本匹配成功。所以,如果X匹配成功,则直接跳过Y的检查。
四、捕获组(capturing group)
捕获组非常容易与字符集混淆:首先,两者形式不同:前者是(...),后者是[...]。然后,两者含义不同:前者表示的是实打实的集合整体,后者则是整体中的任意一个元素。
捕获组语法非常简单:圆括号(...),比如"a(bc)d"只能与"abcd"匹配成功。
切记,正则文本如果使用了捕获组,圆括号是不参与匹配的,它只是正则的语法元素而已!
可以了解一下捕获组几个重要的用法:
①捕获组的编号:捕获组是可以嵌套的,这就像数学表达式中圆括号可以"一对套一对"一样。捕获组可以因此可以编号:编号从0开始(即全部正则文本内容),最外层括号包含的内容为第1组,依次按层次编号即可。比如有一个正则文本"a(b(c)d(e))f",第0组为abcdef,第1组为bcde,第2组为c 和 e。
②捕获组的命名:除了编号外,还可以给捕获组命名,命名语法为:(?P<name>...),其实就是在捕获组内容前面加上?P<name>即可,其中的name即为该组的组名。
捕获组的编号和命名,本质都是为了在一个正则文本中将多个捕获组区分开。那么区分不同的捕获组的意义在哪?就是为了引用捕获组。因为捕获组代表某个字符集合整体,而我们希望正则表达式尽量简洁,所以在不同的地方使用同样的捕获组的时候,用引用代替重复的文本。具体如下:
③捕获组的编号引用:引用语法为"\x". 其中,x为想引用的捕获组编号。比如,对于正则文本"(abc)d\1",“abcdabc”文本才能与它匹配。显然这里\1是对第1组的引用。
④捕获组的名称引用:引用语法为"(?P=name)". 其中,name为引用的捕获组名称,由于捕获组编号是系统自动追加的,而捕获组名称是用户自己添加的,所以必须保证该名称确实被命名一个捕获组过。另外,这里的圆括号与?都不能省略。比如:正则文本"a(?P<happy>bc)d(?P=happy)",与其匹配的文本应当为"abcdbc"。
捕获组相当于将若干个一般字符与其他部分隔离开,但是这种隔离并非是没有意义的;通过这种隔离可以实现特定的匹配含义。稍后,说明这一点。
五、数量词
至此,大家可能会有疑惑:我们目前表示的正则表达式,与其匹配的文本都是唯一确定的,那我们为什么不直接用String表示字符串得了?当有了数量词后,正则表达式才具有了真正的强大的灵活性。数量词可以用于字符(包括单个字符与字符集)后面或者捕获组后面。
如果数量词用于单个字符或字符集后面,这二者表达的都是一个字符的概念,所以数量词作用域为前面这一个字符!如果数量词用于捕获组后面,数量词作用域为整个捕获组整体字符集合。
1、X* 表示X可以出现0次或多次。对于正则文本"ab*",则文本"a"、"ab"、"abb"都可以与其匹配。对于正则文本“a(bc)*”,则文本"a"、"abc"、"abcbc"可以与其匹配。这里的两个例子也刚好可以看出数量词对单个字符/字符集和捕获组的不同作用域(其实只需将捕获组看作是一个整体即可)。
2、X+ 表示X出现一次或多次。
3、X? 表示X出现0次或者1次。
4、{m} 表示X出现m次。
5、{m,n} 表示X出现次数在m到n次之间。若省略m,则变成{,n},表示X出现次数在0到n之间。如果省略n,变成{m,},表示X出现次数在m到无限次之间。注意,省略m或n时,花括号中的逗号切不可省略,否则就变成上一种情况了。
六、边界匹配符
边界匹配符用来控制匹配文本时的匹配位置进一步提升了正则表达式的灵活性,:比如在开头匹配或在末尾匹配等。这里略。
正则表达式具有强大的灵活性,同一个正则文本,可能有多个甚至无数个文本可以与其匹配成功。但是很多情况下,我们不需要这么多匹配成功的文本。这涉及到一个正则匹配“贪婪型”、“非贪婪型”的问题。
正则匹配过程默认是贪婪型的:即贪婪正则表达式会在已经找到一个符号匹配的文本后继续往下吸收文本。
可以手动将正则表达式指定为非贪婪型,方式是在数量词后面加上?。这样非贪婪表达式会匹配满足表达式的最少字符数的文本。即*? +? ?? {m,n}?等。
正则表达式的简单应用
正则表达式对于文本处理而言非常强大,这里只介绍简单的应用。
1、匹配检查:String类的实例方法matchs(String regex)可用来检查字符串是否匹配参数中的正则表达式。
2、字符串分割:String类的实例方法split(String regex)可用来切分字符串,返回一个切分后的字符串数组。该方法遇到符合正则表达式内容的内容时,进行切割,最后结果是忽略了该部分内容,原本的字符串变成一段段的子串,以字符串数组的形式返回。
3、字符串替换:尽管String类已经提供了replace(String target,String replacement)方法用来进行字符串替换的操作。但是使用正则表达式更灵活,主要有以下两种方式:
①replaceAll(String regex,String replacement)
②replaceFirst(String regex,String replacement)
这两种方法都是String类的实例方法,作用都是寻找符合参数一正则表达式内容的部分,用参数二的字符串替换。二者的区别在于后者只替换第一次匹配成功的文本,前者替换全部匹配成功的文本。
————————over。
标签:空白 跳过 左右 单个字符 ima 语法规则 技术 正则表达 命名
原文地址:https://www.cnblogs.com/shakinghead/p/10202497.html