标签:node 指定 体验 解析 ble 不用 单元 info tom
1 XMl: eXtendsible markup language:可扩展的标记语言
作用:
1.保存数据
2.配置文件
3.数据传输载体
2 xml文档结构:倒状树形结构
3 xml文档声明:
<?xml version="1.0" encoding="UTF-8" standalone="no" ?>
version:xml解析器的版本
encoding:用什么编码来解析xml中的内容
standalone:no,关联其他文档。yes,作为独一文档。
4 关于encoding
电脑以二进制的形式存储文字,即存储文字对应的二进制。
编码确定了文字对应的二进制
如果使用GBK编码保存,让encoding也是GBK,或者gb2312。UTF-8也一样。
保存的时候见到ANSI,对应的是本地编码,GBK。
5 xml文件定义
元素定义:<>括起来的都是元素。或者叫标签,成对出现。
根元素(标签):文档声明下的第一个元素叫做根元素。
空标签:即是开始也是结束,一般配合属性来用。比如<age/>
标签可以自定义
标签的命名规则:不能以数字、标点符号开始。尽量见名知意
6 xml属性定义
简单元素:元素里面只有文字
复杂元素:元素里面嵌套了其他元素
7 xml注释: <!-- -->,不允许放在文档第一行
8 xml的CDATA区
如果某段字符串有过多字符,并且里面包含里类似标签、关键字,那么使用CDATA来包装
在服务器给客户端返回数据的时候可能用到。
<![CDATA[<a href="baidu.com">123</a>]]>:a标签变成文字不被解析
C:Character
转义字符:非法的xml字符的引用,比如<代替<
9 (面)xml的解析方式: 常用的有两种DOM\SAX
DOM: document Object model
DOM:把xml全部读到内存,形成一个树状结构。整个文档称之为document对象。
Node结点:document文档对象、element元素对象、attribute属性对象、text文本对象
SAX: Simple API For XMl
SAX : 基于事件驱动,读取一行,解析一行

区别:
DOM可以对文档进行增删。SAX不能增删,只能查询。
如果xml特别大,那么会DOM造成内存溢出,SAX不会出现这种情况。
10 针对以上两种解析方式给出的解决方案有哪些?
dom4j:比较广泛
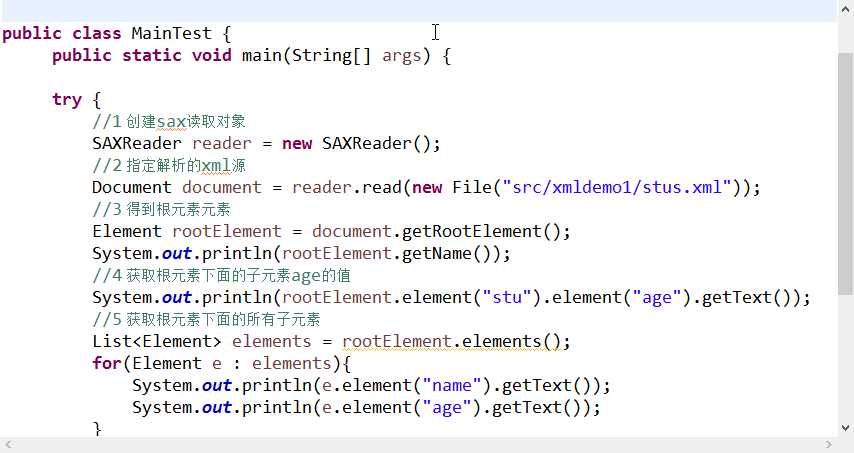
11 dom4j入门:
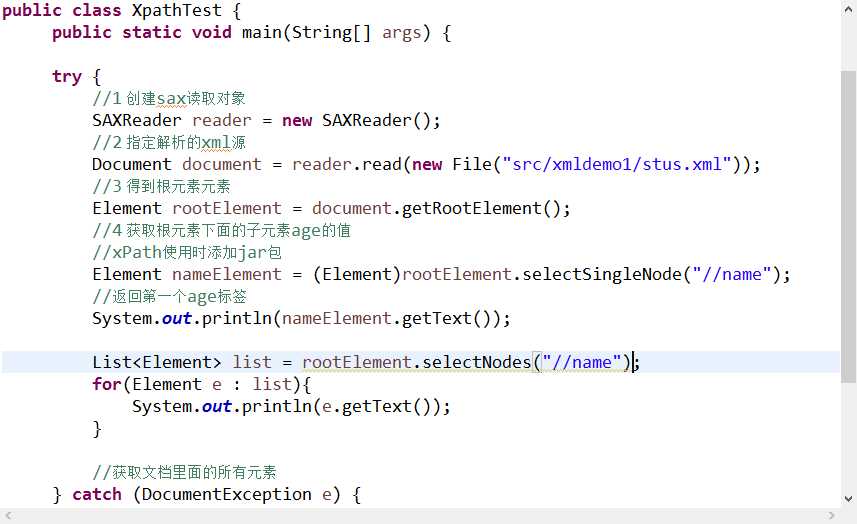
12 Dom4j的Xpath的使用
dom4j支持Xpath写法。
xpath是xml的路径语言,支持我们在解析xml的时候能够快速的定位到具体某个元素。
步骤:
1.添加jar包
2.根据Xpath语法查找指定结点
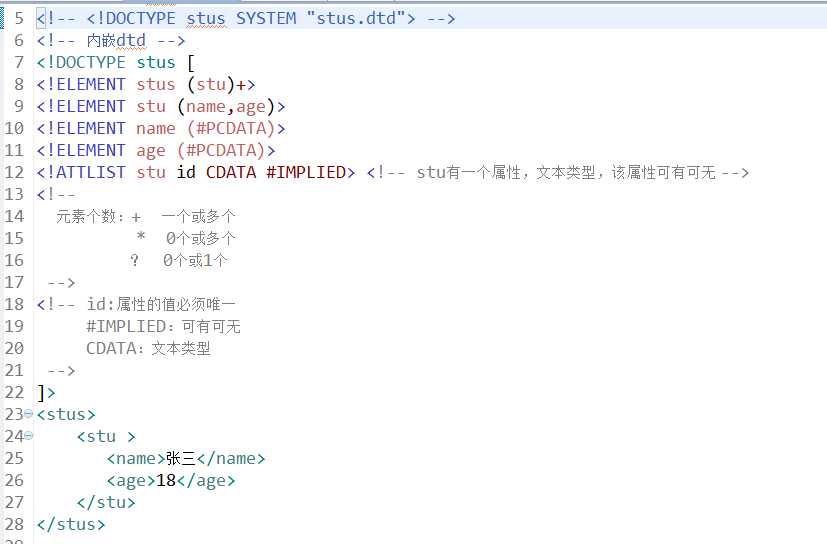
13 xml的文档约束
两个种类:DTD\Schema
DTD : 语法自成一派,早期出现,可读性差
Schema:其实就是一个xml,使用xml的语法规则,xml解析器解析起来比较方便,是为了替代dtd
但是约束文本内容比较多,没有真正替代dtd
DTD: 引入dtd的三种方式
Scheme:一个xml可以引用多个schema约束,但是只能有一个dtd
14 程序架构,C/S和B/S
C/S:client/Server
优点:有一部分代码写在客户端,用户体验比较好,
缺点: 服务器更新,客户端也要随之更新,占用资源差
例如QQ、微信、LOL
B/S:Browser/Server
优点:客户端只要有浏览器就可以了,占用资源小,不用更新
缺点:用户体验不佳
例如:网页游戏,webqq,qq邮箱
服务器:其实就是一台配置比较好的电脑
web服务器:客户端在浏览器的地址栏上输入地址,然后web服务器软件接收请求,响应消息
处理客户端的请求,返回资源、信息。
web应用:需要服务器支撑
Tomcat\WebLogic
标签:node 指定 体验 解析 ble 不用 单元 info tom
原文地址:https://www.cnblogs.com/ltfxy/p/10203413.html