标签:方法 自己 一个用户 表示 挖掘 支持 机器 最小 优化
隐语义模型又可称为LFM(latent factor model),它从诞生到今天产生了很多著名的模型和方法,其中和该技术相关且耳熟能详的名词有pLSA、 LDA、隐含类别模型(latent class model)、隐含主题模型(latent topic model)、矩阵分解(matrix factorization)。 本节将对隐含语义模型在Top-N推荐中的应用进行详细介绍,并通过实际的数据评测该模型。
核心思想:
通过隐含特征(latent factor)联系用户兴趣和物品。
举例:

用户A的兴趣涉及侦探小说、科普图书以及一些计算机技术书,而用户B的兴趣比较集中在数学和机器学习方面 。对A和B推荐图书时,根据第一篇文章,我们可以采用基于邻域的算法:UserCF 和ItemCF。
UserCF:首先需要找到和他们看了同样书的其他用户(兴趣相似的用户),然后给他们推荐那些用户喜欢的其他书。
ItemCF:需要给他们推荐和他们已经看的书相似的书,比如用户B看了很多关于数据挖掘的书,可以给他推荐机器学习或者模式识别方面的书。
还有一种是基于兴趣分类的方算法,也就是隐语义模型,隐语义模型通过如下公式计算用户u对物品 i 的兴趣:
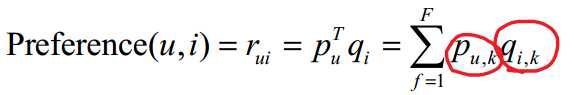
其中,pu,k 和 qi,k 是模型的参数,其中 pu,k 度量了用户u的兴趣和第k个隐类的关系,而 qi,k 度量了第k个隐类和物品 i 之间的关系。这样,就可以通过隐类,把用户u与物品 i 的兴趣联系起来。
需要注意的是推荐系统的用户行为分为显性反馈和隐性反馈。 LFM在显性反馈数据(也就是评分数据)上解决评分预测问题并达到了很好的精度。不过本章主要讨论的是隐性反馈数据集,这种数据集的特点是只有正样本(用户喜欢什么物品),而没有负样本(用户对什么物品不感兴趣) 。因此,需要构造负样本数据。
构造负样本时,要注意以下两点:
LFM损失函数:
![]()
通过利用梯度下降来最小化损失函数C,从而求解出pu,k 和 qi,k 。
在LFM中,重要的参数有4个:
举例:
数据集包含的是所有的user, 所有的item,以及每个user有过行为的item列表,使用LFM对其建模后,我们可以得到如下图所示的模型:(假设数据集中有3个user, 4个item, LFM建模的分类数为3)
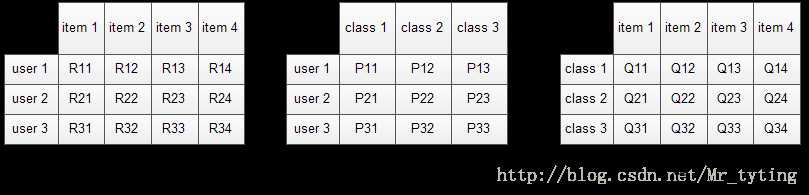
其中,R是user-item矩阵,矩阵值Rij表示的是用户 i 对物品 j 的兴趣度。对于一个用户来说,当计算出他对所有物品的兴趣度后,就可以进行排序并作出推荐。
LFM算法从数据集中抽取出若干主题,作为用户和物品 之间连接的桥梁,将R矩阵表示为P矩阵和Q矩阵相乘。其中P矩阵是user-class矩阵,矩阵值Pij表示的是用户 i 对class j的兴趣度;Q矩阵式class-item矩阵,矩阵值Qij表示的是物品 j 在class i中的权重,权重越高越能作为该类的代表。
优点:
总结:
LFM的研究一直是在评分预测问题上的,很少有人用它去生成TopN推荐的列表,而且也很少有人研究如何将这个数据用到非评分数据上。其实LFM在评分预测和在TopN上应用的道理是一样的。
在TopN问题上,隐反馈数据集上R只有1和0,分别表示感兴趣和不感兴趣,并且原始数据中只有明确1类的正样本,负反馈数据需要我们自己收集生成。通过获取PQ矩阵,就可以向某个特定用户推荐他喜欢的电影类内电影中权重最高的电影或者按权重从大到小排序推荐N个电影给此用户。
LFM具有比较好的理论基础,它是一种学习方法,通过优化一个设定的指标建立最优的模型。基于邻域的方法更多的是一种基于统计的方法,并没有学习过程。
LFM在生成一个用户推荐列表时速度太慢,因此不能在线实时计算。
ItemCF算法支持很好的推荐解释,它可以利用用户的历史行为解释推荐结果。 但LFM无法提供这样的解释。
标签:方法 自己 一个用户 表示 挖掘 支持 机器 最小 优化
原文地址:https://www.cnblogs.com/wkang/p/10091797.html