标签:something 方便 border gson 问题 cluster 程序员 world sim
一部编程发展史就是一部程序员偷懒史,MapReduce(下称MR)同样是程序员们用来偷懒的工具。
来了一份大数据,我们写了一个程序准备分析它,需要怎么做?
老式的处理方法不行,数据量太大时,所需的时间无法忍受,所以,必须并行计算。好比1000块砖,1个人搬需要1小时,10个人同时搬,只需要6分钟。
不过进行并行计算,面临几个细思头大问题:

不过不用担心,世界就是这样的,少部分人发明创造工具,大部分人使用工具。总有聪明人在合适的时候出来解决问题。
Google在2004年出了个paper,《MapReduce: Simplifed Data Processing on Large Clusters》,提出来一种针对大数据的并行处理模型、并基于此理论做了一个计算框架。
所以,你可以说MR是一种计算模型、也可以叫它一个计算框架。广义的MR甚至还包括一套资源管理(JobTracker、TaskTracker),后面这个我们不讲,因为,过,时,了。
Q 框架是什么?
A 就是套路。内部会帮你处理那些让你头大的问题。
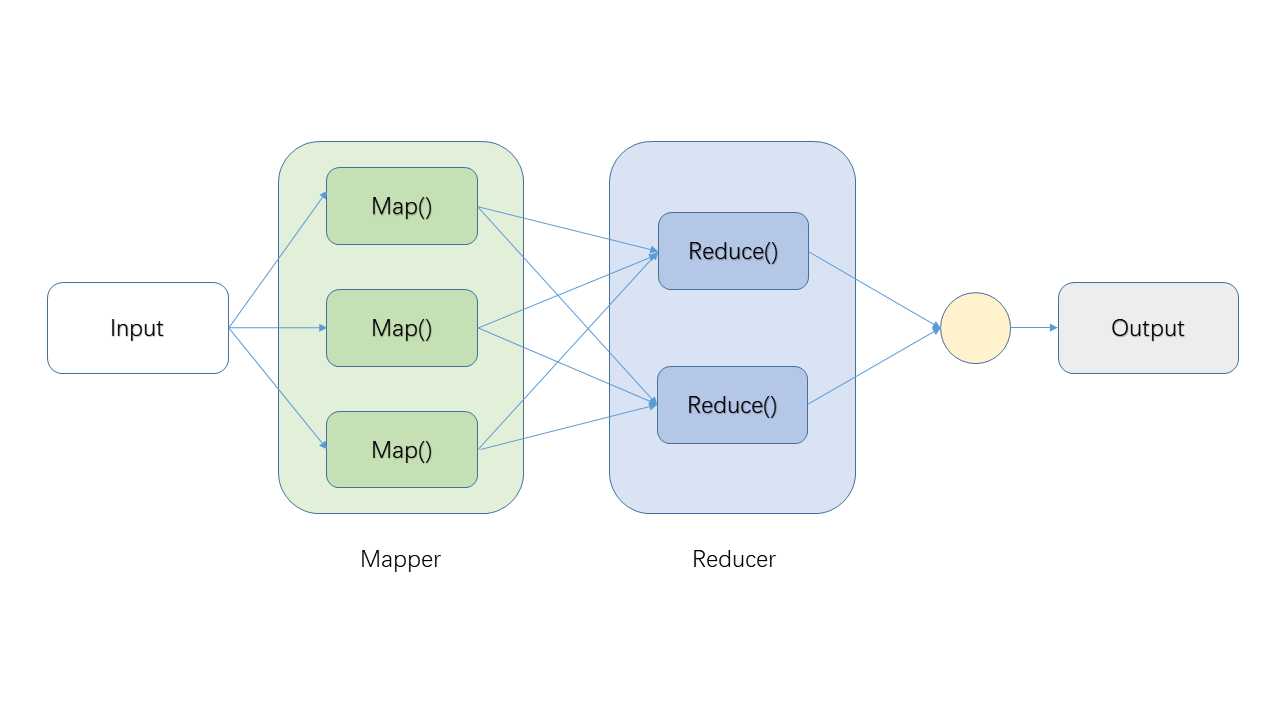
作为小白系列,我们先来看看MR简单的流程图:
为方便理解,来一个WorkCount示例(WordCount就好比大数据的HelloWorld,总要来一个的)。假设我们有一个文件包含内容:
Live for nothing, die for something
统计每一个单词出现的次数:
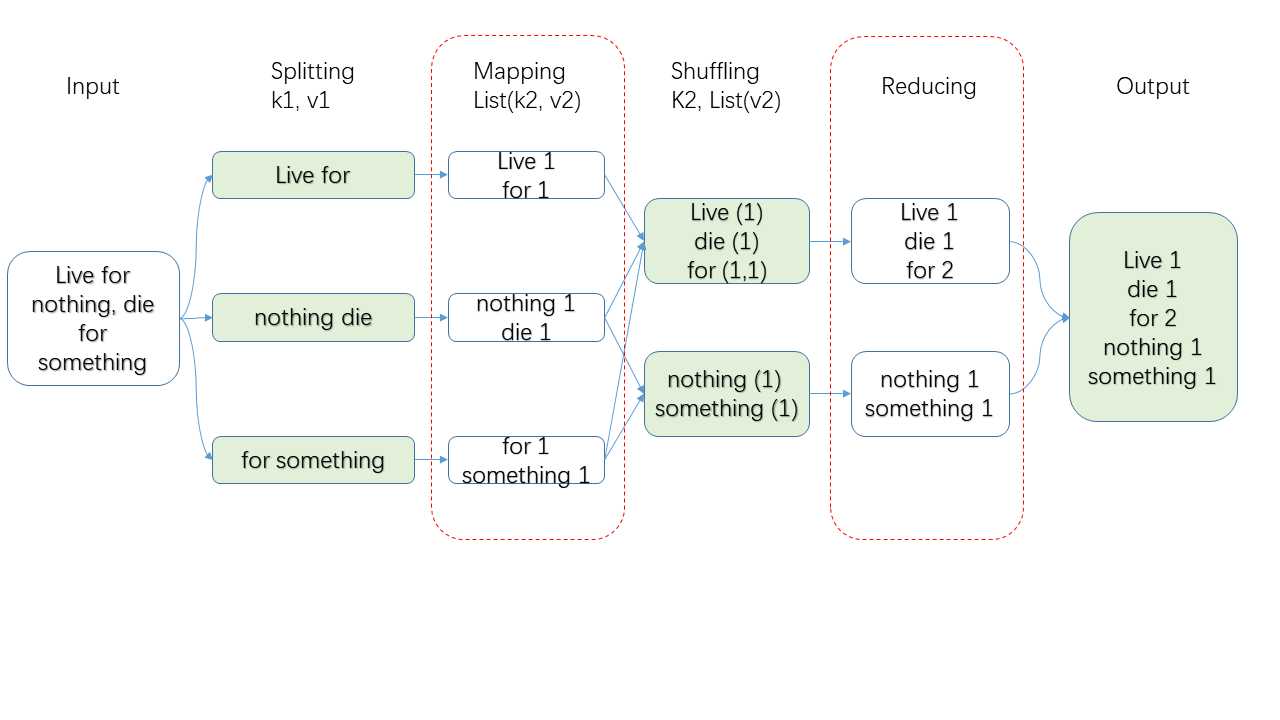
Q Splitting是怎么做的,分成几份?
A 框架决定(通常是文件有多少个数据块,就分成几份,数据块不懂的回去看HDFS系列)。
Q k1,v1是什么?
A 一般来说,k1是行号(在WordCount示例中用不到),v1是文件的某一行。本例只是概念示例,不用纠结。
Q Mapping产生的结果存储在哪里?
A 所在机器的本地文件系统,非HDFS,以避免产生多余的副本(HDFS默认多个副本)。
Q Shuffling是做什么的?
A 负责将Mapping产生的中间结果发给Reducer,哪些数据发个哪个Reducer,有框架决定。
Q Reducer有几个,运行在哪些机器上?
A 框架决定。
Q 哪些是需要程序员进行代码实现的?
A Mapping及Reducing,即图中两个红框部分。
好了,这期就先说到这,下期将稍微深入了解一下MR中的Shuffling、Sorting等概念。Cheers!
—END—
欢迎关注“程序员杂书馆”公众号,领取大数据经典纸质书。

标签:something 方便 border gson 问题 cluster 程序员 world sim
原文地址:https://www.cnblogs.com/morvenhuang/p/10213432.html