标签:公式 image ext 就是 频率 推荐 enc document nbsp
在相似文本的推荐中,可以用TF-IDF来衡量文章之间的相似性。
TF的含义很明显,就是词出现的频率。
公式:
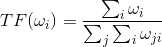
在算文本相似性的时候,可以采用这个思路,如果两篇文章高频词很相似,那么就可以认定两片文章很相似。
IDF为逆文档频率。
公式:
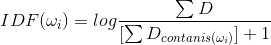
一个词越在语料库出现的次数越多,则权重应该越不重要;反之越少则应该越重要。
比如,如果要检索两个文档的相似度,通过统计权重大的词来进行匹配更为合理,如果统计词频高的词汇,例如很多文章都有(如果,很多,反之这些词汇),那么根本就抓不住相似性的衡量指标。如果两篇描述动物的文章我们如果能统计一些共有的权重较高的词,例如(海洋,鱼)等等则相对来说能更好的当作相似指标来进行计算。
目的:综合考虑TF和IDF。
公式:
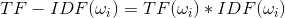
当一个词的词频很高并且逆文档率很高则越能代表这片文章的内容。
标签:公式 image ext 就是 频率 推荐 enc document nbsp
原文地址:https://www.cnblogs.com/ylxn/p/10213420.html