标签:前端 file prot 调查 好的 拒绝 tco ali 注意
本章将介绍如下主题:
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。 理想状态下,网络爬虫并不是必需品,每个网站都应该提供API,以结构化的的格式共享它们的数据。,但是它们通常会限制可以抓取的数据,以及访问这些数据的频率。另外对于网站的开发者而言,维护前端界面比维护后端API接口优先级更高。总之,我们不能仅仅依赖于API去访间我们所需的在线数据,而是应该学习些网络爬虫技术的相关知识。
爬虫作为一种计算机技术就决定了它的中立性,因此爬虫本身在法律上并不被禁止,但是利用爬虫技术获取数据这一行为是具有违法甚至是犯罪的风险的。所谓具体问题具体分析,正如水果刀本身在法律上并不被禁止使用,但是用来捅人,就不被法律所容忍了。
或者我们可以这么理解:爬虫是用来批量获得网页上的公开信息的,也就是前端显示的数据信息。因此,既然本身就是公开信息,其实就像浏览器一样,浏览器解析并显示了页面内容,爬虫也是一样,只不过爬虫会批量下载而已,所以是合法的。不合法的情况就是配合爬虫,利用黑客技术攻击网站后台,窃取后台数据(比如用户数据等)。
举个例子:像谷歌这样的搜索引擎爬虫,每隔几天对全网的网页扫一遍,供大家查阅,各个被扫的网站大都很开心。这种就被定义为“善意爬虫”。但是像抢票软件这样的爬虫,对着 12306 每秒钟恨不得撸几万次,铁总并不觉得很开心,这种就被定义为“恶意爬虫”。
爬虫所带来风险主要体现在以下3个方面:
那么作为爬虫开发者,如何在使用爬虫时避免进局子的厄运呢?
可以说在我们身边的网络上已经密密麻麻爬满了各种网络爬虫,它们善恶不同,各怀心思。而越是每个人切身利益所在的地方,就越是爬满了爬虫。所以爬虫是趋利的,它们永远会向有利益的地方爬行。技术本身是无罪的,问题往往出在人无限的欲望上。因此爬虫开发者的道德自持和企业经营者的良知才是避免触碰法律底线的根本所在。
关于上述几个法律案件的更多信息可以参考下述地址:
http://caselaw.lp.findlaw.com/scripts/getcase. pl?court=US&vo1-499&invol=340 http://www.austlii.edu.au/au/cases/cth/ECA/2010/44.html
大多数网站都会定义robots.txt文件,这样可以让爬虫交接爬取该网站时存在哪些限制。这些限制虽然仅仅作为限制给出,但是良好的公民都应该遵守。在爬取之前,检查robots.txt文件这一宝贵资源可以最小化爬虫被封禁的可能性,而且还能发现和网站结构相关的线索。关于robots.txt协议可以参考http://www.robotstxt.org。下面的代码是事例文件robots.txt中的内容,可以访问http://example.webscraping.com/robots.txt获取(百度的 https://www.baidu.com/robots.txt)。
# section 1 User-agent: BadCrawler # 禁止代理为BadCrawler的爬虫爬取该网站。但是恶意爬虫不会遵守这个规定。 Disallow: / # 后面会讲如何让爬虫自动遵守robots.txt的要求。 # section 2 User-agent: * # 任何用户代理都被允许。 Crawl-delay: 5 # 但是需要在两次下载请求之间给出5秒的抓取延迟。我们应该遵从建议避免服务器过载。 Disallow: /trap # 这里的/trap链接,用于封禁那些爬去了不允许链接的恶意爬虫。封禁IP的时间可能是1分钟,可能会更久,也可能是永久封禁。 # section 3 Sitemap: http://example.webscraping.com/sitemap.xml # 定义了一个Sitemap文件,后面1.3.2会讲解如何检查该文件。
网站提供的 Sitemap文件(即网站地图)可以帮助爬虫定位网站最新的内容,而无须爬取每一个网页。如果想要了解更多信息,可以从http://www.sitemaps.org/protocol.html获取网站地图标准的定义。下面是在 robots.txt文件中发现的 Sitemap文件的内容:
<?xml version="1.0" encoding="ISO-8859-1"?> <urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> <url> <loc>http://example.webscraping.com/places/default/view/Afghanistan-1</loc> </url> <url> <loc>http://example.webscraping.com/places/default/view/Aland-Islands-2</loc> </url> <url> <loc>http://example.webscraping.com/places/default/view/Albania-3</loc> </url> <url> <loc>http://example.webscraping.com/places/default/view/Algeria-4</loc> </url> <url> <loc>http://example.webscraping.com/places/default/view/American-Samoa-5</loc> </url> ... </urlset>
这个文件地图提供了该网站所有网页的链接。后面我们会用到这些信息来创建爬虫,但是需要谨慎处理,因为这个文件经常存在缺失、过期或不完整的问题。
目标网站的大小会影响我们如何进行爬取。如果是像我们的示例站点这样只有几百个URL的网站,效率并没有那么重要;但如果是拥有数百万个网页的站点,使用串行下载可能需要持续数月才能完成,这时就需要使用第4章中介绍的分布式下载来解决了。
估算网站大小的一个简便方法是检查google爬虫的结果,因为谷歌很可能已经爬取过我们感兴趣的网站。我们可以通过Google搜索的site关键词过滤域名结果,从而获取该信息。我们可以从http://www.google.com/advanced_search了解到该接口及其他高级搜索参数的用法。
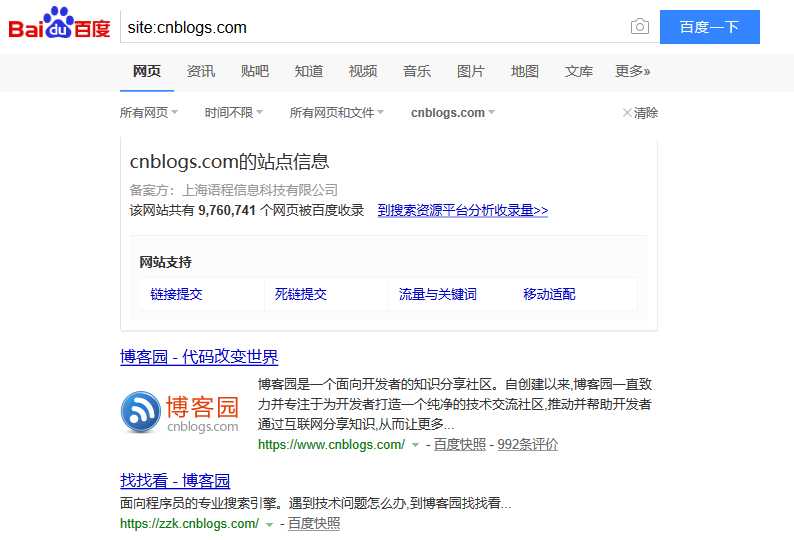
下图所示为使用site关键词对我们的示例网站进行搜索的结果,即在百度中搜索site:cnblogs.com(也可以在Google搜索中输入site:cnblogs.com)。
从图中可以看出,此时百度估算该网站拥有九百多万个网页。在域名后面添加URL路径,可以对结果进行过滤,仅显示网站的某些部分。
构建网站所使用的技术类型也会对我们如何爬取产生影响。有一个十分有用的工具可以检查网站构建的技术类型——builtwith模块。
该模块的安装方法如下:
pip install builtwith
该模块将URL作为参数,下载该URL并对其进行分析,然后返回该网站使用的技术。
例子如下:
import builtwith ret = builtwith.parse(‘http://example.webscraping.com‘) print ret
结果如下:
{
u‘javascript-frameworks‘: [u‘jQuery‘, u‘Modernizr‘, u‘jQuery UI‘], # 该网站使用了js库,其内容很可能是嵌入到HTML中的,相对比较容易抓取。
u‘web-frameworks‘: [u‘Web2py‘, u‘Twitter Bootstrap‘], # 该网站使用了python的Web2py框架
u‘programming-languages‘: [u‘Python‘], # 该网站使用的是python语言
u‘web-servers‘: [u‘Nginx‘]
}
为了找到网站的所有者,我们可以使用 WHOIS协议查询域名的注册者是谁。 Python中有一个针对该协议的封装库,其文档地址为https://pypi.python.org/pypi/python- whois,我们可以通过pip进行安装。
pip install python-whois
使用该模块对baidu.com这个域名进行WHIOS查询,如下:
import whois ret = whois.whois("baidu.com") print ret
结果如下:
{ "updated_date": [ "2017-07-28 02:36:28", "2017-07-27 19:36:28" ], "status": [ "clientDeleteProhibited https://icann.org/epp#clientDeleteProhibited", "clientTransferProhibited https://icann.org/epp#clientTransferProhibited", "clientUpdateProhibited https://icann.org/epp#clientUpdateProhibited", "serverDeleteProhibited https://icann.org/epp#serverDeleteProhibited", "serverTransferProhibited https://icann.org/epp#serverTransferProhibited", "serverUpdateProhibited https://icann.org/epp#serverUpdateProhibited", "clientUpdateProhibited (https://www.icann.org/epp#clientUpdateProhibited)", "clientTransferProhibited (https://www.icann.org/epp#clientTransferProhibited)", "clientDeleteProhibited (https://www.icann.org/epp#clientDeleteProhibited)", "serverUpdateProhibited (https://www.icann.org/epp#serverUpdateProhibited)", "serverTransferProhibited (https://www.icann.org/epp#serverTransferProhibited)", "serverDeleteProhibited (https://www.icann.org/epp#serverDeleteProhibited)" ], "name": null, "dnssec": "unsigned", "city": null, "expiration_date": [ "2026-10-11 11:05:17", "2026-10-11 00:00:00" ], "zipcode": null, "domain_name": [ "BAIDU.COM", "baidu.com" ], "country": "CN", "whois_server": "whois.markmonitor.com", "state": "Beijing", "registrar": "MarkMonitor, Inc.", "referral_url": null, "address": null, "name_servers": [ "DNS.BAIDU.COM", "NS2.BAIDU.COM", "NS3.BAIDU.COM", "NS4.BAIDU.COM", "NS7.BAIDU.COM", "ns4.baidu.com", "ns7.baidu.com", "ns3.baidu.com", "ns2.baidu.com", "dns.baidu.com" ], "org": "Beijing Baidu Netcom Science Technology Co., Ltd.", "creation_date": [ "1999-10-11 11:05:17", "1999-10-11 04:05:17" ], "emails": [ "abusecomplaints@markmonitor.com", "whoisrequest@markmonitor.com" ] }
3种爬取网站的常用方法:
使用python的urllib2模块下载URL:
import urllib2 def download(url): return urllib2.urlopen(url).read() ret = download("https://www.cnblogs.com/aaronthon/p/10176432.html") print ret
上面的代码会获取完整的HTML。但是当网页不存时,urllib2会抛出异常,然后结束程序。
如下改进:
import urllib2 def download(url): try: html = urllib2.urlopen(url).read() except urllib2.URLError as e: print "Download error:", e.reason html = None return html ret = download("https://www.cnblogs.com/aaronthon/p/10176432.html") print ret
如果下载出错,该函数可以捕捉异常,并返回None。
1.4.1.1 重试下载
下载时遇到的错误往往是临时性的,比如服务器过载时返回的503 Service Unavailable错误。对于此类错误,我们可以尝试重新下载,因为这个服务器问题现在可能已经修复了。不过,我们不需要对所有错误都尝试重新下载。如果服务器返回的是404 Not Fount这种错误,则说明该网页不存在,再次尝试下载毫无意义。
HTTP错误的完整列表,详情可参考https://tools.ietf.org/html/rfc7231#section-6。我们只需要确保download函数在发生5xx错误时重试下载即可。
代码如下:
import urllib2 def download(url, num_retries=2): try: html = urllib2.urlopen(url).read() except urllib2.URLError as e: print "Download error:", e.reason html = None if num_retries > 0: if hasattr(e, ‘code‘) and 500 <= e.code <= 600: return download(url, num_retries-1) return html ret = download("https://www.cnblogs.com/aaronthon/p/1076432.html") print ret
1.4.1.2 设置用户代理
默认情况下,urllib2使用Python-urllib/2.7 作为用户代理下载网页内容,其中2.7是python的版本号。也许曾经使用质量不佳的网络爬虫造成服务器过载,一些网站还会这个默认的用户代理。
因此,为了下载更加可靠,我们需要控制用户代理的设定。下面代码对download函数进行了修改,设定了一个默认的用户代理“wswp”。
import urllib2 def download(url, num_retries=2, user_agent="wswp"): headers = {"User-agent" : user_agent} request = urllib2.Request(url, headers=headers) try: html = urllib2.urlopen(request).read() except urllib2.URLError as e: print "Download error:", e.reason html = None if num_retries > 0: if hasattr(e, ‘code‘) and 500 <= e.code <= 600: return download(url, num_retries-1, user_agent) return html ret = download("https://www.cnblogs.com/aaronthon/p/10176432.html") print ret
这个爬虫可以捕捉异常、重试下载和设置用户代理。
这一节,我们使用简单的正则表达式,解析网站地图里面的被<loc>标签包裹的URL。
代码如下:
import re import urllib2 def download(url, num_retries=2, user_agent="wswp"): print ‘downloding:‘, url headers = {"User-agent" : user_agent} request = urllib2.Request(url, headers=headers) try: html = urllib2.urlopen(request).read() except urllib2.URLError as e: print "Download error:", e.reason html = None if num_retries > 0: if hasattr(e, ‘code‘) and 500 <= e.code <= 600: return download(url, num_retries-1, user_agent) return html def crawl_sitemap(url): sitemap = download(url) links = re.findall(‘<loc>(.*?)</loc>‘, sitemap) for link in links: html = download(link) crawl_sitemap("http://example.webscraping.com/sitemap.xml")
运行结果:
downloding: http://example.webscraping.com/sitemap.xml downloding: http://example.webscraping.com/places/default/view/Afghanistan-1 downloding: http://example.webscraping.com/places/default/view/Aland-Islands-2 downloding: http://example.webscraping.com/places/default/view/Albania-3 downloding: http://example.webscraping.com/places/default/view/Algeria-4 downloding: http://example.webscraping.com/places/default/view/American-Samoa-5 downloding: http://example.webscraping.com/places/default/view/Andorra-6 downloding: http://example.webscraping.com/places/default/view/Angola-7 downloding: http://example.webscraping.com/places/default/view/Anguilla-8 downloding: http://example.webscraping.com/places/default/view/Antarctica-9 downloding: http://example.webscraping.com/places/default/view/Antigua-and-Barbuda-10 downloding: http://example.webscraping.com/places/default/view/Argentina-11 downloding: http://example.webscraping.com/places/default/view/Armenia-12 downloding: http://example.webscraping.com/places/default/view/Aruba-13 downloding: http://example.webscraping.com/places/default/view/Australia-14 ...
局限性太强。
我们例子中的网站地图是这个样子的:
<?xml version="1.0" encoding="ISO-8859-1"?> <urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"> <url> <loc>http://example.webscraping.com/places/default/view/Afghanistan-1</loc> </url> <url> <loc>http://example.webscraping.com/places/default/view/Aland-Islands-2</loc> </url> <url> <loc>http://example.webscraping.com/places/default/view/Albania-3</loc> </url> <url> <loc>http://example.webscraping.com/places/default/view/Algeria-4</loc> </url> <url> <loc>http://example.webscraping.com/places/default/view/American-Samoa-5</loc> </url> ... </urlset>
可以看出,这些URL的尾处是连续的数字,并且我们这样访问http://example.webscraping.com/places/default/view/1,测试这个链接是可用的。
测试结果如下:
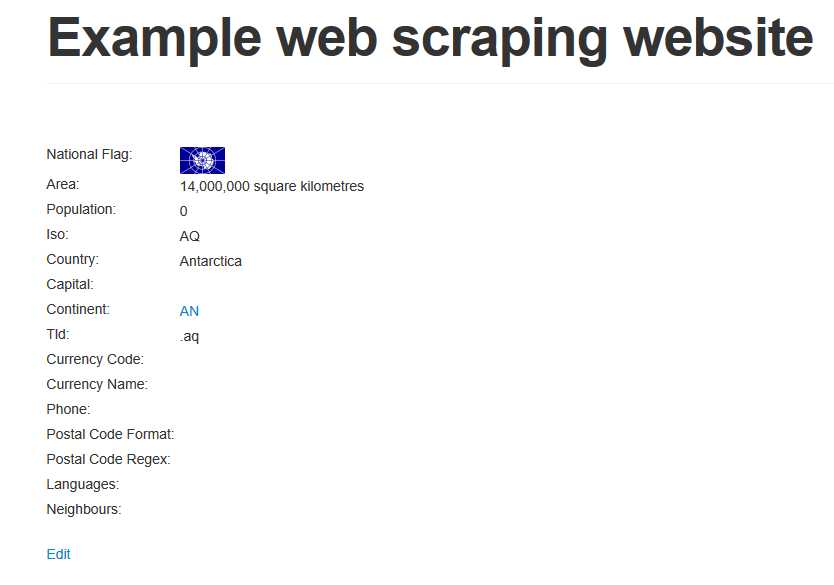
我们利用这个特性,写出如下网络爬虫:
import re import urllib2 import itertools def download(url, num_retries=2, user_agent="wswp"): print ‘downloding:‘, url headers = {"User-agent" : user_agent} request = urllib2.Request(url, headers=headers) try: html = urllib2.urlopen(request).read() except urllib2.URLError as e: print "Download error:", e.reason html = None if num_retries > 0: if hasattr(e, ‘code‘) and 500 <= e.code <= 600: return download(url, num_retries-1, user_agent) return html for page in itertools.count(1): url = ‘http://example.webscraping.com/places/default/view/-%d‘%page html = download(url) if html is None: break else: pass
但是,上面这段代码却显示明显的。当ID是不连续的,这是程序会立即退出。
如下改进:
import re import urllib2 import itertools def download(url, num_retries=2, user_agent="wswp"): print ‘downloding:‘, url headers = {"User-agent" : user_agent} request = urllib2.Request(url, headers=headers) try: html = urllib2.urlopen(request).read() except urllib2.URLError as e: print "Download error:", e.reason html = None if num_retries > 0: if hasattr(e, ‘code‘) and 500 <= e.code <= 600: return download(url, num_retries-1, user_agent) return html max_errors = 5 num_errors = 0 for page in itertools.count(1): url = ‘http://example.webscraping.com/places/default/view/-%d‘%page html = download(url) if html is None: num_errors += 1 if num_errors == max_errors: break else: num_errors = 0 pass
这个爬虫会在出现5此连续的下载错误才会退出程序。
ID遍历爬虫局限性太大了,很多网站使用非连续打书做ID,或者不适应数值做ID。此时ID遍历爬虫就失去作用了。
链接爬虫通过追踪所有链接的方式,很容易下载整个网站的页面。但是我们只想下载我们需要的页面,本节链接爬虫将使用正则表达式来确定下载的页面。
原始链接爬虫版本如下:
import re import urllib2 import urlparse def download(url, num_retries=2, user_agent="wswp"): print ‘downloding:‘, url headers = {"User-agent" : user_agent} request = urllib2.Request(url, headers=headers) try: html = urllib2.urlopen(request).read() except urllib2.URLError as e: print "Download error:", e.reason html = None if num_retries > 0: if hasattr(e, ‘code‘) and 500 <= e.code <= 600: return download(url, num_retries-1, user_agent) return html def get_links(html): webpage_regex = re.compile(‘<a[^>]+href=["\‘](.*?)["\‘]‘, re.IGNORECASE) print webpage_regex.findall(html) return webpage_regex.findall(html) def link_crawler(send_url, link_regex): crawl_queue = [send_url] while crawl_queue: url = crawl_queue.pop() html = download(url) for link in get_links(html): if re.search(link_regex, link): crawl_queue.append(link) link_crawler(‘http://example.webscraping.com‘, ‘/(index|view)‘)
运行之后会有如下保错:
downloding: http://example.webscraping.com [‘/places/default/index‘, ‘#‘, ‘/places/default/user/register?_next=/places/default/index‘, ‘/places/default/user/login?_next=/places/default/index‘, ‘/places/default/index‘, ‘/places/default/search‘, ‘/places/default/view/Afghanistan-1‘, ‘/places/default/view/Aland-Islands-2‘, ‘/places/default/view/Albania-3‘, ‘/places/default/view/Algeria-4‘, ‘/places/default/view/American-Samoa-5‘, ‘/places/default/view/Andorra-6‘, ‘/places/default/view/Angola-7‘, ‘/places/default/view/Anguilla-8‘, ‘/places/default/view/Antarctica-9‘, ‘/places/default/view/Antigua-and-Barbuda-10‘, ‘/places/default/index/1‘] Traceback (most recent call last): File "C:/Users/WIStron/PycharmProjects/flask_demo/logs/p.py", line 35, in <module> link_crawler(‘http://example.webscraping.com‘, ‘/(index|view)‘) File "C:/Users/WIStron/PycharmProjects/flask_demo/logs/p.py", line 29, in link_crawler html = download(url) File "C:/Users/WIStron/PycharmProjects/flask_demo/logs/p.py", line 10, in download html = urllib2.urlopen(request).read() File "C:\Python27\lib\urllib2.py", line 154, in urlopen return opener.open(url, data, timeout) File "C:\Python27\lib\urllib2.py", line 423, in open protocol = req.get_type() File "C:\Python27\lib\urllib2.py", line 285, in get_type downloding: /places/default/index/1 raise ValueError, "unknown url type: %s" % self.__original ValueError: unknown url type: /places/default/index/1
可以看出,问题出在加载/places/default/index/1时,该链接只有网页的部分路径,而没有协议和服务器部分,就是一个相对路径。由于浏览器知道你正在浏览哪个网页,所以在浏览器浏览时,相对路径能够正常工作。但是,urllib2是无法获知上下文的。问了让urllib2能够定位网页,我们需将路径相对转换成绝对路径,以便定位网页所有细节。Python中的urlparse模块就是来实现这一功能的。
如下赶紧代码,使用urlparse模块来创建绝对路径:
import re import time import urllib2 import urlparse def download(url, num_retries=2, user_agent="wswp"): print ‘downloding:‘, url headers = {"User-agent" : user_agent} request = urllib2.Request(url, headers=headers) try: html = urllib2.urlopen(request).read() except urllib2.URLError as e: print "Download error:", e.reason html = None if num_retries > 0: if hasattr(e, ‘code‘) and 500 <= e.code <= 600: return download(url, num_retries-1, user_agent) return html def get_links(html): webpage_regex = re.compile(‘<a[^>]+href=["\‘](.*?)["\‘]‘, re.IGNORECASE) return webpage_regex.findall(html) def link_crawler(send_url, link_regex): crawl_queue = [send_url] while crawl_queue: url = crawl_queue.pop() html = download(url) for link in get_links(html): time.sleep(0.1) # 防止服务器过载 if re.search(link_regex, link): link = urlparse.urljoin(send_url, link) crawl_queue.append(link) link_crawler(‘http://example.webscraping.com‘, ‘/(index|view)‘)
这段代码不报错了,但是同一个网页会被重复下载,因为这些网页相互之间存在链接。
如下优化,避免重复下载:
import re import time import urllib2 import urlparse def download(url, num_retries=2, user_agent="wswp"): print ‘downloding:‘, url headers = {"User-agent" : user_agent} request = urllib2.Request(url, headers=headers) try: html = urllib2.urlopen(request).read() except urllib2.URLError as e: print "Download error:", e.reason html = None if num_retries > 0: if hasattr(e, ‘code‘) and 500 <= e.code <= 600: return download(url, num_retries-1, user_agent) return html def get_links(html): webpage_regex = re.compile(‘<a[^>]+href=["\‘](.*?)["\‘]‘, re.IGNORECASE) return webpage_regex.findall(html) def link_crawler(send_url, link_regex): crawl_queue = [send_url] crawl_queue_a = [send_url] # seen = set(crawl_queue) while crawl_queue: url = crawl_queue.pop() html = download(url) for link in get_links(html): time.sleep(0.1) # 防止网站过载 if re.search(link_regex, link): link = urlparse.urljoin(send_url, link) if link in crawl_queue_a: pass else: crawl_queue.append(link) crawl_queue_a.append(link) link_crawler(‘http://example.webscraping.com‘, ‘/(index|view)‘)
这样就不会下载重复的网页了。
1.4.4.1 高级功能
为这个爬虫添加新功能,使其爬取其他网站时更有用。
首先我们先解析robots.txt文件,以避免下载禁止爬取的URL。使用Python自带的rpbotparser模块,就可以轻松完成这项工作。
如下所示:
rp = robotparser.RobotFileParser() rp.set_url(‘http://example.webscraping.com/robots.txt‘) rp.read() print rp # rp是拿到的整个文件内容 url = ‘http://example.webscraping.com‘ user_agent = ‘BadCrawler‘ r2 = rp.can_fetch(user_agent, url) print r2 user_agent = ‘GoodCrawler‘ r3 = rp.can_fetch(user_agent, url) print r3
结果为:
User-agent: BadCrawler Disallow: / False True
robotparser模块首先加载robots.txt文件,然后通过can_fetch()函数确定指定的用户代理是否允许访问网页。
通过在crawl循环中添加该检查,将此功能添加到我们的爬虫中:
import re import time import datetime import urllib2 import urlparse import robotparser rp = robotparser.RobotFileParser() rp.set_url(‘http://example.webscraping.com/robots.txt‘) rp.read() def download(url, num_retries=2, user_agent="wswp"): print ‘downloding:‘, url headers = {"User-agent" : user_agent} request = urllib2.Request(url, headers=headers) try: html = urllib2.urlopen(request).read() except urllib2.URLError as e: print "Download error:", e.reason html = None if num_retries > 0: if hasattr(e, ‘code‘) and 500 <= e.code <= 600: return download(url, num_retries-1, user_agent) return html def get_links(html): webpage_regex = re.compile(‘<a[^>]+href=["\‘](.*?)["\‘]‘, re.IGNORECASE) return webpage_regex.findall(html) def link_crawler(send_url, link_regex, user_agent=None): crawl_queue = [send_url] crawl_queue_a = [send_url] while crawl_queue: url = crawl_queue.pop() html = download(url) if rp.can_fetch(useragent=user_agent, url=url): for link in get_links(html): time.sleep(0.1) if re.search(link_regex, link): link = urlparse.urljoin(send_url, link) if link in crawl_queue_a: pass else: crawl_queue.append(link) crawl_queue_a.append(link) else: print ‘Blocked by robots.txt:‘, url link_crawler(‘http://example.webscraping.com‘, ‘/(index|view)‘, user_agent="BadCrawler")
1.4.4.2 支持代理
有时我们需要使用代理访问某个网站,但是有些网站屏蔽了太多的国家。使用urllib支持代理并没有想象的那么容易(可以尝试使用更友好的Python HTTP的模块requests来实现该功能,其文档 http://docs.python-requests.org/)。
下面是使用urllib2支持代理的代码:
proxy = None opener = urllib2.build_opener() proxy_params = { urlparse.urlparse(url).scheme: proxy } opener.add_handler(urllib2.ProxyHandler(proxy_params)) response = opener.open(request)
下面是集成了该功能的新版本download函数:
import re import time import datetime import urllib2 import urlparse import robotparser rp = robotparser.RobotFileParser() rp.set_url(‘http://example.webscraping.com/robots.txt‘) rp.read() def download(url, num_retries=2, user_agent="wswp", proxy=None): print ‘downloding:‘, url headers = {"User-agent" : user_agent} request = urllib2.Request(url, headers=headers) opener = urllib2.build_opener() if proxy: proxy_params = { urlparse.urlparse(url).scheme: proxy } opener.add_handler(urllib2.ProxyHandler(proxy_params)) try: html = urllib2.urlopen(request).read() except urllib2.URLError as e: print "Download error:", e.reason html = None if num_retries > 0: if hasattr(e, ‘code‘) and 500 <= e.code <= 600: return download(url, num_retries-1, user_agent, proxy) return html def get_links(html): webpage_regex = re.compile(‘<a[^>]+href=["\‘](.*?)["\‘]‘, re.IGNORECASE) return webpage_regex.findall(html) def link_crawler(send_url, link_regex, user_agent=None): crawl_queue = [send_url] crawl_queue_a = [send_url] while crawl_queue: url = crawl_queue.pop() html = download(url) if rp.can_fetch(useragent=user_agent, url=url): for link in get_links(html): time.sleep(0.1) if re.search(link_regex, link): link = urlparse.urljoin(send_url, link) if link in crawl_queue_a: pass else: crawl_queue.append(link) crawl_queue_a.append(link) else: print ‘Blocked by robots.txt:‘, url link_crawler(‘http://example.webscraping.com‘, ‘/(index|view)‘, user_agent="GoodCrawler")
1.4.4.3 下载限速
# coding: utf-8 import re import time import datetime import urllib2 import urlparse import robotparser rp = robotparser.RobotFileParser() # robotparser模块用来获取目标网站的robots.txt内容 rp.set_url(‘http://example.webscraping.com/robots.txt‘) rp.read() # 获取整个文件 class Throttle: def __init__(self, delay): self.delay = delay self.domains = {} # 记录最近一访问时间 def wait(self, url): domain = urlparse.urlparse(url).netloc # 拿到传入的url last_accessed = self.domains.get(domain) # 获取最近一次访问时间 if self.delay > 0 and last_accessed is not None: # 最近有访问 sleep_secs = self.delay - (datetime.datetime.now() - last_accessed).seconds if sleep_secs > 0: time.sleep(sleep_secs) self.domains[domain] = datetime.datetime.now() # 更新最近访问的时间 def download(url, num_retries=2, user_agent="wswp", proxy=None): print ‘downloding:‘, url headers = {"User-agent" : user_agent} # 请求头 request = urllib2.Request(url, headers=headers) # urllib2 opener = urllib2.build_opener() if proxy: proxy_params = { urlparse.urlparse(url).scheme: proxy } opener.add_handler(urllib2.ProxyHandler(proxy_params)) try: html = urllib2.urlopen(request).read() # 爬去网页 except urllib2.URLError as e: # 出错,打印错误 print "Download error:", e.reason html = None if num_retries > 0: # 多试几次 if hasattr(e, ‘code‘) and 500 <= e.code <= 600: # 如果是服务器错误,就多试几次 return download(url, num_retries-1, user_agent, proxy) return html # 返回拿到的html def get_links(html): webpage_regex = re.compile(‘<a[^>]+href=["\‘](.*?)["\‘]‘, re.IGNORECASE) return webpage_regex.findall(html) def link_crawler(send_url, link_regex, user_agent=None): crawl_queue = [send_url] # 将url放到列表中 crawl_queue_a = [send_url] # 备份一份url列表 while crawl_queue: # 循环这个列表,爬取每一个urll url = crawl_queue.pop() # 拿到要爬的url html = download(url) # 下载html throttle.wait(url) print url, "url" if rp.can_fetch(useragent=user_agent, url=url): # 检测该url是否允许爬虫访问 for link in get_links(html): # 追踪所有的url # time.sleep(0.1) # 防止服务器过载 if re.search(link_regex, link): # 正则匹配 link = urlparse.urljoin(send_url, link) # 拼接路径 if link in crawl_queue_a: # 避免重复爬取 pass else: crawl_queue.append(link) # 加到需要循环的列表 crawl_queue_a.append(link) # 备份,避免重复爬取 else: print ‘Blocked by robots.txt:‘, url # 拒绝爬虫 delay = 10 # 两次下载间隔10秒,低于10秒会睡一下 url = ‘http://example.webscraping.com‘ headers = {"User-agent" : "GoodCrawler"} throttle = Throttle(delay) result = link_crawler(url, link_regex=‘/(index|view)‘, user_agent="GoodCrawler")
1.4.4.4 避免爬虫陷阱
上面我们写好的爬虫会跟踪所有没有访问过的链接。但是一些网站会动态生成页面内容,比如一个在线日历功能,提供了一个可以访问下一年和下一月的链接,这样的页面就会无限链接下去。这种情况被称为爬虫陷阱。
想要避免爬虫陷阱,最简单的方法就是记录当前页面经过了多少个链接,也就是深度。当达到最大深度时,爬虫就不再向队列添加该网页中的链接了。要实现该功能,我们需要修改seen变量。该变量先只记录访问过的网页链接,现在修改为一个字典,增加了深度的记录。
声明:
本文章为本人学习《用Python写网络爬虫》时的学习随笔,不作为商业用途。
原书作者:【澳】 Richard Lawson
译者:李斌
出版社:中国工信出版集团 人民邮电出版社
请支持原著!
标签:前端 file prot 调查 好的 拒绝 tco ali 注意
原文地址:https://www.cnblogs.com/aaronthon/p/10184047.html