标签:Lua脚本 version 跳转 res ber b2b int 官方文档 jpeg
一、Splash 的使用
Splash 是一个JavaScript 渲染服务,带有 HTTP API的轻量级浏览器,同时对接了 Python 中的 Twisted 和 QT 库。利用它,同样可以实现动态渲染页面的抓取。
function main(splash, args) assert(splash:go(args.url)) assert(splash:wait(0.5)) return { html = splash:html(), png = splash:png(), har = splash:har(), } end
这个脚本是用 Lua 语言写的脚本。从脚本的表面意思,它首先调用 go()方法去加载页面,再调用 wait()方法等待一定时间,最后返回页面的源码、截图和 HAR 信息。
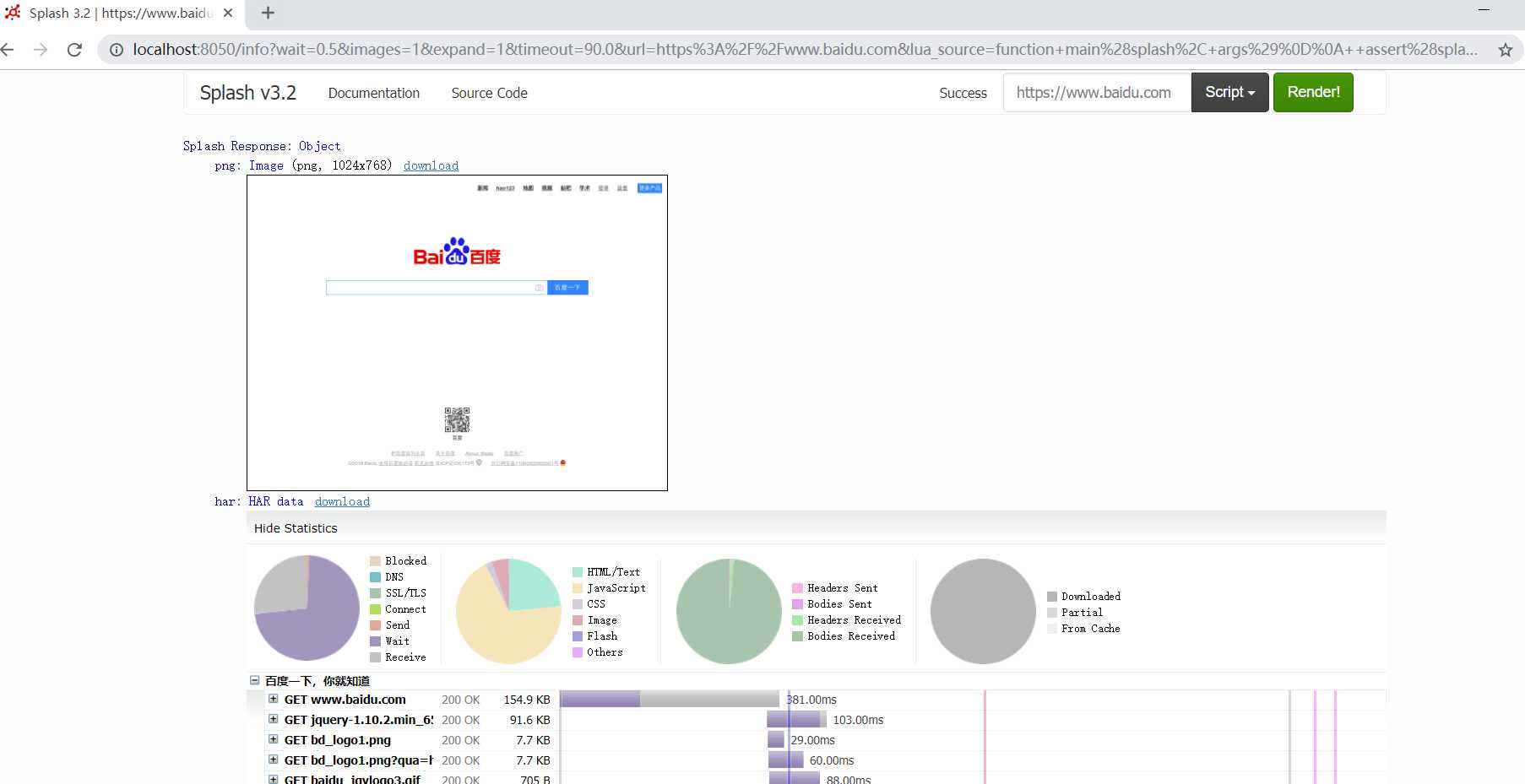
function main(splash, args) splash:go("http://www.baidu.com") splash:wait(0.5) local title = splash:evaljs("document.title") return {title= title} end
将代码贴到 http://localhost:8050/ 的代码编辑区域,点击 Render me!按钮 测试
注意,在这里定义的方法名称叫作 main()。这个名称必须是固定的,Splash 会默认调用这个方法。
function main(splash) return { hello="world" } end
返回一个字典形式的内容。如:

function main(splash, args) local example_urls ={"www.baidu.com","www.taobao.com","www.zhihu.com"} local urls = args.urls or example_urls local results = {} for index, url in ipairs(urls) do local ok, reason = splash:go("http://"..url) if ok then splash:wait(2) results[url] = splash:png() end end return results end
输出:
function main(splash, args) local url = args.url end
这里第二个参数 args 就相当于 splash.args 属性,以上代码等价于:
function main(splash) local url = splash.url end
function main(splash, args) splash:go("https://www.baidu.com") splash.js_enabled = false local title = splash:evaljs("document.title") return{title= title} end
接着,重新调用 evaljs()方法执行 JavaScript 代码,此时运行结果就会抛出异常:

{ "error": 400, "info": { "line_number": 1, "error": "‘)‘ expected near char(239)", "source": "[string \"function main(splash, args)\r...\"]", "message": "[string \"function main(splash, args)\r...\"]:1: ‘)‘ expected near char(239)", "type": "LUA_INIT_ERROR" }, "description": "Error happened while executing Lua script", "type": "ScriptError" }
一般来说,不用设置此属性,默认开启即可。
resource_timeout
此属性可以设置加载的超时时间,单位是秒。如果设置为 0 或者 nil(类似 Python 中的 None ),代表不检测超时。示例:
function main(splash) splash.resource_timeout = 0.1 assert(splash:go("https://www.taobao.com")) return splash:png() end
例,这里将超时时间设置为 0.1秒。如果在 0.1 秒之内没有得到响应,就会抛出异常。 此属性适合在网页加载速度较慢的情况下设置,如果超过了某个时间无响应,则直接抛出异常并忽略即可。
images_enabled
images_enabled 属性可以设置图片是否加载,默认情况下是加载的。禁用该属性后,可以节省网络流量并提高网页加载速度。注意:禁用图片加载可能会影响 JavaScript 渲染。禁用图片后,外层 DOM 节点的高度会受影响,进而影响 DOM 节点的位置。因此,如果 JavaScript 对图片节点有操作的话,其执行就会受到影响。
注意:Splash 使用了缓存。如果一开始加载出来了网页图片,然后禁用了图片加载, 再重新加载页面,之前加载好的图片可能还会显示出来,这时直接重启 Splash 即可。
禁用图片加载的示例:
function main(splash, args) splash.images_enabled = false assert(splash:go(‘https://www.jd.com‘)) return { png=splash:png()} end
这样返回的页面截图就不会带有图片,加载速度也会快很多
plugins_enabled
plugins_enabled 属性可以控制浏览器插件(如 Flash 插件)是否开启。默认情况下,此属性是 false,表示不开启。可以使用如下代码控制其开启和关闭:
splash。plugins_enabled = true/false
scroll_position
设置 scroll_position 属性,可以控制页面上下或左右滚动。是一个比较常用的属性,示例如下:
function main(splash, args) assert(splash:go(‘https://www.taobao.com‘)) splash.scroll_position = {y=400} return {png=splash:png()} end
这样我们就可以控制页面向下滚动 400 像素值。
如果要让页面左右滚动,可以传入 x 参数,代码:
splash.scroll_position = {x=100,y=200}
Splash 对象的方法
除了前面介绍的属性外,Splash 对象还有如下方法:
go()
go() 方法用来请求某个链接,而且它可以模拟 GET 和 POST 请求,同时支持传入请求头、表单等数据,用法:
ok, reason = spalsh:go{url, baseurl=nil,headers=nil,http_method="GET",body=nil,formdata=nil}
参数说明:
url:请求的URL\
baseurl:可选参数,默认为空,表示自愿加载相对路径。
headers:可选参数,默认为空,表示请求头
http_method:可选参数,默认为空,发POST请求时的表单数据,使用Content-type 为application/json
formdata:可选参数,默认为空,POST的时候的表单数据,使用的Content-type为application/x-www-form-urlencoded、
该方法的返回结果是结果 ok 和原因 reason 的组合,如果 ok 为空,代表网页加载出现了错误,此时 reason 变量中包含了错误的原因,否则证明页面加载成功。示例:
function main(splash,args) local ok, reason = splash:go{"http://httpbin.org/post",http_method="POST",body="name=Germey"} if ok then return splash:html() end end
这里模拟了 POST 请求,并传入了 POST 的表单数据,如果成功,则返回页面的源代码。运行结果:
<html><head></head><body><pre style="word-wrap: break-word; white-space: pre-wrap;">{ "args": {}, "data": "", "files": {}, "form": { "name": "Germey" }, "headers": { "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "Accept-Encoding": "gzip, deflate", "Accept-Language": "en,*", "Connection": "close", "Content-Length": "11", "Content-Type": "application/x-www-form-urlencoded", "Host": "httpbin.org", "Origin": "null", "User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/602.1 (KHTML, like Gecko) splash Version/9.0 Safari/602.1" }, "json": null, "origin": "180.175.116.149", "url": "http://httpbin.org/post" } </pre></body></html>
成功实现POST请求并发送了表达数据。
wait()
wait() 方法可以控制页面的等待时间,使用方法:
ok, reason = splash:wait{time,cancel_on_redirect=false,cancel_on_error=true}
参数说明
time:等待的秒数
cancel_on_redirect:可选参数,默认为false,表示如果发生了重定向就停止等待,并返回重定向结果
cancel_on_error:可选参数,默认为false,表示如果发生了加载错误,就停止等待。
返回结果同样是结果 ok 和原因 reason 的组合。示例:
function main(splash) splash:go("https://www.taobao.com") splash:wait(2) return {html=splash:html()} end
该功能实访问淘宝并等待2秒,随后返回页面源代码的功能。
jsfunc()
jsfunc()方法可以直接调用 JavaScript 定义的方法,但所调用的方法需要用双中括号包围,相当于实现了 JavaScript 方法到 Lua 脚本的转换。示例:
function main(splash,args) local get_div_count =splash:jsfunc([[ function(){ var body = document.body; var divs = body.getElementsByTagName(‘div‘); return divs.length; } ]]) splash:go("https://www.baidu.com") return("There are %s DIVs"):format(get_div_count()) end 输出: Splash Response: "There are 22 DIVs"
首先,声明了一个 JavaScript 定义的方法,然后在页面加载成功后调用此方法计算出页面中 div 节点的个数。
关于 JavaScript 到 Lua 脚本的更多转换细节,参考官方文档: https://splash.readthedocs.io/en/ stable/scripting-ref.html#splash-jsfunc。
evaljs()
evaljs() 方法可以执行 JavaScript 代码并返回最后一条 JavaScript 语句的返回结果,使用方法:
result = splash:evaljs(js)
如,可以用下面的代码来获取页面标题:
local title = splash:evaljs("document.title")
runjs()
runjs() 方法可以执行 JavaScript 代码,与 evaljs()的功能类似,但是更偏向于执行某些动作或声明某些方法。例如:
function main(splash, args) splash:go("https://www.baidu.com") splash:runjs("foo = function(){return ‘bar‘}") local result = splash:evaljs("foo()") return result end 输出: bar
用 runjs()先声明一个 JavaScript 定义的方法,通过 evaljs()来调用得到的结果。
autoload()
autoload() 方法可以设置每个页面访问时自动加载的对象,使用方法:
ok, reason = splash:autoload{source_or_url, source=nil, url=nil}
参数说明:
source_or_url:JavaScript代码或者JavaScript库链接
source:JavaScript代码
url:JavaScript库链接
autoload() 方法只负责加载 JavaScript 代码或库,不执行任何操作。如果要执行操作,可以调用 evaljs() 或 runjs()方法。例:
function main(splash,args) splash:autoload([[ function get_document_title(){ return document.title; } ]]) splash:go("https://www.baidu.com") return splash:evaljs("get_document_title()") end
调用 autoload()方法声明一个 JavaScript 方法,然后通过 evaljs ()方法来执行此 JavaScript 方法。输出百度页面文本。
另外,也可以使用 autoload()方法加载某些方法库,如 jQuery,示例:
function main(splash, args) assert(splash:autoload("https://code.jquery.com/jquery-2.1.3.min.js")) assert(splash:go("https://www.taobao.com")) local version = splash:evaljs("$.fn.jquery") return ‘JQuery version:‘.. version end
输出:"JQuery version:2.1.3"
call_later()
call_later() 方法可以通过设置定时任务和延迟时间来实现任务延时执行,井且可以在执行前通过 cancel () 方法重新执行定时任务。示例:
function main(splash,args) local snapshots = {} local timer = splash:call_later(function() snapshots["a"] = splash:png() splash:wait(1.0) snapshots["b"] = splash:png() end, 0.05) splash:go("https://www.taobao.com") splash:wait(3.0) return snapshots end
这里设置了一个定时任务,0.05 秒的时候获取网页截图,然后等待 1 秒,1.05 秒时再次获取网页截图,访问的页面是淘宝,最后将截图结果返回。 结果将是:第一次截图时网页还没有加载出来,第二次网页加载成功。
http_get()
response = splash:http_get{url,headers=nil,follow_redirects=true}
参数说明:
function main(splash, args) local treat = require("treat") local response = splash:http_get("http://httpbin.org/get") return { html = treat.as_string(response.body), url=response.url, status=response.statsus } end
输出结果:
Splash Response:Object html:String(length 355) { "args": {}, "headers": { "Accept-Encoding": "gzip, deflate", "Accept-Language": "en,*", "Connection": "close", "Host": "httpbin.org", "User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/602.1 (KHTML, like Gecko) splash Version/9.0 Safari/602.1" }, "origin": "180.175.116.149", "url": "http://httpbin.org/get" }
response = splash:http_post{url,headers=nil,follow_redirects=true, body=nil}
参数说明:
url:请求URL
function main(splash, args) local treat = require("treat") local json = require("json") local response = splash:http_post{"http://httpbin.org/post", body=json.encode({name ="Germey"}), headers={["content-type"]="application/json"} } return { html=treat.as_string(response.body), url=response.url, status=response.status } end
输出:
Splash Response:Object html:String(length 535) { "args": {}, "data": "{\"name\": \"Germey\"}", "files": {}, "form": {}, "headers": { "Accept-Encoding": "gzip, deflate", "Accept-Language": "en,*", "Connection": "close", "Content-Length": "18", "Content-Type": "application/json", "Host": "httpbin.org", "User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/602.1 (KHTML, like Gecko) splash Version/9.0 Safari/602.1" }, "json": { "name": "Germey" }, "origin": "180.175.116.149", "url": "http://httpbin.org/post" }
这里成功模拟提交POST请求并发送表单数据。
set_content()
set_content() 方法用来设置页面内容,示例:
function main(splash) assert(splash:set_content("<html><body><h1>hello</h1></body></html>")) return splash:png() end
html()
function main(splash,args) splash:go("https://httpbin.org/get") return splash:html() end 输出:
<html><head></head><body><pre style="word-wrap: break-word; white-space: pre-wrap;">{ "args": {}, "headers": { "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "Accept-Encoding": "gzip, deflate", "Accept-Language": "en,*", "Connection": "close", "Host": "httpbin.org", "User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/602.1 (KHTML, like Gecko) splash Version/9.0 Safari/602.1" }, "origin": "180.175.116.149", "url": "https://httpbin.org/get" } </pre></body></html>
png()
png() 方法用来获取 PNG 格式的网页截图,示例:
function main(splash,args) splash:go("https://www.taobao.com") return splash:png() end
jpeg()
jpeg() 方法用来获取 JPEG 格式的网页截图,示例:
function main(splash,args) splash:go("https://www.taobao.com") return splash:jpeg() end
har()
har() 方法用来获取页面加载过程描述,示例:
function main(splash, args) splash:go("https://www.baidu.com") return splash:har() end
输出结果:
url()
url()方法可以获取当前正在访问的 URL,示例:
function main(splash,args) splash:go("https://www.baidu.com") return splash:url() end 输出: "https://www.baidu.com/"
get_cookies()
function main(splash, args) splash:go("https://www.baidu.com") return splash:get_cookies() end 输出:
Splash Response: Array[7] 0: Object domain: ".baidu.com" expires: "2087-01-21T09:30:08Z" httpOnly: false name: "BAIDUID" path: "/" secure: false value: "70BACA9750D3C6FBE7DA3EDC2B9E0FCE:FG=1" 1: Object domain: ".baidu.com" expires: "2087-01-21T09:30:08Z" httpOnly: false name: "BIDUPSID" path: "/" secure: false value: "70BACA9750D3C6FBE7DA3EDC2B9E0FCE" 2: Object domain: ".baidu.com" expires: "2087-01-21T09:30:08Z" httpOnly: false name: "PSTM" path: "/" secure: false value: "1546496161" 3: Object domain: ".baidu.com" httpOnly: false name: "delPer" path: "/" secure: false value: "0" 4: Object domain: "www.baidu.com" httpOnly: false name: "BD_HOME" path: "/" secure: false value: "0" 5: Object domain: ".baidu.com" httpOnly: false name: "H_PS_PSSID" path: "/" secure: false value: "1456_21095_28206_28131_26350_28139_27543" 6: Object domain: "www.baidu.com" expires: "2019-01-13T06:16:01Z" httpOnly: false name: "BD_UPN" path: "/" secure: false value: "143354"
cookies = splash:add_cookie{name,value,path=nil,domain=nil,expires=nil,httpOnly=nil,secure=nil}
各个参数代表 Cookie 的各个属性。示例:
function main(splash) splash:add_cookie{"sessionid","237465ghgfsd","/",domain="http://example.com"} splash:go("http://example.com/") return splash:html() end
function main(splash) splash:go("https://www.baidu.com") splash:clear_cookies() return splash:get_cookies() end
清除了所有的 Cookies,然后调用 get_cookies()将结果返回。 输出:Splash Response: Array[0], Cookies 被全部清空。
get_viewport_size()
function main(splash) splash:go("https://www.baidu.com/") return splash:get_viewport_size() end
输出:
Splash Response: Array[2]
0: 1024
1: 768
set_viewport_size()
set_viewport_size() 方法可以设置当前浏览器页面的大小,即宽高,用法:
splash:set_viewport_size(width,height)
例:访问一个宽度自适应的页面:
function main(splash) splash:set_viewport_size(400,700) assert(splash:go("https://cuiqingcai.com")) return splash:png() end
set_viewport_full()
set_viewport_full() 方法可以设置浏览器全屏显示,示例:
function main(splash) splash:set_viewport_full() assert(splash:go("https://www.cuiqingcai.com")) return splash:png() end
set_user_agent()
set_user_agent() 方法可以设置浏览器的 User-Agent,示例:
function main(splash) splash:set_user_agent(‘splash‘) splash:go("http://httpbin.org/get") return splash:html() end
这里将浏览器的 User-Agent 设置为 Splash. 结果:User-agent 被设置成功。
set_custom_headers()
set_custom_headers() 方法可以设置请求头,示例:
function main(splash) splash:set_custom_headers({ ["User-Agent"] = "Splash", ["Site"] = "Splash", }) splash:go("http://httpbin.org/get") return splash:html() end
这里设置了请求头中的 User-Agent 和 Site 属性,输出结果中User-Agent 和Site被更改。
select()
select()方法可以选中符合条件的第一个节点,如果有多个节点符合条件只会返回一个,其参数是 css 选择器。示例:
function main(splash) splash:go("https://www.baidu.com") input = splash:select("#kw") input:send_text(‘Splash‘) splash:wait(3) return splash:png() end
首先访问了百度,选中了搜索框,随后调用 send_text()方法填写了文本,然后返回网页截图。成功填写了输入框。
select_all()
select_all() 方法选中所有符合条件的节点,其参数是 CSS 选择器。示例:
function main(splash) local treat = require(‘treat‘) assert(splash:go("http://quotes.toscrape.com/")) assert(splash:wait(0.5)) local texts = splash:select_all(‘.quote .text‘) local results = {} for index, text in ipairs(texts) do results[index] = text.node.innerHTML end return treat.as_array(results) end
这里通过 CSS 选择器选中节点的正文内容,随后遍历了所有节点,将其中的文本获取下来。
mouse_click()
mouse_click() 方法可以模拟鼠标点击操作,传入的参数为坐标值 X 和 Y。也可以直接选中某个节点,调用此方法,示例:
function main(splash) splash:go("https://www.baidu.com") input = splash:select("#kw") input:send_text(‘Splash‘) submit = splash:select(‘#su‘) submit:mouse_click() splash:wait(3) return splash:png() end
首先选中页面的输入框,输入文本,然后选中“提交”按钮,调用了 mouse_click() 方法提交查询,然后页面等待3秒,返回截图。成功获取了查询后的页面内容,模拟了百度搜索操作。
Splash 对象的所有 API 操作:详细说明参见官方文档 https://splash.readthedocs.io/en/stable/scripting-ref.html 。
针对页面元素 API 操作:https://splash.readthedocs.io/en/stable/scripting-element-object.html。
curl http://localhost:8050/render.html?url=https://www.baidu.com
给此接口传递了一个 url 参数来指定渲染的 URL,返回结果即页面渲染后的源代码。用 Python 实现代码:
import requests url = ‘http://localhost:8050/render.html?url=https://www.baidu.com‘ response = requests.get(url) print(response.text)
这样就可以成功输出 百度页面渲染后的源代码了。
import requests url = ‘http://localhost:8050/render.html?url=https://www.taobao.com&wait=5‘ response = requests.get(url) print(response.text)
此时得到响应的时间就会变长,如这里会等待 5 秒多钟才能获取淘宝页面的源代码。
curl http://localhost:8050/render.png?url=https://www.taobao.com&wait=5&width=1000&height=700
这里传入 width 和 height 来设置页面大小为 1000 像素×700 像素。
import requests url = ‘http://localhost:8050/render.png?url=https://www.jd.com&wait=5&width=1000&height=700‘ response = requests.get(url) with open(‘taobao.png‘,‘wb‘) as f: f.write(response.content)
这样就成功获取了京东首页渲染完成后的页面截图,详细的参数设置参考官网文档: https://splash.readthedocs.io/en/stable/api.html#render-png。
curl http://localhost:8050/render.har?url=https://www.jd.com&wait=5
运回结果非常多,是一个 JSON 格式的数据,其中包含页面加载过程中的 HAR 数据
curl http://localhost:8050/render.json?url=https://httpbin.org
可以通过传人不同参数控制其返回结果。如:传人 html=1,返回结果即会增加源代码数据;传入 png=1 ,返回结果即会增加页面 PNG 截图数据;传入 har=1 ,则会获得页面 HAR 数据。例:
curl http://localhost:8050/render.json?url=https://httpbin.org&html=1
这样返回的 JSON 结果会包含网页源代码和 HAR 数据。
更多参数设置参考官方文档: https://splash.readthedocs.io/en/stable/api.html#render-json。
excute
excute() 接口是最为强大的接口。前面说了很多 Splash Lua 脚本的操作,用此接口便可实现与 Lua 本的对接。 前面的 render.html 和 render.png 等接口对于一般的 JavaScript 渲染页面是足够了,但是如果要实现一些交互操作的话,它们还是无能为力,这里就需要使用 execute 接口。 先实现一个最简单的脚本,直接返回数据:
function main(splash) return ‘hello‘ end
然后将脚本转化为 URL 编码后的字符串,拼接到 execute 接口后面,示例:
curl http://localhost:8050/execute?lua_source=function+main%28splash%29%0D%0A++return+%27hello%27%0D%0Aend
通过 lua_source 参数传递了转码后的 Lua 脚本,通过 execute 接口获取了最终脚本的执行结果。 用 Python 实现代码:
import requests from urllib.parse import quote lua = ‘‘‘ function main(splash) return ‘hello‘ end ‘‘‘ url = ‘http://localhost:8050/execute?lua_source=‘ + quote(lua) response = requests.get(url) print(response.text) 输出: hello
这里用 Python 中的三引号将 Lua 脚本包括起来,然后用 urllib.parse 模块里的 quote()方法将脚本进行 URL 转码,随后构造 Splash 请求 URL,将其作为 lua_source 参数传递,这样运行结果就会显示 Lua 脚本执行后的结果。
实例:
import requests from urllib.parse import quote lua = ‘‘‘ function main(splash,args) local treat = require("treat") local response = splash:http_get("http://httpbin.org/get") return { html = treat.as_string(response.body), url=response.url, status=response.status } end ‘‘‘ url = ‘http://localhost:8050/execute?lua_source=‘+quote(lua) #不要忘记后面的‘=’ response = requests.get(url) print(response.text)
输出:
{"html": "{\n \"args\": {}, \n \"headers\": {\n \"Accept-Encoding\": \"gzip, deflate\", \n \"Accept-Language\": \"en,*\", \n \"Connection\": \"close\", \n \"Host\": \"httpbin.org\", \n \"User-Agent\": \"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/602.1 (KHTML, like Gecko) splash Version/9.0 Safari/602.1\"\n }, \n \"origin\": \"180.165.241.94\", \n \"url\": \"http://httpbin.org/get\"\n}\n", "status": 200, "url": "http://httpbin.org/get"}
返回结果是 JSON 形式,成功获取了请求的 URL, 状态码和网页源代码。
之前所说 Lua 脚本均可以用此方式与 Python 进行对接,所有网页的动态渲染,模拟点击、表单提交、页面滑动、延时等待后的一些结果均可以自由控制,获取页面源码和截图也都ok。
Class 17 - 2 动态渲染页面爬取 — Splash
标签:Lua脚本 version 跳转 res ber b2b int 官方文档 jpeg
原文地址:https://www.cnblogs.com/Mack-Yang/p/10195835.html
