标签:font lex 架构组成 pytho crawler 数据库 网页 log 推荐
维基百科介绍:網路蜘蛛(Web spider)也叫网络爬虫(Web crawler)1,蚂蚁(ant),自动检索工具(automatic indexer),或者(在FOAF软件概念中)网络疾走(WEB scutter),是一种「自動化瀏覽網路」的程式,或者说是一种网络机器人。它们被广泛用于互联网搜索引擎或其他类似网站,以获取或更新这些网站的内容和检索方式。它们可以自动采集所有其能够访问到的页面内容,以供搜索引擎做进一步处理(分检整理下载的页面),而使得用户能更快的检索到他们需要的信息。
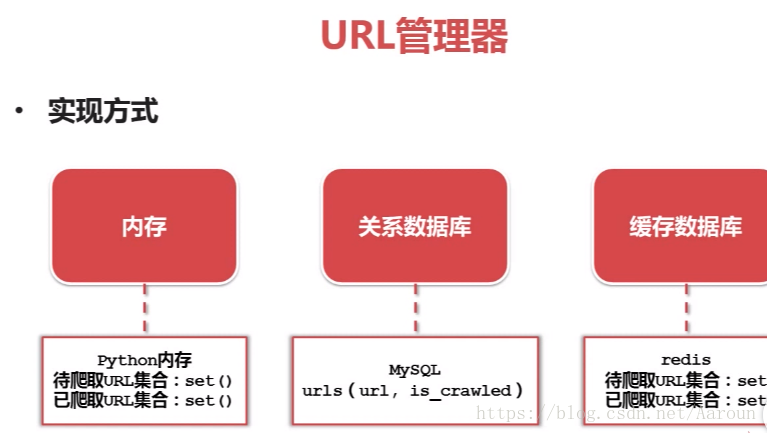
将互联网上URL对应的网页下载到本地的工具。python网页下载器有urlilib和requests。
urllib支持功能:1.支持直接url下载;2.支持向网页直接输入的数据;3.支持需要登陆网页的cookie处理;4.需要代理访问的代理处理。python 3.x 以上版本揽括了 urllib2,把urllib2 和 urllib 整合到一起,只有 import urllib,同时用urllib.request 模块 代替 urllib2。
并且引入模块变成一个,只有 import urllib
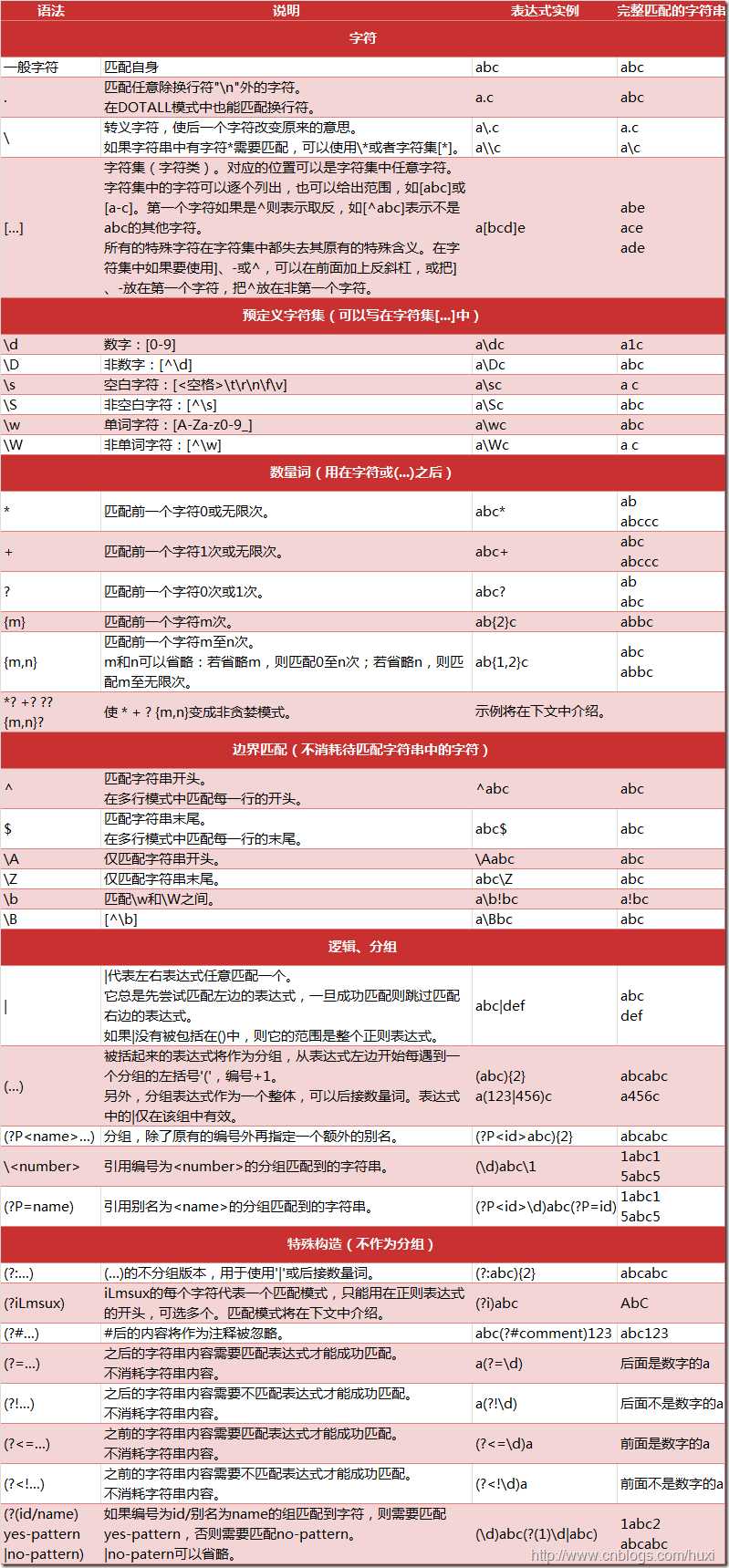
为了实现解析器,可以选择使用正则表达式、html.parser、BeautifulSoup、lxml等,这里我们选择BeautifulSoup。
其中,正则表达式基于模糊匹配,而另外三种则是基于DOM结构化解析。

总结:介绍爬虫的概念,基础知识,同时还对python架构组成做了汇总,接下来正式进入爬虫的世界!!!
标签:font lex 架构组成 pytho crawler 数据库 网页 log 推荐
原文地址:https://www.cnblogs.com/ghauoa/p/10219947.html